限制性内切酶兼容粘性末端Compatible Cohesive Ends
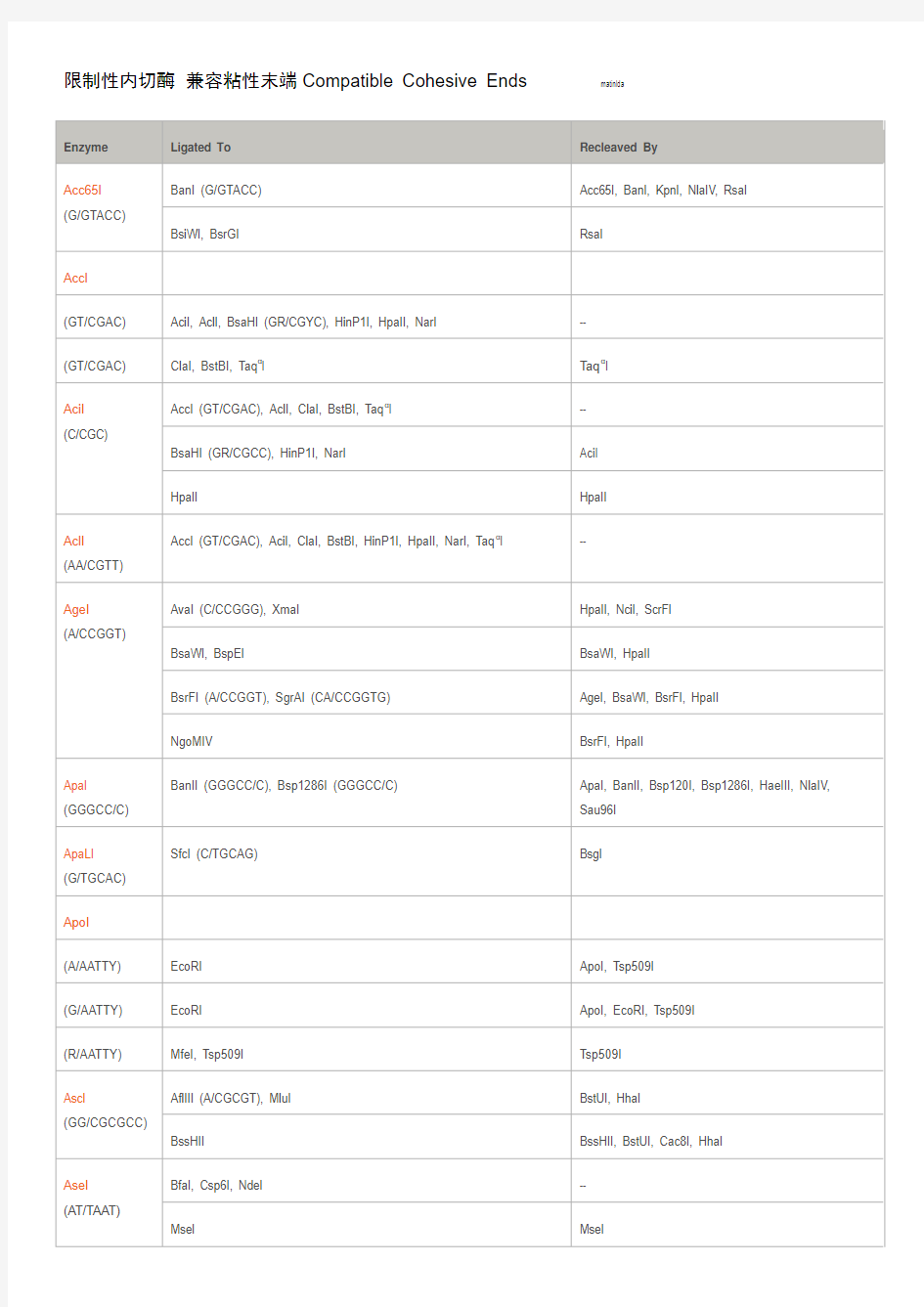

限制性内切酶兼容粘性末端Compatible Cohesive Ends matinlda
常用限制性内切酶酶切位点汇总
Acc65I识别位点AccI识别位点AciI识别位点AclI识别位点AcuI识别位点 AfeI识别位点AflII识别位点AflIII识别位点AgeI识别位点AhdI识别位点AleI识别位点AluI识别位点AlwI识别位点AlwNI识别位点ApaI识别位点ApaLI识别位点ApeKI识别位点ApoI识别位点AscI识别位点AseI识别位点AsiSI识别位点AvaI识别位点AvaII识别位点AvrII识别位点BaeI识别位点BamHI识别位点BanI识别位点BanII识别位点
BbvCI识别位点BbvI识别位点 BccI识别位点BceAI识别位点BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点 BlpI识别位点 Bme1580I识别位点BmgBI识别位点BmrI识别位点BmtI识别位点BpmI识别位点Bpu10I识别位点BpuEI识别位点BsaAI识别位点BsaBI识别位点BsaHI识别位点BsaI识别位点BsaJI识别位点BsaWI识别位点BsaXI识别位点BseRI识别位点BseYI识别位点
BsiEI 识别位点BsiHKAI 识别位点BsiWI识别位点BslI 识别位点BsmAI识别位点 BsmBI识别位点BsmFI识别位点BsmI识别位点BsoBI识别位点Bsp1286I识别位点BspCNI识别位点BspDI识别位点BspEI识别位点BspHI识别位点BspMI识别位点BspQI识别位点BsrBI识别位点BsrDI识别位点BsrFI识别位点BsrGI识别位点BsrI识别位点BssHII识别位点BssKI识别位点BssSI识别位点BstAPI识别位点BstBI识别位点BstEII识别位点BstNI识别位点
限制性内切酶
限制性核酸内切酶是一类能够识别双链DNA分子中的某种特定核苷酸序列(一般4-8bp),并在此处切割DNA双链的核酸内切酶。主要存在于原核生物,是原核生物自我保护的一种机制。它的作用包含两类,一种是对外的,限制作用,指一定类型的细菌可以通过限制性核酸内切酶的作用,破坏入侵的外源DNA,使得外源DNA对生物细胞的入侵受到限制。另一种是对内的,修饰作用,指在特定位置发生甲基化,可免遭自身限制性酶的破坏。 限制性核酸内切酶的发现是在本世纪中期,Arber等人对λ噬菌体在大肠杆菌不同菌株上的平板培养效应的研究为基础,发现了原核生物体内存在着寄主控制的限制和修饰系统。实验是:在K株或B株大肠杆菌上生长繁殖的噬菌体λ(K)或λ(B),再次感染原寄主菌体的成斑率为1,而感染新的寄主菌株的成斑率则分别为10-4和4*10-4所以说受到了限制。在 20 世纪 60 年代,噬菌体学家阐明了宿主限制和修饰现象的生化机制。该研究工作在 Me-selson 和 Yuan(1968)纯化得到了大肠杆菌 K12 的限制性内切酶时达到高峰。因为这个内切酶可以把未修饰的 DNA 切割成大的分离片段,人们认为它一定识别一个靶序列。从而提供了对 DNA 进行可控操作的前景。但不幸的是,K12 内切酶不具备人们希望的性质。虽然它确实是结合到一定的区域序列上,切割却在几千个碱基对以外“随机”发生的(Yuan 等,1980)。经过大量努力后,终于在1970 年取得了突破,人们发现了在流感嗜血杆菌(Haemophilusinfluenzae)中存在一种酶,其作用更加简单(Kelly & Smith,1970;Smith & W ilcox,1970),即这个酶可以识别双链 DNA 分子中的一个特定靶序列,并在该序列之内切断多聚核苷酸链,从而产生长度和序列一定的分离片段。突破性的进展始于 Hamilton Smith 的发现,他从嗜血流感细菌(Haemophilus influenzae)菌株 Rd中找到了一种限制性内切酶(Smith & Wilcox,1970),并阐明了它在噬菌体 T7 DNA 中切割的核苷酸序列(Kelly & Smith,1970)。这个酶现在命名为 Hind Ⅱ。嗜血流感细菌还具有另一个Ⅱ型的限制酶 Hind Ⅲ,而且含量很大。幸运的是,Hind Ⅲ不切割T7 DNA,因此 Hind Ⅱ制剂中可能混有的 Hind Ⅲ将不产生任何问题(Old 等,1975)。在发现 HindⅡ后不久,又分离到其他几个Ⅱ型的限制性内切酶,并分析了它们的性质,EcoRⅠ是其中最重要的一个(Hedgepeth 等,1972)。它们随即迅速用于最初的重组 DNA 实验中。
