利用WEKA编写数据挖掘算法
WEKA是由新西兰怀卡托大学开发的开源项目。WEKA是由JAVA编写的,并且限制在GNU通用公众证书的条件下发布,可以运行在所有的操作系统中。WEKA工作平台包含能处理所有标准数据挖掘问题的方法:回归、分类、聚类、关联规则挖掘以及属性选择。作为数据挖掘爱好者自然要对WEKA的源代码进行分析并以及改进,努力写出自己的数据挖掘算法。
下面着重介绍一下如何利用WEKA编写新的数据挖掘算法:
注意:WEKA的版本有两个版本:稳定版(STABLE)和开发版(DEVELOP),不同WEKA版本与不同JDK的版本匹配,稳定版WEKA3-4的与JDK1.4.2匹配,而开发版WEKA3-5与JDK1.5匹配,WEKA3-5新加入了对数据库的数据连接。稳定版直接下载weka-src.jar文件就行了,而开发版需使用CVS连接到sourceForge下载,:pserver:cvs_anon@https://www.sodocs.net/doc/20123749.html,:/usr/local/global-cvs/ml _cvs。本文以稳定版为例。
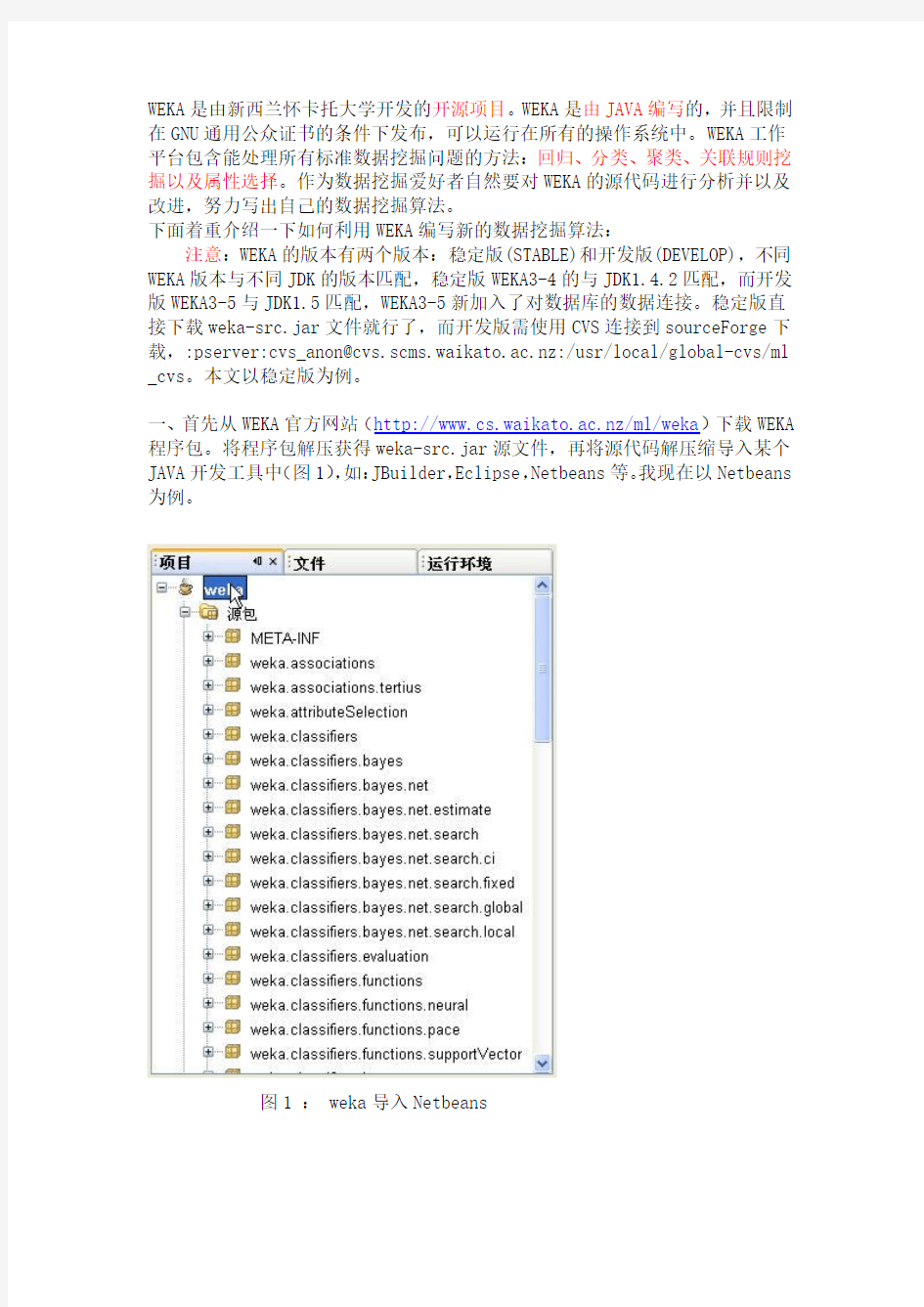
一、首先从WEKA官方网站(https://www.sodocs.net/doc/20123749.html,/ml/weka)下载WEKA 程序包。将程序包解压获得weka-src.jar源文件,再将源代码解压缩导入某个JAVA开发工具中(图1),如:JBuilder,Eclipse,Netbeans等。我现在以Netbeans 为例。
