在命令行中编译C++的方法

打造Windows下的C/C++命令行编译环境
来源:雷超KrisRay的日志
在Linux下,Kris是倾向于在终端中使用gcc和g++来编译C/C++的,在Windows下相信很多人都是选择臃肿的Visual Studio,我亦不免如此。但是,我希望在Windows下也能像Linux下一样简洁编程,于是开始了我的Windows下的C/C++命令行编译环境打造之路。
几乎没有人会否认集成开发环境(IDE)(例如,Visual Studio,NetBeans,Eclipse)所提供的能使编程工作变得相当简单的诸多功能。但,还是说说命令行编译的好处吧。
1、偏爱最简单的生成
2、希望揭开IDE 处理源代码文件的方法的秘密
3、深入了解计算机语言并得到扩展
事实上,使用命令行工具编译的感觉将证明很有帮助。
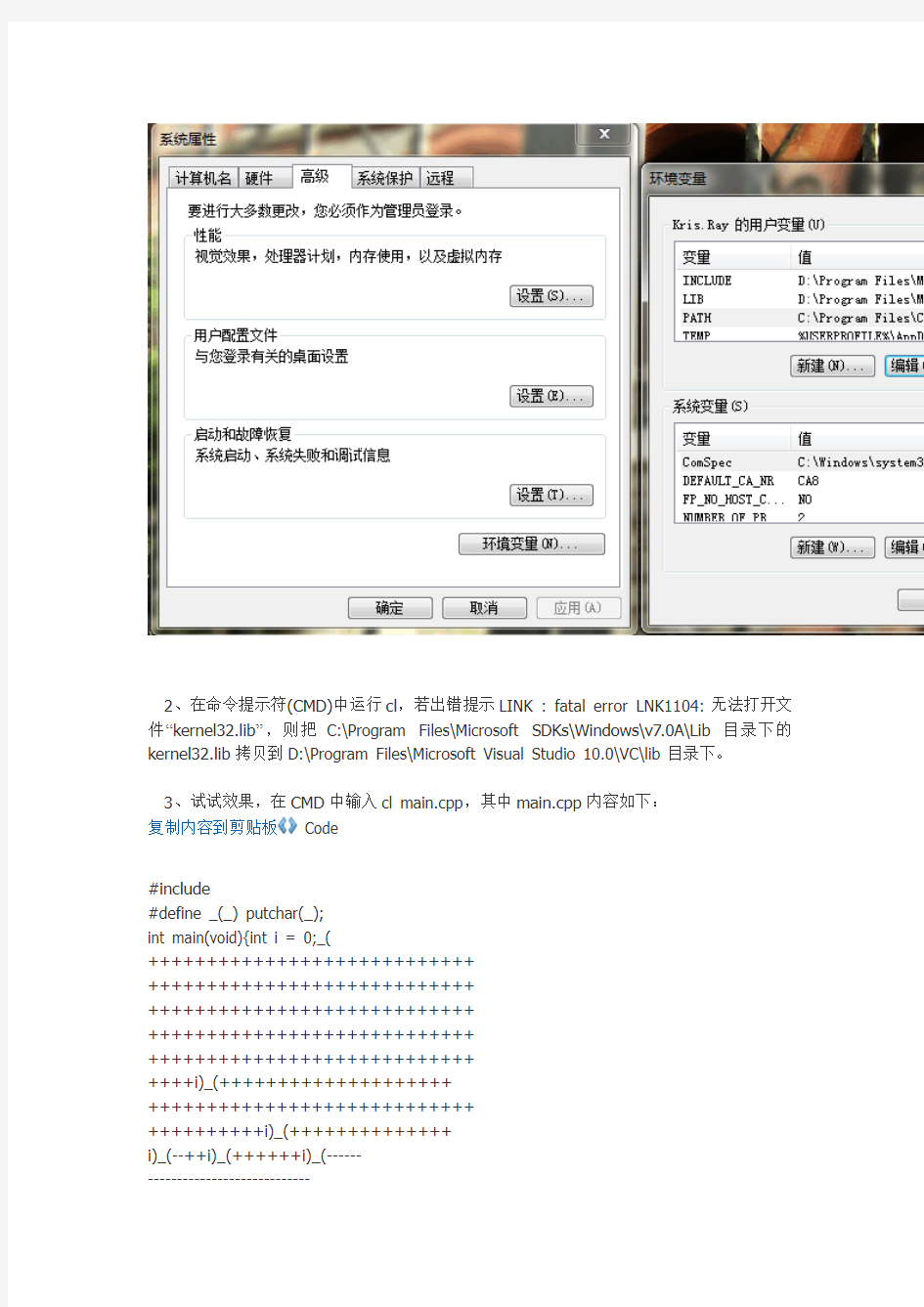
怎么打造Windows下的C/C++命令行编译环境呢?使用Cygwin在Windows上模拟Linux 环境,然后利用gcc/g++,显然这也是复杂的折腾。既然我已经装了Visual Studio,那么我应该好好利用其cl编译器。OK,步骤记录如下(这里说明一下,我的环境是Windows 7 + Visual Studio 2010,其中VS 2010安装位置是D盘):
1、修改环境变量
在系统属性-高级-环境变量-用户变量中:
编辑PATH增加cl编译器的路径D:\Program Files\Microsoft Visual Studio 10.0\VC\bin 以及MSPDB60.DLL的路径D:\Program Files\Microsoft Visual Studio 10.0\Common7\IDE,用分号分隔。
新建变量INCLUDE:D:\Program Files\Microsoft Visual Studio 10.0\VC\include
新建变量LIB:D:\Program Files\Microsoft Visual Studio 10.0\VC\lib
2、在命令提示符(CMD)中运行cl,若出错提示LINK : fatal error LNK1104: 无法打开文件“kernel32.lib”,则把C:\Program Files\Microsoft SDKs\Windows\v7.0A\Lib目录下的kernel32.lib拷贝到D:\Program Files\Microsoft Visual Studio 10.0\VC\lib目录下。
3、试试效果,在CMD中输入cl main.cpp,其中main.cpp内容如下:
复制内容到剪贴板Code
#include
#define _(_) putchar(_);
int main(void){int i = 0;_(
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++i)_(++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++i)_(++++++++++++++
i)_(--++i)_(++++++i)_(------
----------------------------
----------------------------
----------------------------
----------------------------
----------------i)_(--------
----------------i)_(++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++++
++++++++++++++++++++++++++i)
_(----------------i)_(++++++
i)_(------------i)_(--------
--------i)_(----------------
----------------------------
----------------------------
----------------------------
----------------------------
------i)_(------------------
----------------------------
i)return i;}
编译结束之后,运行main.exe结果会是什么呢?Oops,传说中的Hello World 哎!