限制性核酸内切酶
限制性核酸内切酶 限制性核酸内切酶( restriction endonucleases ),简称限制酶,是一类能识别和切割双链 DNA 分子中的某些特定核苷酸序列的核酸水解酶,主要从细菌中分离得到。根据结构和功能特性,把限制酶分为Ⅰ、Ⅱ和Ⅲ型。Ⅰ型限制酶的切点不固定,很难形成稳定的、特异性切割末端;Ⅲ型限制酶对 DNA 链的识别序列是非对称的,不产生特异性的 DNA 片段,故基因工程实验中基本不用Ⅰ型和Ⅲ型限制酶。 Ⅱ型限制酶的主要作用是切割 DNA 分子,在 DNA 重组、构建新质粒、建立 DNA 的限制性酶切图谱、 DNA 的分子杂交、制备 DNA 的放射性探针、构建基因文库等方面起到重要作用,是基因工程重要的工具酶。 Ⅱ型限制性核酸内切酶的特点是:一般能识别和切割 4~8 个碱基对的核苷酸序列;大多数识别序列具有回文结构。 Ⅱ型限制性核酸内切酶的切割方式有三种:切割产生 5 ' 突出的粘性末端( sticky ends );切割产生 3 ' 突出的粘性末端;切割产生平头末端( blunt ends )。 Ⅰ型限制性内切酶既能催化宿主DNA的甲基化,又催化非甲基化的DNA的水解;而Ⅱ型限制性内切酶只催化非甲基化的DNA的水解。III型限制性内切酶同时具有修饰及认知切割的作用根据酶的功能特性、大小及反应时所需的辅助因子,限制性内切酶可分为两大类,即I类酶和Ⅱ酶。最早从大肠杆菌中发现的EcoK、EcoB就属于I类酶。反应过程中除需Mg2+外,还需要S-腺苷-L甲硫氨酸、ATP;在DNA分子上没有特异性的酶解片断,这是I、Ⅱ类酶之间最明显的差异。因此,I类酶作为DNA的分析工具价值不大。Ⅱ类酶有EcoR I、BamH I、Hind Ⅱ、Hind Ⅲ等。反应只需Mg2+;最重要的是在所识别的特定碱基顺序上有特异性的切点,因而DNA分子经过Ⅱ类酶作用后,可产生特异性的酶解片断,这些片断可用凝胶电泳法进行分离、鉴别。 限制酶一般不切割自身的DNA分子,只切割外源DNA。 每种限制酶特异识别专一DNA序列,并在切割位点将其准确切割。 限制酶是基因工程用来切割目的基因的酶,DNA复制不需要。 DNA复制需要的是解旋酶和DNA聚合酶。 根据限制酶的结构,辅因子的需求切位与作用方式,可将限制酶分为三种类型 第一型限制酶:同时具有修饰(modification)及认知切割(restriction)的作用;另有认知(recognize)DNA上特定碱基序列的能力,通常其切割位(cleavage site)距离认知位(recognition site)可达数千个碱基之远。例如:EcoB、EcoK。 第二型限制酶:只具有认知切割的作用,修饰作用由其他酵素进行。所认知的位置多为短的回文序列(palindrome sequence);所剪切的碱基序列通常即为所认知的序列。是遗传工程上,实用性较高的限制酶种类。例如:EcoRI、HindⅢ。 第三型限制酶:与第一型限制酶类似,同时具有修饰及认知切割的作用。可认知短的不对称序列,切割位与认知序列约距24-26个碱基对。例如:EcoPI、HinfⅢ。 甲基化(DNA methylation) DNA甲基化是最早发现的修饰途径之一,大量研究表明,DNA甲基化能引起染色质结构、DNA构象、DNA稳定性及DNA与蛋白质相互作用方式的改变,从而控制基因表达。
限制性内切酶酶切位点汇总
Acc65I识别位点 AccI识别位点 AciI识别位点 AclI识别位点 AcuI识别位点 AfeI识别位点 AflII识别位点 AflIII识别位点 AgeI识别位点 AhdI识别位点 AleI识别位点 AluI识别位点 AlwI识别位点 AlwNI识别位点 ApaI识别位点 ApaLI识别位点 ApeKI识别位点 ApoI识别位点 AscI识别位点 AseI识别位点 AsiSI识别位点 AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI识别位点 BanI识别位点 BanII识别位点
BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点 BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点 BlpI识别位点 Bme1580I识别位点 BmgBI识别位点 BmrI识别位点 BmtI识别位点 BpmI识别位点 Bpu10I识别位点 BpuEI识别位点 BsaAI识别位点 BsaBI识别位点 BsaHI识别位点 BsaI识别位点 BsaJI识别位点 BsaWI识别位点 BsaXI识别位点 BseRI识别位点 BseYI识别位点
BsiEI识别位点 BsiHKAI识别位点 BsiWI识别位点 BslI识别位点 BsmAI识别位点 BsmBI识别位点 BsmFI识别位点 BsmI识别位点 BsoBI识别位点 Bsp1286I识别位点 BspCNI识别位点BspDI识别位点 BspEI识别位点 BspHI识别位点 BspMI识别位点 BspQI识别位点 BsrBI识别位点 BsrDI识别位点 BsrFI识别位点 BsrGI识别位点 BsrI识别位点 BssHII识别位点 BssKI识别位点 BssSI识别位点 BstAPI识别位点 BstBI识别位点 BstEII识别位点 BstNI识别位点
常用限制性内切酶酶切位点保护残基
酶切位点保护碱基-PCR引物设计用于限制性内切酶 发布: 2010-05-24 20:19| 来源:生物吧| 编辑:刘浩| 查看: 161 次 本文给出了分子克隆中常用限制性内切酶的保护碱基序列,如AccI,AflIII,AscI,AvaI,BamHI,BglII,BssHII,BstEII,BstXI,ClaI,EcoRI,HaeIII,HindIII,KpnI,MluI,NcoI,NdeI,NheI,NotI,NsiI,PacI,PmeI,PstI,PvuI,SacI,SacII,SalI,ScaI,SmaI,SpeI,SphI,StuI,XbaI,XhoI,XmaI, 为什么要添加保护碱基? 在分子克隆实验中,有时我们会在待扩增的目的基因片段两端加上特定的酶切位点,用于后续的酶切和连接反应。由于直接暴露在末端的酶切位点不容易直接被限制性核酸内切酶切开,因此在设计PCR引物时,人为的在酶切位点序列的5‘端外侧添加额外的碱基序列,即保护碱基,用来提高将来酶切时的活性。 其次,在分子克隆实验中选择载体的酶切位点时,相临的两个酶切位点往往不能同时使用,因为一个位点切割后留下的碱基过少以至于影响旁边的酶切位点切割。 该如何添加保护碱基? 添加保护碱基时,最关心的应该是保护碱基的数目,而不是种类。什么样的酶切位点,添加几个保护碱基,是有数据可以参考的。 添加什么保护碱基,如果严格点,是根据两条引物的Tm值和各引物的碱基分布及GC含量。如果某条引物Tm值偏小,GC%较低,添加时多加G或C,反之亦反。 为了解不同内切酶对识别位点以外最少保护碱基数目的要求,NEB采用了一系列含识别序列的短双链寡核苷酸作为酶切底物进行实验。实验结果对于确定双酶切顺序将会有帮助(比如在多接头上切割位点很接近时),或者当切割位点靠近DNA末端时也很有用。在本表中没有列出的酶,则通常需在识别位点两端至少加上6个保护碱基,以确保酶切反应的进行。 实验方法:用γ-[32P]ATP在T4多聚核苷酸激酶的作用下标记0.1A260单位的寡核苷酸。取1μg已标记了的寡核苷酸与20单位的内切酶,在20°C条件下分别反应2小时和20小时。反应缓冲液含70mM Tris-HCl (pH 7.6), 10 mM MgCl2, 5 mMDTT及适量的NaCl或KCl(视酶的具体要求而定)。20%的PAGE(7M尿素)凝胶电泳分析,经放射自显影确定酶切百分率。 本实验采用自连接的寡核苷酸作为对照。若底物有较长的回文结构,切割效率则可能因为出现发夹结构而降低。
常用限制性内切酶酶切位点
AatII 识别位点 Acc65I 识别位点 AccI 识别位点 AciI 识别位点 AclI 识别位点 AcuI 识别位点 AfeI 识别位点 AflII 识别位点 AflIII 识别位点 AgeI 识别位点 AhdI 识别位点 AleI 识别位点 AluI 识别位点 AlwI 识别位点 AlwNI 识别位点 ApaI 识别位点 ApaLI 识别位点 ApeKI 识别位点 ApoI 识别位点 AscI 识别位点 AseI 识别位点 AsiSI 识别位点
AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI 识别位点 BanI识别位点 BanII识别位点 BbsI识别位点 BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点BcgI识别位点BciVI识别位点BclI识别位点 BfaI识别位点BfuAI识别位点BglI识别位点BglII识别位点BlpI识别位点Bme1580I识别位点BmgBI识别位点BmrI识别位点
BmtI 识别位点 BpmI 识别位点 Bpu10I 识别位点 BpuEI 识别位点 BsaAI 识别位点 BsaBI 识别位点 BsaHI 识别位点 BsaI 识别位点 BsaJI 识别位点 BsaWI 识别位点 BsaXI 识别位点 BseRI 识别位点 BseYI 识别位点 BsgI 识别位点 BsiEI 识别位点 BsiHKAI 识别位点 BsiWI 识别位点 BslI 识别位点 BsmAI 识别位点 BsmBI 识别位点 BsmFI 识别位点 BsmI 识别位点
高中生物论文解读限制性核酸内切酶应用的考点例析人教版
解读《限制性核酸内切酶应用的考点例析》 我们知道限制性核酸内切酶(限制酶)是指能识别DNA中特定碱基顺序,并在特定位点切割双链DNA的核酸内切酶。它在生物学中应用相当广泛,是基因工程中的工具酶,用来构建重组DNA分子,对于遗传性疾病的基因定位和基因诊断的研究也具有重要的应用价值。下面我们以问题的形式简要地了解它在这些方面的应用。 1。限制酶的特点 例1.下面哪项不具有限制酶识别序列的特征() A.GAATTC B.GGGGCCCC C.CTGCAG D.CTAAATC CTTAAG CCCCGGGG GACGTC GATTTAG 解析:限制酶识别的各种序具有回文对称的特点。所谓回文对称序列就是当以不同的方向分别阅读DNA的两条互补链时,DNA的两条链上的碱基序列相同。如A中的DNA分子,其中一条链从左向右阅读碱基序列是GAA TTC,另一条互补链从右向左阅读碱基序列也是GAATTC。 答案:D 例2.限制酶HindⅢ酶切DNA的识别序列是AAGCTT,限制酶HpaⅡ酶切DNA的识别序列是CCGG。假定DNA分子中A、T、G、C所含的比例相等,那么,限制酶HindⅢ酶切割双链DNA的概率是,酶切位点间的平均距离约kb(千碱基);限制酶HpaⅡ酶切割双链DNA的概率是,酶切位点间的平均距离约kb。 解析:因为限制酶识别序列具有回文对称序列的特点,这两个序列在相应的互补链上又会呈现,因此我们只需考虑DNA的一条链即可。六碱基长HindⅢ识别序列AAGCTT出现的概率是(1/4)6或1/4096,因此HindⅢ酶切位点之间的平均距离大约为4 kb。同样的道理,4碱基长的HpaⅡ酶识别序列CCGG出现的概率是(1/4)4或1/256,因此HpaⅡ酶切位点的平均距离大约为0.25 kb。 2.黏性末端与限制酶类型的关系 例3.用同一种限制酶处理会产生相同的黏性末端,但用不同的限制酶处理也可能产生相同的黏性末端。下列所示的四个黏性末端是由()种限制酶作用产生的。 解析:不同的限制酶的识别序列和切割位点不同。要判断题中的4个黏性末端是由几种限制酶作用下产生的,不光要看共有几种黏性末端,更重要的是要看作用产生这些黏性末端的限制酶的识别序列和切割位点是否相同。经过分析,题中4幅图所示的黏性末端应该分别是由4种限制酶作用产生的,这4种酶的识别序列及切割位点依次是:G↓AATTC,C↓AA TTG,G↓TTAAC,C↓TTAAG。 答案:4 3.限制酶图谱分析 例4.一线性DNA分子分别用限制酶HindⅢ和SmaⅠ消化,然后用这两种酶混合消化,得到如下片段: HindⅢ 2.5 kb,5.0 kb SmaⅠ 2.0 kb,5.5 kb HindⅢ和SmaⅠ 2.5 kb,3.0 kb,2.0 kb (1)画出此丝性DNA分子的限制酶图谱。 (2)两酶混合消化的片段再用限制酶EcoRⅠ消化,结果导致凝胶上3.0 kb的片段消失,产
限制性内切酶的一般原则和建议!