图1 : weka导入Netbeans
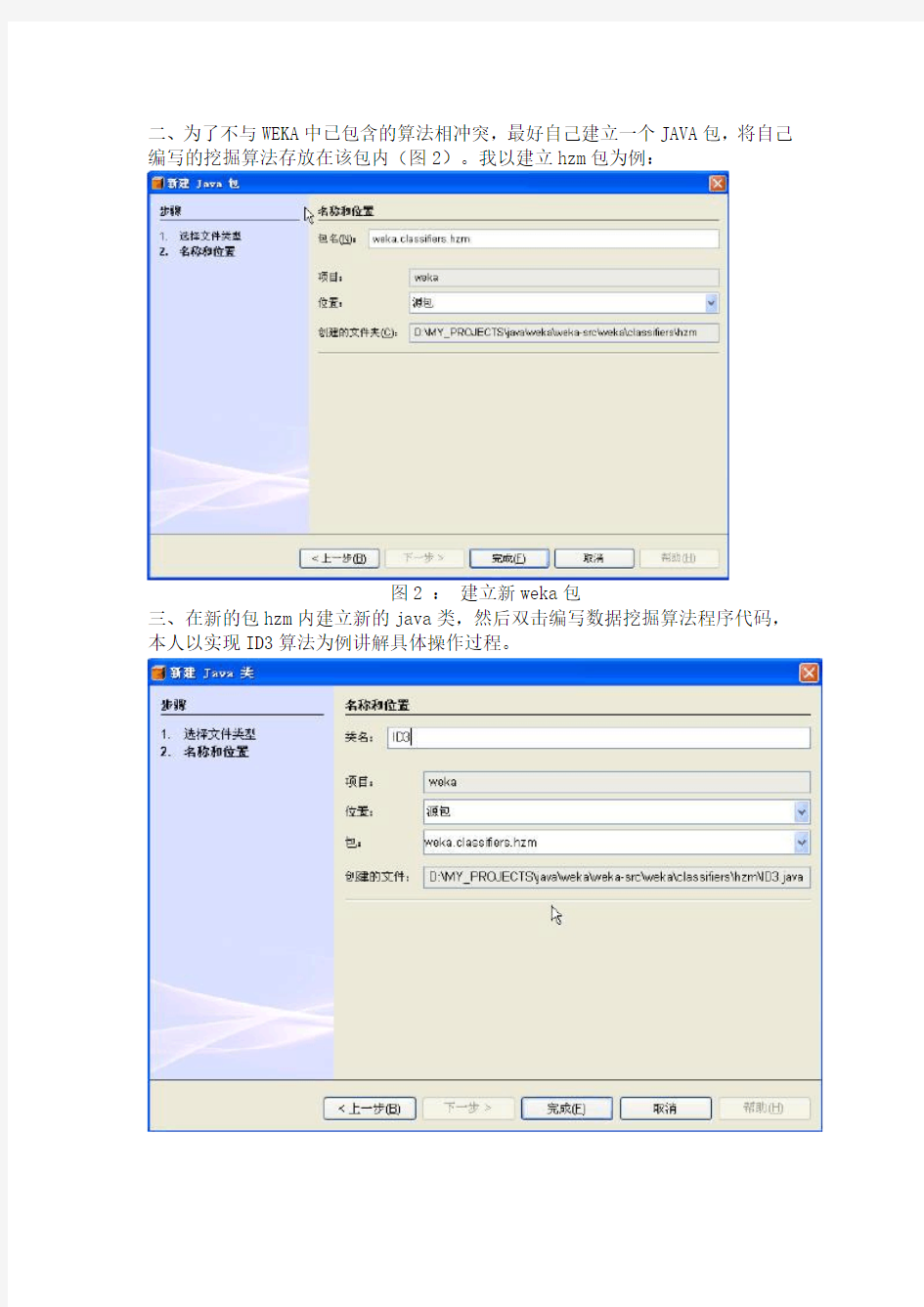
二、为了不与WEKA中已包含的算法相冲突,最好自己建立一个JAVA包,将自己编写的挖掘算法存放在该包内(图2)。我以建立hzm包为例:
图2 :建立新weka包
三、在新的包hzm内建立新的java类,然后双击编写数据挖掘算法程序代码,本人以实现ID3算法为例讲解具体操作过程。
再将weka.classifiers.trees下的id3算法复制到新建的ID3类中(这只是演示,当然最好还是自己写新的挖掘算法),修改一下类中提示的错误,保存就行了。
四、编写好新的挖掘算法并不能马上在weka中exlorer模式中看到,还要修改weka.gui包中的GenericObjectEditor.props文件。如:我刚才建立的ID3类在weka.classifiers.hzm包中,就要在GenericObjectEditor.props中的# Lists the Classifiers I want to choose from段后添加
weka.classifiers.hzm.ID3,\
五、就可以编译整个weka项目,在选择主类时选择weka.gui.GUIChooser这个类,就可以运行和调试你编写好的算法了,祝大家都能写出优秀的挖掘算法!