附录cl编译器命令的简单用法:
引用内容
(1) cl 直接生成exe文件
多文件编译
在main,cpp 函数中,包含mysum.cpp , mycheng.cpp文件
mysum.cpp 中包含mysum函数的方法
mycheng.cpp 中包含mycheng函数的方法
执行
cl main.cpp
生成main.exe可执行文件
///////////////////////////////////////////////////////////////////////////////////////////////////////
////main.cpp
#include
#include "mysum.cpp"
#include "mycheng.cpp"
void main()
{
double dresult=mysum(3.6 , 3.4);
cout<<"3.6 + 3.4 ="< cout<<"3x6="< } /////////////////////////////////////////////////////////////////////////////////////////////////////// / ////mysum.cpp double mysum(double dx,double dy) { double dsum=dx+dy; return dsum; } /////////////////////////////////////////////////////////////////////////////////////////////////////// ////mycheng.cpp double dcheng() { return 3.0*6.0; } /////////////////////////////////////////////////////////////////////////////////////////////////////// / Result: 3.6 + 3.4 =7 3x6=18 (2) cl 生成obj文件,再link obj 文件,间接生成exe文件 将函数声明和函数的实现分开,头文件的作用就是函数,类,变量的声明. 如果在.h文件中加入了函数的实现部分,那么就破坏了文件的声明作用. 如果这样,那么编译文件时,文件的逻辑顺序混乱. //mysum.h double mysum(double dx,double dy); //mycheng.h double dcheng(); //mysum.cpp double mysum(double dx,double dy) { double dsum=dx+dy; return dsum; } //mycheng.cpp double dcheng() { return 3.0*6.0; } //main.cpp #include #include "mysum.h" #include "mycheng.h" void main() { double dresult=mysum(3.6 , 3.4); cout<<"3.6 + 3.4 ="< cout<<"3x6="< } ////////////////////////////////////// 输入命令顺序 cl /c main.cpp //生成main.obj cl /c mysum.cpp //生成mysum.obj cl /c mycheng.cpp //生成mycheng.obj link mycheng.obj mysum.obj main.obj //生成mycheng.exe //大家可以看到,采用任何一种files.obj的文件顺序,都可以生成//exe 文件,而生成的exe文件名就是第一个obj文件名。 /////////////////////////////////////////////////////////////////////////////////////////////////////// ////////////////////////////////////// 通过第二部分,头文件,源文件怎样组织在一起的困惑就解开了。头文件只起到一个声明作用,就像变量声明一样。Link 将files.obj文件链接在一起,就在链接的过程中,就把头文件,源文件的obj组织起来了。 第六章预处理命令 6.1 选择题 1.下面叙述中正确的是()。 A. 带参数的宏定义中参数是没有类型的 B. 宏展开将占用程序的运行时间 C. 宏定义命令是C语言中的一种特殊语句 D. 使用#include命令包含的头文件必须以“.h”为后缀 2.下面叙述中正确的是()。 A. 宏定义是C语句,所以要在行末加分号 B. 可以使用#undef命令来终止宏定义的作用域 C. 在进行宏定义时,宏定义不能层层嵌套 D. 对程序中用双引号括起来的字符串内的字符,与宏名相同的要进行置换 3.在“文件包含”预处理语句中,当#include后面的文件名用双引号括起时,寻找被包含文件的方式为()。 A. 直接按系统设定的标准方式搜索目录 B. 先在源程序所在目录搜索,若找不到,再按系统设定的标准方式搜索 C. 仅仅搜索源程序所在目录 D. 仅仅搜索当前目录 4.下面叙述中不正确的是()。 A. 函数调用时,先求出实参表达式,然后带入形参。而使用带参的宏只是进行简单的 字符替换 B. 函数调用是在程序运行时处理的,分配临时的内存单元。而宏展开则是在编译时进 行的,在展开时也要分配内存单元,进行值传递 C. 对于函数中的实参和形参都要定义类型,二者的类型要求一致,而宏不存在类型问 题,宏没有类型 D. 