限制性内切酶的一般原则和建议! 1.如何做酶切反应? 该问题看似什么简单: DNA中加上酶,然后保温一段时间就可以了。但是在实际操作过程中,我们不断听到:切不动,装不上。问题在什么地方?能系列生产限制性内切酶的公司国际上,就那么几个,位列前 3 的是NEB, Fermentas, SibEnzyme。这些公司提供酶的品质一般都能得到保证。您可以怀疑酶的质量问题,但是更多的问题来源于模板是否合适酶切要求。下面几点对你的酶切是有帮助的。 1) 成功酶切的关键是准备好模板DNA。DNA样品中不能含有有机溶剂(会使酶变性或产生星号货性),不能含有干扰酶活性的污染物质,不能含有高浓度的EDTA (TE中的EDTA浓度较低,对Mg的浓度影响较小);同时要对DNA甲基化程度及其对酶切效率的影响要做到心中有数。 2) 选用合适的酶。根据酶切序列选用,特别注意选用甲基化对酶活性的干扰。 3) 正确使用和保存酶。酶需要保存在-20度的低温环境中,只是在需要用酶才从冰箱中取出来。运输和临时存放时需要将酶至于冰上。手拿酶管时不要接触酶管下步含酶的部分,移酶时尽可能用长TIP, 避免污染。用完后需要及时送回原处。注意:酶通常是最后加。所有4) 反应体积需要根据实验目的定,常规的酶切一般要维持在10-50ul,酶切鉴定10-20ul就可以了。 5) 模板浓度问题:浓度过高,溶液黏度过大,酶不能有效扩散,酶切效果不会好。浓度过低,也会影响酶活性。 6) 注意模板用量和反应体积的关系。对酶用量,模板用量,反应体积等要素的确定需要的是时间和经验的积累。 7) 酶切反应的各个组分加完后,需要用TIP小心混匀几次,short spin 一下就可以保温了。一般不能使用振荡器混匀。 8) 反应温度的选择。一般反应都用37度,但是 Sma I 的最适合温度是25度,37度时酶仍表现出活性,但是效率下降50%。部分从耐热菌制备的酶需要在37度以上的温度反应,如Taq I的最适温度为65度,37度保温,效率仅为前者的1/10。 9) 反应时间的选择。一般酶切鉴定30分钟就可以了。要完全酶切可以采用少量的酶长时间反应,或较高的酶量短时间处理都可以达到。在使用高酶量的时候需要注意甘油的最终浓度不要超过5%,也就是说10ul的体系,酶的用量不要超过1ul。 10) 是否和如何终止反应?酶切鉴定之类的实验不需要特殊处理。灭活的手段:加入高浓度的EDTA;65度或80度热处理20-30分钟;部分从高温菌纯化出来的内切酶由于最适的反应温度比较高,热处理灭活不一定完全,需要用苯酚/氯仿/乙醇方法纯化;电泳回收也是实验室常用除酶的手段。 2.如果遇到酶切不动或切不完全,该怎么办? 要回答这么问题常常需要了解酶活性单位是如何确定,我们多次接到这样的问题:1个单位的酶能在60分钟内切1ug的DNA,为什么我们的DNA那么少切那么长时间也不能切开或切完全?从下面几个因素去考虑: 1) 酶是否有活性:酶的活性单位通常是在60分钟酶切1ug lambda DNA或特定线状DNA所需要的酶量。鉴定酶的活性高低不是用您待切的DNA模板,也不是别的公司的酶来判定。因为不同公司酶可能是从不同系统中纯化的,虽然识别位点相同,但是酶的特性可能是有差异的。鉴定酶必须使用使用说明书上认定的酶活确定的方式,通常需要用lambda DAN做模板来判定。同时如果酶对甲基化敏感,还需要用Dcm-, Dam-的DNA.不排除由于运输或分装不当导致酶活性下降,这种情况是很少发生。我们公
限制性内切酶分类指南
30多年前,当人们在对噬菌体的宿主特异性的限制-修饰现象进行研究时,首次发现了限制性内切酶。细菌可以抵御新病毒的入侵,而这种"限制"病毒生存的办法则可归功于细胞内部可摧毁外源DNA的限制性内切酶。首批被发现的限制性内切酶包括来源于大肠杆菌的EcoR I 和EcoR II,以及来源于Heamophilus influenzae的Hind II和Hind III。这些酶可在特定位点切开DNA,产生可体外连接的基因片段。研究者很快发现内切酶是研究 限制性内切酶的主要功能是保护细菌不受噬菌体的感染,这一观点已被人们广泛接受。它们作为微生物免疫机制的一部分行使其功能。当一个没有限制性内切酶的细菌被病毒感染时,大部分病毒颗粒都能成功地进行感染。然而一个有限制性内切酶的同种细菌被成功感染的比率显著下降。出现更多的限制性内切酶将会起到多重保护作用;而一个拥有4到5种各自独立的限制性内切酶将会使细胞坚不可摧。 限制性内切酶常常伴随一到两种修饰酶(甲基化酶)出现。后者的作用是保护细胞自身的DNA 不被限制性内切酶破坏。修饰酶识别的位点与相应的限制性内切酶相同,但只甲基化每条链中的一个碱基,而不是切开DNA链。限制性内切酶识别位点处的甲基基团伸入到双螺旋的大沟中去,阻碍了限制性内切酶的作用。这样,限制性内切酶和它的"搭档"--甲基化酶一起就构成了限制-修饰(R-M)系统。在一些R-M系统中,限制性内切酶和修饰酶是两种不同的蛋白,它们各自独立行使自己的功能;而在另一些系统中,两种功能由同一种限制-修饰酶的不同亚基,或是同一亚基的不同结构域来执行。 传统上将限制性内切酶按照亚基组成、酶切位置、识别位点、辅助因子等因素划分为三大类。然而,蛋白测序的结果表明,限制性内切酶的变化多种多样,若从分子水平上分类,则应当远远不止这三种。 I型限制性内切酶是一类兼有限制性内切酶和修饰酶活性的多个亚基的蛋白复合体。它们在识别位点很远的地方任意切割DNA链。以前人们认为I型限制性内切酶很稀有,但现在通过对基因组测序的结果发现这一类酶其实很常见;尽管I型酶在生化研究中很有意义,但由于不产生确定的限制片段和明确的跑胶条带,因而不具备实用性。 II型酶在其识别位点之中或临近的确定位点特异地切开DNA链。它们产生确定的限制片段和跑胶条带,因此是三类限制性内切酶中唯一用于dna分析和克隆的一类。II型限制性内切酶由一群性状和来源都不尽相同的蛋白组成,因而任意一种限制性内切酶的氨基酸序列可能与另一种限制性内切酶的氨基酸序列截然不同。实际上,从已知的情况上看,这些酶很可能是在进化过程中各自独立产生的,而非来源于同一个祖先。 II型限制性内切酶中最普遍的是象Hha I、Hind III和Not I这样在识别序列中进行切割的酶。这一类酶是构成商业化酶的主要部分。大部分这类酶都以同二聚体的形式结合到DNA上,因而识别的是对称序列;但有极少的酶作为单聚体结合到DNA上,识别非对称序列。一些酶识别连续的序列(如EcoR I识别GAATTC);而另一些识别不连续的序列(如Bgl I识别GCCNNNNNGGC)。限制性内切酶的切割后产生一个3"羟基端和一个5"磷酸基团。它们的活性要求镁离子,而相应的修饰酶则需要S-甲硫氨酸腺苷的存在。这些酶一般都比较小,亚基一般都在200-300个氨基酸左右。 另一种比较常见的酶是所谓的IIS型酶,比如Fok I和Alw I,它们在识别位点之外切开DNA。
常用限制性内切酶酶切位点汇总