注意:稳定版3-4修改GenericObjectEditor.props文件即可,但开发版3-5还要多修改同目录下的GenericProertiesCreator.props文件。
大数据挖掘weka大数据分类实验报告材料
一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
大数据分析的六大工具介绍
大数据分析的六大工具介绍 2016年12月 一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分学在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设il?的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式, 相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二.第一种工具:Hadoop Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是 以一种可黑、高效、可伸缩的方式进行处理的。Hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。此外,Hadoop依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地 在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下儿个优点: ,高可黑性。Hadoop按位存储和处理数据的能力值得人们信赖。,高扩展性。Hadoop是 在可用的计?算机集簇间分配数据并完成讣算任务 的,这些集簇可以方便地扩展到数以千计的节点中。 ,高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动 态平衡,因此处理速度非常快。 ,高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败 的任务重新分配。 ,Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非 常理想的。Hadoop上的应用程序也可以使用其他语言编写,比如C++。 第二种工具:HPCC HPCC, High Performance Computing and Communications(高性能计?算与通信)的缩写° 1993年,山美国科学、工程、技术联邦协调理事会向国会提交了“重大挑战项 U:高性能计算与通信”的报告,也就是被称为HPCC计划的报告,即美国总统科学战略项U ,其U的是通过加强研究与开发解决一批重要的科学与技术挑战 问题。HPCC是美国实施信息高速公路而上实施的计?划,该计划的实施将耗资百亿 美元,其主要U标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络 传输性能,开发千兆比特网络技术,扩展研究和教育机构及网络连接能力。
Weka_数据挖掘软件使用指南
Weka 数据挖掘软件使用指南 1.Weka简介 该软件是WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过https://www.sodocs.net/doc/20123749.html,/ml/weka得到。Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以看一看Weka的接口文档。在Weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。 2.Weka启动 打开Weka主界面后会出现一个对话框,如图: 主要使用右方的四个模块,说明如下: ?Explorer:使用Weka探索数据的环境,包括获取关联项,分类预测,聚簇等; ?Experimenter:运行算法试验、管理算法方案之间的统计检验的环境; ?KnowledgeFlow:这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。它有一个优势,就是支持增量学习; ?SimpleCLI:提供了一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行Weka命令(某些情况下使用命令行功能更好一些)。 3.主要操作说明 点击进入Explorer模块开始数据探索环境。 3.1主界面 进入Explorer模式后的主界面如下:
3.1.1标签栏 主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是: ?Preprocess(数据预处理):选择和修改要处理的数据; ?Classify(分类):训练和测试关于分类或回归的学习方案; ?Cluster(聚类):从数据中学习聚类; ?Associate(关联):从数据中学习关联规则; ?Select attributes(属性选择):选择数据中最相关的属性; ?Visualize(可视化):查看数据的交互式二维图像。 3.1.2载入、编辑数据 标签栏下方是载入数据栏,功能如下: ?Open file:打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat); ?Open URL:请求一个存有数据的URL 地址; ?Open DB:从数据库中读取数据; ?Generate:从一些数据生成器中生成人造数据。 3.1.3其他界面说明 接下来的主界面中依次是Filter(筛选器),Currtent relation(当前关系)、Attributes(属性信息)、Selected attribute(选中的属性信息)以及Class(类信息),分别介绍如下: ?Filter 在预处理阶段,可以定义筛选器来以各种方式对数据进行变换。Filter 一栏用于对各种筛选器进行必要设置。Filter一栏的左边是一个Choose 按钮。点击这个按钮就可选择Weka中的某个筛选器。用鼠标左键点击这个choose左边的显示框,将出现GenericObjectEditor对话框。用鼠标右键点击将出现一个菜单,你可从中选择,要么在GenericObjectEditor对话框中显示相关属性,要么将当前的设置字符复制到剪贴板。 ?Currtent relation 显示当前打开的数据文件的基本信息:Relation(关系名),Instances(实例数)以及Attributes (属性个数)。
数据挖掘WEKA实验报告
数据挖掘-WEKA 实验报告一 姓名及学号:杨珍20131198 班级:卓越计科1301 指导老师:吴珏老师
一、实验内容 1、Weka 工具初步认识(掌握weka程序运行环境) 2、实验数据预处理。(掌握weka中数据预处理的使用) 对weka自带测试用例数据集weather.nominal.arrf文件,进行一下操作。 1)、加载数据,熟悉各按钮的功能。 2)、熟悉各过滤器的功能,使用过滤器Remove、Add对数据集进行操作。 3)、使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity 属性值为high的全部实例。 4)、使用离散化技术对数据集glass.arrf中的属性RI和Ba进行离散化(分别用等宽,等频进行离散化)。 (1)打开已经安装好的weka,界面如下,点击openfile即可打开weka自带测试用例数据集weather.nominal.arrf文件
(2)打开文件之后界面如下: (3)可对数据进行选择,可以全选,不选,反选等,还可以链接数据库,对数
据进行编辑,保存等。还可以对所有的属性进行可视化。如下图: (4)使用过滤器Remove、Add对数据集进行操作。
(5)点击此处可以增加属性。如上图,增加了一个未命名的属性unnamed.再点击下方的remove按钮即可删除该属性. (5)使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity属性值为high的全部实例。 没有去掉之前: (6)去掉其中一个属性之后:
数据挖掘工具应用及前景分析
数据挖掘工具应用及前景
介绍以下数据挖掘工具分别为: 1、 Intelligent Miner 2、 SAS Enterpreise Miner 3、SPSS Clementine 4、马克威分析系统 5、GDM Intelligent Miner 一、综述:IBM的Exterprise Miner简单易用,是理解数据挖掘的好的开始。能处理大数据量的挖掘,功能一般,可能仅满足要求.没有数据探索功能。与其他软件接口差,只能用DB2,连接DB2以外的数据库时,如Oracle, SAS, SPSS需要安装DataJoiner作为中间软件。难以发布。结果美观,但同样不好理解。 二、基本内容:一个挖掘项目可有多个发掘库组成;每个发掘库包含多个对象和函数对象: 数据:由函数使用的输入数据的名称和位置。 离散化:将记录分至明显可识别的组中的分发操作。 名称映射:映射至类别字段名的值的规范。 结果:由函数创建的结果的名称和位置。 分类:在一个项目的不同类别之间的关联层次或点阵。 值映射:映射至其它值的规范。 函数: 发掘:单个发掘函数的参数。 预处理:单个预处理函数的参数。 序列:可以在指定序列中启动的几个函数的规范。 统计:单个统计函数的参数。 统计方法和挖掘算法:单变量曲线,双变量统计,线性回归,因子分析,主变量分析,分类,分群,关联,相似序列,序列模式,预测等。 处理的数据类型:结构化数据(如:数据库表,数据库视图,平面文件) 和半结构化或非结构化数据(如:顾客信件,在线服务,传真,电子邮件,网页等) 。 架构:它采取客户/服务器(C/S)架构,并且它的API提供了C++类和方法 Intelligent Miner通过其独有的世界领先技术,例如自动生成典型数据集、发现关联、发现序列规律、概念性分类和可视化呈现,可以自动实现数据选择、数据转换、数据挖掘和结果呈现这一整套数据挖掘操作。若有必要,对结果数据集还可以重复这一过程,直至得到满意结果为止。 三、现状:现在,IBM的Intelligent Miner已形成系列,它帮助用户从企业数据资产中 识别和提炼有价值的信息。它包括分析软件工具——Intelligent Miner for Data和IBM Intelligent Miner forText ,帮助企业选取以前未知的、有效的、可行的业务知识——
weka实验报告
基于w e k a的数据分类分析实验报告1 实验目的 (1)了解决策树和朴素贝叶斯等算法的基本原理。 (2)熟练使用weka实现上述两种数据挖掘算法,并对训练出的模型进行测试和评价。 2 实验基本内容 本实验的基本内容是通过基于weka实现两种常见的数据挖掘算法(决策树和朴素贝叶斯),分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 3 算法基本原理 (1)决策树 是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。由 Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。 从ID3算法中衍生出了和CART两种算法,这两种算法在数据挖掘中都非常重要。 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。
5种数据挖掘工具分析比较
数据挖掘工具调查与研究 姓名:马蕾 学号:18082703