ApaI识别位点Acc65I识别位点 ApaLI识别位点AccI识别位点 ApeKI识别位点AciI识别位点 ApoI识别位点AclI识别位点 AscI识别位点AcuI识别位点 AseI识别位点AfeI识别位点 AsiSI识别位点AflII识别位点 AvaI识别位点AflIII识别位点 AvaII识别位点AgeI识别位点 AvrII识别位点AhdI识别位点 BaeI识别位点AleI识别位点 BamHI识别位点AluI识别位点 BanI识别位点AlwI识别位点 BanII识别位点AlwNI识别位点
BmrI识别位点BbvCI识别位点 BmtI识别位点BbvI识别位点 BpmI识别位点BccI识别位点 Bpu10I识别位点BceAI识别位点 BpuEI识别位点BcgI识别位点 BsaAI识别位点BciVI识别位点 BsaBI识别位点BclI识别位点 BsaHI识别位点BfaI识别位点 BsaI识别位点BfuAI识别位点 BsaJI识别位点BglI识别位点 BsaWI识别位点BglII识别位点 BsaXI识别位点BlpI识别位点 BseRI识别位点Bme1580I识别位点 BseYI识别位点BmgBI识别位点
BspMI识别位点BsiEI识别位点 BspQI识别位点BsiHKAI识别位点 BsrBI识别位点BsiWI识别位点 BsrDI识别位点BslI识别位点 BsrFI识别位点BsmAI识别位点 BsrGI识别位点BsmBI识别位点 BsrI识别位点BsmFI识别位点 BssHII识别位点BsmI识别位点 BssKI识别位点BsoBI识别位点 BssSI识别位点Bsp1286I识别位点 BstAPI识别位点BspCNI识别位点 BstBI识别位点BspDI识别位点 BstEII识别位点BspEI识别位点 BstNI识别位点BspHI识别位点
AgeI限制性内切酶使用说明书
H om e ?P roducts ?AgeI AgeI Product Information FAQs Protocols Other Tools & Resources Related Products Description Properties and Usage Quality Control This enzyme has transitioned to an improved new buffer system. Visit https://www.sodocs.net/doc/245161960.html, for further details. The new and current Double Digest Finder and current Activity/Performance Chart for the CutSmart buffer system are available. The previous version of the Double Digest Finder , as well as the previous Version of Activity/Performance Chart that use the former buffer system, are still available for your convenience. AgeI has High Fidelity (HF) and RE-Mix Master Mix versions available. Isoschizomers Catalog # Size Concentration Price Qty R0552S 300 units 5,000 units/ml $67.001R0552L 1,500 units 5,000 units/ml $268.001 Categories: Restriction Endonucleases: A Applications: Restriction Enzyme Digestion Description AgeI has a High Fidelity v ersion AgeI-HF? (NEB #R3552). High Fidelity (HF ?) Restriction Enzymes hav e 100% activ ity in CutSmart ? Buffer; single-buffer simplicity means more straightforward and streamlined sample processing. HF enzymes also exhibit dramatically reduced star activ ity. HF enzymes are all Time-Sav er qualified and can therefore cut substrate DNA in 5-15 minutes with the flexibility to digest ov ernight without degradation to DNA. Engineered with performance in mind, HF restriction enzymes are fully activ e under a broader range of conditions, minimizing off-target products, while offering flexibility in experimental design. Product Source An E. coli strain that carries the AgeI gene from Ruegeria gelatinovora (ATCC 25655). Reagents Supplied The following reagents are supplied with this product: Properties and Usage Unit Definition One unit is defined as the amount of enzyme required to digest 1 μg of λ DNA in 1 hour at 37°C in a total reaction of 50 μl. NEBuffer 1.110X
限制性核酸内切酶与核酸内切酶、外切酶
限制性核酸内切酶百科名片