5种数据挖掘工具分别为: 1、 Intelligent Miner 2、 SAS Enterpreise Miner 3、SPSS Clementine 4、马克威分析系统 5、GDM Intelligent Miner 一、综述:IBM的Exterprise Miner简单易用,是理解数据挖掘的好的开始。能处理大数据量的挖掘,功能一般,可能仅满足要求.没有数据探索功能。与其他软件接口差,只能用DB2,连接DB2以外的数据库时,如Oracle, SAS, SPSS需要安装DataJoiner作为中间软件。难以发布。结果美观,但同样不好理解。 二、基本内容:一个挖掘项目可有多个发掘库组成;每个发掘库包含多个对象和函数对象: 数据:由函数使用的输入数据的名称和位置。 离散化:将记录分至明显可识别的组中的分发操作。 名称映射:映射至类别字段名的值的规范。 结果:由函数创建的结果的名称和位置。 分类:在一个项目的不同类别之间的关联层次或点阵。 值映射:映射至其它值的规范。 函数: 发掘:单个发掘函数的参数。 预处理:单个预处理函数的参数。 序列:可以在指定序列中启动的几个函数的规范。 统计:单个统计函数的参数。 统计方法和挖掘算法:单变量曲线,双变量统计,线性回归,因子分析,主变量分析,分类,分群,关联,相似序列,序列模式,预测等。 处理的数据类型:结构化数据(如:数据库表,数据库视图,平面文件) 和半结构化或非结构化数据(如:顾客信件,在线服务,传真,电子邮件,网页等) 。 架构:它采取客户/服务器(C/S)架构,并且它的API提供了C++类和方法 Intelligent Miner通过其独有的世界领先技术,例如自动生成典型数据集、发现关联、发现序列规律、概念性分类和可视化呈现,可以自动实现数据选择、数据转换、数据挖掘和结果呈现这一整套数据挖掘操作。若有必要,对结果数据集还可以重复这一过程,直至得到满意结果为止。 三、现状:现在,IBM的Intelligent Miner已形成系列,它帮助用户从企业数据资产中 识别和提炼有价值的信息。它包括分析软件工具——Intelligent Miner for Data和IBM Intelligent Miner forText ,帮助企业选取以前未知的、有效的、可行的业务知识——
基于weka的数据分类分析实验报告
基于weka的数据分类分析实验报告 姓名:陈诺言学号:0483 1实验基本内容 本实验的基本内容是通过使用weka中的三种常见分类方法(朴素贝叶斯,KNN和决策树)分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 2数据的准备及预处理 格式转换方法 原始数据是excel文件保存的xlsx格式数据,需要转换成Weka支持的arff文件格式或csv文件格式。由于Weka对arff格式的支持更好,这里我们选择arff格式作为分类器原始数据的保存格式。 转换方法:在excel中打开“”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“”文件;然后,打开Weka的Exporler,点击Open file按钮,打开刚才得到的“total_data”文件,点击“save”按钮,在弹出的对话框中,文件名输入“total_data”,文件类型选择“Arff data files (*.arff)”,这样得到的数据文件为“”。 如何建立数据训练集,校验集和测试集 数据的预处理过程中,为了在训练模型、评价模型和使用模型对数据进行预测能保证
一致性和完整性,首先要把和合并在一起,因为在生成arff文件的时候,可能会出现属性值不一样的情况,否则将为后来的测试过程带来麻烦。 通过统计数据信息,发现带有类标号的数据一共有100行,为了避免数据的过度拟合,必须把数据训练集和校验集分开,目前的拆分策略是各50行。类标号为‘female’的数据有21条,而类标号为‘male’的数据有79条,这样目前遇到的问题是,究竟如何处理仅有的21条female数据?为了能在训练分类模型时有更全面的信息,所以决定把包含21条female类标号数据和29条male类标号数据作为模型训练数据集,而剩下的另49条类标号类male的数据将全部用于校验数据集,这是因为在校验的时候,两种类标号的数据的作用区别不大,而在训练数据模型时,则更需要更全面的信息,特别是不同类标号的数据的合理比例对训练模型的质量有较大的影响。 预处理具体步骤 第一步:合并和,保存为; 第二步:在中删除多余的ID列信息; 第三步:在excel中打开“”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”; 第四步:使用UltraEdit工具把中的数据缺失部分补上全局常量‘?’; 第五步:打开Weka的Exporler,点击Open file按钮,打开刚才得到的“”文件,点击“save”按钮,在弹出的对话框中,文件名输入“total_data”,文件类型选择“Arff data files (*.arff)”,这样得到的数据文件为“”。 第六步:从文件里面剪切所有没有分类标号的数据作为预测数据集(),共26项。 第七步:把剩下含有类标号数据的文件复制一份,作为总的训练数据集。文件名称为。 第八步:从文件中剩下的数据里面选取所有分类标号为male的49行数据作为校验数据集()。 第九步:从把剩下的文件改名为。 3. 实验过程及结果截图 决策树分类 用“Explorer”打开刚才得到的“”,并切换到“Class”。点“Choose”按钮选择“tree (,这是WEKA中实现的决策树算法。
大数据处理分析的六大最好工具
大数据处理分析的六大最好工具 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分享在大数据处理分析过程中六大最好用的工具。 【编者按】我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。本文转载自中国大数据网。 CSDN推荐:欢迎免费订阅《Hadoop与大数据周刊》获取更多Hadoop技术文献、大数据技术分析、企业实战经验,生态圈发展趋势。 以下为原文: 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式,相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 Hadoop Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
数据挖掘实验报告-实验1-Weka基础操作
数据挖掘实验报告-实验1-W e k a基础操作
学生实验报告 学院:信息管理学院 课程名称:数据挖掘 教学班级: B01 姓名: 学号:
实验报告 课程名称数据挖掘教学班级B01 指导老师 学号姓名行政班级 实验项目实验一: Weka的基本操作 组员名单独立完成 实验类型■操作性实验□验证性实验□综合性实验实验地点H535 实验日期2016.09.28 1. 实验目的和要求: (1)Explorer界面的各项功能; 注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。 (2)Weka的两种数据表格编辑文件方式下的功能介绍; ①Explorer-Preprocess-edit,弹出Viewer对话框; ②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。(3)ARFF文件组成。 2.实验过程(记录实验步骤、分析实验结果) 2.1 Explorer界面的各项功能 2.1.1 初始界面示意
其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。 Experimenter:实验者选项,提供不同数值的比较,发现其中规律。 KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。 Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。 2.1.2 进入Explorer 界面功能介绍 (1)任务面板 Preprocess(数据预处理):选择和修改要处理的数据。 Classify(分类):训练和测试分类或回归模型。 Cluster(聚类):从数据中聚类。聚类分析时用的较多。 Associate(关联分析):从数据中学习关联规则。 Select Attributes(选择属性):选择数据中最相关的属性。 Visualize(可视化):查看数据的二维散布图。 (2)常用按钮
数据挖掘WEKA报告bezdekIris
第一部分概述 1.数据挖掘目的:根据已有的数据信息,寻找出鸢尾的属性之间存在怎样的关联规则。 2.数据源:UCI提供的150个实例,每个实例有5个属性。 3.数据集的属性信息: (1). sepal length in cm 萼片长度(单位:厘米)(数值型) (2). sepal width in cm 萼片宽度(单位:厘米)(数值型) (3). petal length in cm 花瓣长度(单位:厘米)(数值型) (4). petal width in cm 花瓣宽度(单位:厘米)(数值型) (5). class: 类型(分类型),取值如下 -- Iris Setosa 山鸢尾 -- Iris V ersicolor 变色鸢尾 -- Iris Virginica 维吉尼亚鸢尾 4.试验中我们采用bezdekIris.data数据集,对比UCI发布的iris.data数据集(08-Mar-1993)和bezdekIris.data数据集(14-Dec-1999),可知前者的第35个实例4.9,3.1,1.5,0.1,Iris-setosa和第38个实例4.9,3.1,1.5,0.1,Iris-setosa,后者相应的修改为:4.9,3.1,1.5,0.2,Iris-setosa和4.9,3.1,1.4,0.1,Iris-setosa。 第二部分将UCI提供的数据转化为标准的ARFF数据集 1. 将数据集处理为标准的数据集,对于原始数据,我们将其拷贝保存到TXT文档,采用UltraEdit工具打开,为其添加属性信息。如图: 2.(1)将bezdekIris.txt文件导入Microsoft Office Excel(导入时,文本类型选择文本文件),如图:
数据挖掘实验报告-实验1-Weka基础操作
学生实验报告 学院:信息管理学院 课程名称:数据挖掘 教学班级:B01 姓名: 学号: 页脚内容1
实验报告 1. 实验目的和要求: (1)Explorer界面的各项功能; 注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。(2)Weka的两种数据表格编辑文件方式下的功能介绍; ①Explorer-Preprocess-edit,弹出Viewer对话框; 页脚内容2
②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。 (3)ARFF文件组成。 2.实验过程(记录实验步骤、分析实验结果) 2.1 Explorer界面的各项功能 2.1.1 初始界面示意 其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。 Experimenter:实验者选项,提供不同数值的比较,发现其中规律。 KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。 Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。 2.1.2 进入Explorer 界面功能介绍 (1)任务面板 页脚内容3
Preprocess(数据预处理):选择和修改要处理的数据。 Classify(分类):训练和测试分类或回归模型。 Cluster(聚类):从数据中聚类。聚类分析时用的较多。 Associate(关联分析):从数据中学习关联规则。 Select Attributes(选择属性):选择数据中最相关的属性。 Visualize(可视化):查看数据的二维散布图。 (2)常用按钮 页脚内容4
数据挖掘主要工具软件简介