其3′→5′外切酶活性使双链DNA分子产生出单链区,经过这种修饰的DNA 再配合使用Klenow酶,同时加进带放射性同位素的核苷酸,便可以制备特异性的放射性探针。 核酸内切酶 核酸内切酶(endonuclease)在核酸水解酶中,为可水解分子链内部磷酸二酯键生成寡核苷酸的酶,与核酸外切酶相对应。从对底物的特异性来看,可分为DNaseⅠ、DNaseⅡ等仅分解DNA的酶;脾脏RNase、RNaseT1等仅分解RNA的酶。如链孢霉(Neurospora)的核酸酶就是既分解DNA又分解RNA的酶。一般来说,大都不具碱基特异性,但也有诸如脾脏RNase、RNaseT1等或限制性内切酶那种能够识别并切断特定的碱基或碱基序列的酶。[1] 寡核苷酸,是一类只有20个以下碱基对的短链核苷酸的总称(包括脱氧核糖核 酸DNA或核糖核酸RNA内的核苷酸),寡核苷酸可以很容易地和它们的互补对链接,所以常用来作为探针确定DNA或RNA的结构,经常用于基因芯片、电泳、荧光原位杂交等过程中。 RNA聚合酶 科技名词定义 中文名称:RNA聚合酶 英文名称:RNA polymerase 定义1:以一条DNA链或RNA链为模板催化由核苷-5′-三磷酸合成RNA的酶。 所属学科:生物化学与分子生物学(一级学科);酶(二级学科) 定义2:以一条DNA链或RNA链为模板催化由核苷-5′-三磷酸合成RNA的酶。 所属学科:细胞生物学(一级学科);细胞遗传(二级学科)
定义3:以DNA或RNA为模板合成RNA的酶。 所属学科:遗传学(一级学科);分子遗传学(二级学科) 本内容由全国科学技术名词审定委员会审定公布 RNA聚合酶(RNA polymerase):以一条DNA链或RNA为模板催化由核苷-5′-三磷酸合成RNA的酶。是催化以DNA为模板(template)、三磷酸核糖核苷为底物、通过磷酸二酯键而聚合的合成RNA的酶。因为在细胞内与基因DNA的遗传信息转录为RNA有关,所以也称转录酶。 逆转录酶 科技名词定义 中文名称:逆转录酶 英文名称:reverse transcriptase 其他名称:依赖于RNA的DNA聚合酶(RNA-dependent DNA polymerase,RNA指导的DNA聚合酶 (RNA-directed DNA polymerase) 定义:编号:EC 2.7.7.49。以RNA为模板催化脱氧核苷-5′-三磷酸合成DNA的酶。在逆转录病毒及其他某些病毒中发现有此类酶。 所属学科:生物化学与分子生物学(一级学科);酶(二级学科) 本内容由全国科学技术名词审定委员会审定公布
常见限制性内切酶识别序列(酶切位点)
The Type II restriction systems typically contain individual restriction enzymes and modification enzymes encoded by separate genes. The Type II restriction enzymes typically recognize specific DNA sequences and cleave at constant positions at or close to that sequence to produce 5-phosphates and 3-hydroxyls. Usually they require Mg 2+ ions as a cofactor, although some have more exotic requirements. The methyltransferases usually recognize the same sequence although some are more promiscuous. Three types of DNA methyltransferases have been found as part of Type II R-M systems forming either C5-methylcytosine, N4-methylcytosine or N6-methyladenine. ApaI (类型:Type II restriction enzyme )识别序列:5'GGGCC^C 3' BamHI(类型:Type II restriction enzyme )识别序列:5' G^GATCC 3' BglII (类型:Type II restriction enzyme )识别序列:5' A^GATCT 3' EcoRI (类型:Type II restriction enzyme )识别序列:5' G^AATTC 3' HindIII (类型:Type II restriction enzyme )识别序列:5' A^AGCTT 3' KpnI (类型:Type II restriction enzyme )识别序列:5' GGTAC^C 3' NcoI (类型:Type II restriction enzyme )识别序列:5' C^CATGG 3' NdeI (类型:Type II restriction enzyme )识别序列:5' CA^TATG 3' NheI (类型:Type II restriction enzyme )识别序列:5' G^CTAGC 3' NotI (类型:Type II restriction enzyme )识别序列:5' GC^GGCCGC 3' SacI (类型:Type II restriction enzyme )识别序列:5' GAGCT^C 3' SalI (类型:Type II restriction enzyme )识别序列:5' G^TCGAC 3' SphI (类型:Type II restriction enzyme )识别序列:5' GCATG^C 3' XbaI (类型:Type II restriction enzyme )识别序列:5' T^CTAGA 3' XhoI (类型:Type II restriction enzyme )识别序列:5' C^TCGAG 3' 当然,上面总结的这些肯定不全,要查找更多内切酶的识别序列,你还可以选择下面几种方法: 1. 查你所使用的内切酶的公司的目录或者网站;NEB网站上提供的识别序列图表下载 2. 用软件如:Primer Premier5.0或Bioedit等,这些软件均提供了内切酶识别序列的信息;
DNA限制性内切酶——酶切Buffer组分及其活性
DNA限制性内切酶——酶切Buffer组分及其活性 TaKaRa公司,为了方便限制酶的统一使用,采用了通用缓冲液(Universal Buffer) 测定限制酶活性的体系(5种通用缓冲液中,用标注的),以此时的活性值作为100%。并把在其它通用缓冲液中的相对活性表示如下表。有( ) 标记的是易受Star活性影响的缓冲液,为了避免Star活性的影响,希望尽量使用或标注的缓冲液。每种限制酶都有其自身的基本缓冲液(Basal Buffer),其中AccⅢ、BalⅠ、BcnⅠ、BglⅠ、Bpu1102Ⅰ、Cfr10Ⅰ、Eam1105Ⅰ、Eco52Ⅰ、NruⅠ、Psh BⅠ、Sna BⅠ、SspⅠ、TaqⅠ、VpaK11B Ⅰ(共14种)由于没有十分合适的通用缓冲液,只能使用基本缓冲液(Basal Buffer)。各种限制酶的基本缓冲液组成不同,相互之间不能通用。各种限制酶在基本缓冲液中的相对活性也被列于下表,供参考。 限制酶在各种缓冲液中的相对活性 附带·活性测定用Buffer 推荐使用的Buffer