数据挖掘主要工具软件简介 Dataminning指一种透过数理模式来分析企业内储存的大量资料,以找出不同的客户或市场划分,分析出消费者喜好和行为的方法。前面介绍了报表软件选购指南,本篇介绍数据挖掘常用工具。 市场上的数据挖掘工具一般分为三个组成部分: a、通用型工具; b、综合/DSS/OLAP数据挖掘工具; c、快速发展的面向特定应用的工具。 通用型工具占有最大和最成熟的那部分市场。通用的数据挖掘工具不区分具体数据的含义,采用通用的挖掘算法,处理常见的数据类型,其中包括的主要工具有IBM 公司Almaden 研究中心开发的QUEST 系统,SGI 公司开发的MineSet 系统,加拿大Simon Fraser 大学开发的DBMiner 系统、SAS Enterprise Miner、IBM Intelligent Miner、Oracle Darwin、SPSS Clementine、Unica PRW等软件。通用的数据挖掘工具可以做多种模式的挖掘,挖掘什么、用什么来挖掘都由用户根据自己的应用来选择。 综合数据挖掘工具这一部分市场反映了商业对具有多功能的决策支持工具的真实和迫切的需求。商业要求该工具能提供管理报告、在线分析处理和普通结构中的数据挖掘能力。这些综合工具包括Cognos Scenario和Business Objects等。 面向特定应用工具这一部分工具正在快速发展,在这一领域的厂商设法通过提供商业方案而不是寻求方案的一种技术来区分自己和别的领域的厂商。这些工
具是纵向的、贯穿这一领域的方方面面,其常用工具有重点应用在零售业的KD1、主要应用在保险业的Option&Choices和针对欺诈行为探查开发的HNC软件。 下面简单介绍几种常用的数据挖掘工具: 1. QUEST QUEST 是IBM 公司Almaden 研究中心开发的一个多任务数据挖掘系统,目的是为新一代决策支持系统的应用开发提供高效的数据开采基本构件。系统具有如下特点: (1)提供了专门在大型数据库上进行各种开采的功能:关联规则发现、序列模式发现、时间序列聚类、决策树分类、递增式主动开采等。 (2)各种开采算法具有近似线性(O(n))计算复杂度,可适用于任意大小的数据库。 (3)算法具有找全性,即能将所有满足指定类型的模式全部寻找出来。 (4)为各种发现功能设计了相应的并行算法。 2. MineSet MineSet 是由SGI 公司和美国Standford 大学联合开发的多任务数据挖掘系统。MineSet 集成多种数据挖掘算法和可视化工具,帮助用户直观地、实时地发掘、理解大量数据背后的知识。MineSet 2.6 有如下特点: (1)MineSet 以先进的可视化显示方法闻名于世。MineSet 2.6 中使用了6 种可视化工具来表现数据和知识。对同一个挖掘结果可以用不同的可视化工具以各种形式表示,用户也可以按照个人的喜好调整最终效果, 以便更好地理解。MineSet 2.6 中的可视化工具有Splat Visualize、Scatter Visualize、Map
大数据分析的六大工具介绍
云计算大数据处理分析六大最好工具 2016年12月
一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分享在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式,相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二、第一种工具:Hadoop Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。 Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:●高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。 ●高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的, 这些集簇可以方便地扩展到数以千计的节点中。
!!!使用Weka进行数据挖掘
1.简介 数据挖掘、机器学习这些字眼,在一些人看来,是门槛很高的东西。诚然,如果做算法实现甚至算法优化,确实需要很多背景知识。但事实是,绝大多数数据挖掘工程师,不需要去做算法层面的东西。他们的精力,集中在特征提取,算法选择和参数调优上。那么,一个可以方便地提供这些功能的工具,便是十分必要的了。而weka,便是数据挖掘工具中的佼佼者。 Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化的,基于JA V A环境下开源的机器学习以及数据挖掘软件。它和它的源代码可在其官方网站下载。有趣的是,该软件的缩写WEKA也是New Zealand独有的一种鸟名,而Weka的主要开发者同时恰好来自新西兰的the University of Waikato。(本段摘自百度百科)。 Weka提供的功能有数据处理,特征选择、分类、回归、聚类、关联规则、可视化等。本文将对Weka的使用做一个简单的介绍,并通过简单的示例,使大家了解使用weka的流程。本文将仅对图形界面的操作做介绍,不涉及命令行和代码层面的东西。 2.安装 Weka的官方地址是https://www.sodocs.net/doc/20123749.html,/ml/weka/。点开左侧download栏,可以进入下载页面,里面有windows,mac os,linux等平台下的版本,我们以windows系统作为示例。目前稳定的版本是3.6。 如果本机没有安装java,可以选择带有jre的版本。下载后是一个exe的可执行文件,双击进行安装即可。 安装完毕,打开启动weka的快捷方式,如果可以看到下面的界面,那么恭喜,安装成功了。 图2.1 weka启动界面 窗口右侧共有4个应用,分别是 1)Explorer 用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。(An environment for exploring data with WEKA) 2)Experimentor 用来进行实验,对不同学习方案进行数据测试的环境。(An environment for performing experiments and conducting statistical tests between learning schemes.) 3)KnowledgeFlow 功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。另外,它支持增量学习。(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.) 4)SimpleCLI 简单的命令行界面。(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.) 3.数据格式 Weka支持很多种文件格式,包括arff、xrff、csv,甚至有libsvm的格式。其中,arff是最常用的格式,我们在这里仅介绍这一种。 Arff全称是Attribute-Relation File Format,以下是一个arff格式的文件的例子。
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.sodocs.net/doc/20123749.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.sodocs.net/doc/20123749.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
常用数据挖掘工具介绍
常用数据挖掘工具介绍 1.SAS统计分析软件 SAS统计分析软件是用于数据分析与决策支持的大型集成式模块化软件包。它由数十个专用模块构成,功能包括数据访问、数据储存及管理、应用开发、图形处理、数据分析、报告编制、运筹学方法、计量经济学与预测等。 SAS统计分析软件特点如下: 信息存储简便灵活 语言编程能力强 丰富的统计分析方法 较强的统计报表与绘图功能 友好的用户界面 宏功能 支持分布式处理 采用输出分发系统 功能强大的系统阅读器 SAS统计分析软件界面如下: SAS分析案例如下:
2.Clementine数据挖掘软件 Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。Clementine基于图形化的界面提供了大量的人工智能、统计分析的模型(神经网络,关联分析,聚类分析、因子分析等)。 Clementine软件特点如下: 支持图形化界面、菜单驱动、拖拉式的操作 提供丰富的数据挖掘模型和灵活算法 具有多模型的整合能力,使得生成的模型稳定和高效 数据挖掘流程易于管理、可再利用、可充分共享 提供模型评估方法 数据挖掘的结果可以集成于其他的应用中 满足大数据量的处理要求 能够对挖掘的过程进行监控,及时处理异常情况 具有并行处理能力 支持访问异构数据库 提供丰富的接口函数,便于二次开发 挖掘结果可以转化为主流格式的适当图形 Clementine软件界面如下:
Clementine分析案例如下: 3.R统计软件 R是属于GNU系统的一个自由、免费、开放源代码的软件,是一个用于统计计算、数据分析和统计制图的优秀工具。作为一个免费的统计软件,它有UNIX、 LINUX、MacOS和WINDOWS 等版本,均可免费下载使用。 R是一套完整的数据处理、计算和制图软件系统。其功能包括:
weka实验报告_
基于weka的数据分类分析实验报告 1 实验目的 (1)了解决策树C4.5和朴素贝叶斯等算法的基本原理。 (2)熟练使用weka实现上述两种数据挖掘算法,并对训练出的模型进行测试和评价。 2 实验基本内容 本实验的基本内容是通过基于weka实现两种常见的数据挖掘算法(决策树C4.5和朴素贝叶斯),分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 3 算法基本原理 (1)决策树C4.5 C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。C4.5由J.Ross Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。
从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。 (2)朴素贝叶斯 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。 朴素贝叶斯分类的正式定义如下: 1)设x={a_1,a_2,...,a_m}为一个待分类项,而每个a为x的一个特征属性。 2)有类别集合C={y_1,y_2,...,y_n}。 3)计算P(y_1|x),P(y_2|x),...,P(y_n|x)。 4)如果P(y_k|x)=max{P(y_1|x),P(y_2|x),...,P(y_n|x)},则x in y_k。 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:1)找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2)统计得到在各类别下各个特征属性的条件概率估计。即 P(a_1|y_1),P(a_2|y_1),...,P(a_m|y_1);P(a_1|y_2),P(a_2|y_2),...,P(a_m| y_2);...;P(a_1|y_n),P(a_2|y_n),...,P(a_m|y_n)。 3)如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: P(y_i|x)=frac{P(x|y_i)P(y_i)}{P(x)}
相关文档
- 《数据挖掘实训》weka实验报告
- weka数据挖掘实验2报告
- 大数据挖掘weka大数据分类实验报告材料
- 数据挖掘WEKA报告bezdekIris
- 数据挖掘-WEKA实验报告一
- 数据挖掘weka数据分类实验报告
- 数据挖掘WEKA实验报告
- 《数据挖掘、机器学习和Weka》教学提纲
- weka数据挖掘教程
- 数据挖掘实验weka 分析
- weka文档
- 数据挖掘工具软件介绍(weka)
- !!!使用Weka进行数据挖掘
- WEKA中文详细教程
- 数据挖掘weka数据分类实验报告
- 数据挖掘WEKA实验报告
- 数据挖掘WEKA实验报告
- 数据挖掘工具(weka教程)
- 【原创】WEKA数据挖掘课程论文
- 数据挖掘工具WEKA及其应用研究