*1+0.01%BSA→100%:Afl II, Aor13H I, Eco O65 I, Fok I, Hin1 I, Mun I, Nco I, Pvu I, Sse8387 I, Xba I *2 +0.01%BSA+0.01%Triton X-100→100%:Not I *3不加BSA
按Universal Buffer分类的限制酶
各Universal Buffer的组成 ■ 使用注意事项 10×Buffer都为10倍浓度的缓冲液。此外,10×T溶液中不含BSA,在使用时将BSA添加进去,使最终浓度为0.01%,有些限制酶(带有*1或*2标记)的反应体系中需加BSA或Triton X-100,添附的溶液是10倍浓度(0.1%) 的液体,使用时,请在反应体系中添加1/10量进行反应。 ■ 保存 -20℃ 反应停止液组份表 (10 × Loading Buffer) 1%SDS 60%Glycerol 0.05%Bromophenol Blue ■ 使用方法 本公司的酶包装中全部附带有反应停止液。使用时请添加反应液量的1/10,即可停止反应,进行电泳。-20℃保存时,会出现SDS 沉淀,请于温水浴中溶解后使用。在室温下保存时,SDS有时也会出现沉淀,此时同样请于温水浴中将其溶解后使用。 ■ 保存 开封后室温保存。
常用限制性内切酶酶切位点总结
常用限制性内切酶酶切位点总结
————————————————————————————————作者:————————————————————————————————日期:
Acc65I识别位点 AccI识别位点 AciI识别位点 AclI识别位点 AcuI识别位点 AfeI识别位点 AflII识别位点 AflIII识别位点 AgeI识别位点 AhdI识别位点 AleI识别位点 AluI识别位点 AlwI识别位点 AlwNI识别位点 ApaI识别位点 ApaLI识别位点 ApeKI识别位点 ApoI识别位点 AscI识别位点 AseI识别位点 AsiSI识别位点 AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI识别位点 BanI识别位点 BanII识别位点
BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点 BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点 BlpI识别位点 Bme1580I识别位点 BmgBI识别位点 BmrI识别位点 BmtI识别位点 BpmI识别位点 Bpu10I识别位点 BpuEI识别位点 BsaAI识别位点 BsaBI识别位点 BsaHI识别位点 BsaI识别位点 BsaJI识别位点 BsaWI识别位点 BsaXI识别位点 BseRI识别位点 BseYI识别位点
BsiEI识别位点 BsiHKAI识别位点 BsiWI识别位点 BslI识别位点 BsmAI识别位点 BsmBI识别位点 BsmFI识别位点 BsmI识别位点 BsoBI识别位点 Bsp1286I识别位点 BspCNI识别位点BspDI识别位点 BspEI识别位点 BspHI识别位点 BspMI识别位点 BspQI识别位点 BsrBI识别位点 BsrDI识别位点 BsrFI识别位点 BsrGI识别位点 BsrI识别位点 BssHII识别位点 BssKI识别位点 BssSI识别位点 BstAPI识别位点 BstBI识别位点 BstEII识别位点 BstNI识别位点
限制性内切酶
限制性内切酶 1,发现 限制性内切酶能保护细菌不受噬菌体的感染,行使微生物免疫功能,缺乏限制性内切酶的大肠杆菌极易被噬菌体感染,但是如果拥有限制性内切酶,被感染的几率就会降低。 限制性内切酶在原核生物中普遍存在,所有自由生存的细菌和古细菌几乎都能编码限制性内切酶。 2,限制-修饰(R-M)系统 大多数限制性内切酶常常伴随有一两种修饰酶(DNA甲基化酶),从而保护细胞自身的DNA不被限制性内切酶破坏。 修饰酶识别的位点与相应的限制性内切酶相同,但它们的作用是甲基化每条链中的一个碱基,而不是切开DNA链。甲基化所形成的甲基基团能够伸入到限制性内切酶识别位点的双螺旋的大沟中,阻碍限制性内切酶发挥作用,即组成R-M系统。 在R-M系统中,有些限制性内切酶和修饰酶是两种不同的蛋白,独立行使自己的功能,有些本身就是一种大的限制-修饰复合酶,由不同的亚基或同一亚基的不同结构域分别执行自己的功能。 3,分类 最常用的II型限制性内切酶,能够在识别序列内部或附近特异性的切开DNA链,产生特性的片段和凝胶电泳条带,是唯一一类能用于DNA分析和克隆的限制性内切酶。 限制性内切酶切割后产生一个3-羟基和5-磷酸基,只有当镁离子存在时才具有活性,而相应的修饰酶则需要S-腺苷甲硫氨酸的存在。 备注: NEBuffer: Tris-HCl , MgCl, DTT(二硫苏糖醇,强还原剂) 星号活性:在非理想条件下,内切酶切割与识别位点相似但不完全相同的序列,称为星号活性。使用高保真内切酶,即经过基因工程改造降低了星号活性。 同裂酶:识别序列相同的限制性内切酶即为同裂酶,第一个被发现的内切酶称为原酶,后来发现的识别序列相同的内切酶称为原酶的内裂酶。 4,甲基化 (1)原核生物甲基化 在原核生物中,DNA甲基化酶作为限制修饰系统的一个组成部分广泛存在,作用是保护宿主菌不被相应的限制性内切酶切割。 Dam甲基化酶:G m ATC Dcm甲基化酶:C m CAGG和C m CTGG 例如,从dam+ E.coli 中分离的质粒DNA则不能被识别序列为GA TC的限制性内切酶所切割,但是被Dam甲基化阻断的限制性位点可以通过克隆方法去甲基化,及将DNA转入至dam-的菌种中进行增殖。 (2)真核生物甲基化 CpG甲基化酶:m CG
相关文档
- 常见分子实验限制性内切酶酶切位点大全
- 酶切
- 常用限制性内切酶酶切位点汇总
- Thermo Scientific限制性内切酶一览表
- 限制性内切酶一览表
- 限制性内切酶酶切位点汇总
- 常用限制性内切酶酶切位点汇总
- 常用限制性内切酶酶切位点汇总
- 常用限制性内切酶酶切位点汇总
- 常用限制性内切酶酶切位点汇总
- 限制性内切酶的一般原则和建议
- 常用限制性内切酶酶切位点
- 限制性内切酶一览表
- 常用限制性内切酶的识别序列和同裂酶
- 限制性内切酶一览表
- 限制性内切酶的一般原则和建议!
- 2基因工程-工具酶汇总
- 常用限制性内切酶酶切位点汇总
- 限制性内切酶酶切位点汇总(不收费)
- 常见限制性内切酶识别序列(酶切位点)