调用函数只可得到一个返回值,而用宏可以设法得到几个结果 5.下面叙述中不正确的是()。 A. 使用宏的次数较多时,宏展开后源程序长度增长。而函数调用不会使源程序变长 B. 函数调用是在程序运行时处理的,分配临时的内存单元。而宏展开则是在编译时进 行的,在展开时不分配内存单元,不进行值传递 C. 宏替换占用编译时间 D. 函数调用占用编译时间 6.下面叙述中正确的是( )。 A. 可以把define和if定义为用户标识符 B. 可以把define定义为用户标识符,但不能把if定义为用户标识符 C. 可以把if定义为用户标识符,但不能把define定义为用户标识符 D. define和if都不能定义为用户标识符 7.下面叙述中正确的是()。 A.#define和printf都是C语句 B.#define是C语句,而printf不是 C.printf是C语句,但#define不是 D.#define和printf都不是C语句 第九章编译预处理 9.1 选择题 【题9.1】以下叙述中不正确的是。 A)预处理命令行都必须以#号开始 B)在程序中凡是以#号开始的语句行都是预处理命令行 C)C程序在执行过程中对预处理命令行进行处理 D)以下是正确的宏定义 #define IBM_PC 【题9.2】以下叙述中正确的是。 A)在程序的一行上可以出现多个有效的预处理命令行 B)使用带参的宏时,参数的类型应与宏定义时的一致 C)宏替换不占用运行时间,只占编译时间 D)在以下定义中C R是称为“宏名”的标识符 #define C R 045 【题9.3】请读程序: #define ADD(x) x+x main() { int m=1,n=2,k=3; int sum=ADD(m+n)*k; printf(“sum=%d”,sum); } 上面程序的运行结果是。 A)sum=9 B)sum=10 C)sum=12 D)sum=18 【题9.4】以下程序的运行结果是。 #define MIN(x,y) (x)<(y)?(x):(y) main() { int i=10,j=15,k; k=10*MIN(i,j); printf(“%d\n”,k); } A)10 B)15 C)100 D)150 【题9.5】在宏定义#define PI 3.14159中,用宏名PI代替一个。 A)常量B)单精度数C)双精度数D)字符串 【题9.6】以下程序的运行结果是。 #include #if #ifdef和#ifndef的用法和区别 #if #ifdef和#ifndef用法 移位运算符的优先级高于条件运算符,重载是不能改变运算符优先级的,这点要注意,所以代码应当像下面这样调整,写宏的时候一定要注意优先级,尽量用括号来屏蔽运算符优先级。#define MAXIMUM(x,y) ((x)>(y)?(x):(y)) #define MINIMUM.... #include C语言预处理命令之条件编译(#ifdef,#else,#endif,#if等) 预处理过程扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。可见预处理过程先于编译器对源代码进行处理。 在C语言中,并没有任何内在的机制来完成如下一些功能:在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换。预处理过程还会删除程序中的注释和多余的空白字符。 预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。下面是部分预处理指令: 指令用途 #空指令,无任何效果 #include包含一个源代码文件 #define定义宏 #undef取消已定义的宏 #if如果给定条件为真,则编译下面代码 #ifdef如果宏已经定义,则编译下面代码 #ifndef如果宏没有定义,则编译下面代码 #elif如果前面的#if给定条件不为真,当前条件为真,则编译下面代码 #endif结束一个#if……#else条件编译块 #error停止编译并显示错误信息 一、文件包含 #include预处理指令的作用是在指令处展开被包含的文件。包含可以是多重的,也就是说一个被包含的文件中还可以包含其他文件。标准C编译器至少支持八重嵌套包含。 预处理过程不检查在转换单元中是否已经包含了某个文件并阻止对它的多次包含。这样就可以在多次包含同一个头文件时,通过给定编译时的条件来达到不同的效果。例如: #defineAAA #include"t.c" #undefAAA #include"t.c" 为了避免那些只能包含一次的头文件被多次包含,可以在头文件中用编译时条件来进行控制。例如: /*my.h*/ #ifndefMY_H #defineMY_H …… #endif 在程序中包含头文件有两种格式: #include C中的预处理命令是由ANSIC统一规定的,但它不是C语言的本身组成部分,不能直接对它们进行编译,因为编译程序无法识别它们。必须对程序进行通常的编译(包括词法和语法分析,代码生成,优化等)之前,先对程序中这些特殊的命令进行“预处理”,例如:如果程序中用#include命令包含一个文件“stdio.h”,则在预处理时,将stdio.h文件中的实际内容代替该命令。经过预处理后的程序就像没有使用预处理的程序一样干净了,然后再由编译程序对它进行编译处理,得到可供执行的目标代码。现在的编译系统都包括了预处理,编译和连接部分,在进行编译时一气呵成。我们要记住的是预处理命令不是C语言的一部分,它是在程序编译前由预处理程序完成的。 C提供的预处理功能主要有三种:宏定义,文件包含,条件编译。它们的命令都以“#”开头。 一,宏定义:用一个指定的标识符来代表一个字符串,它的一般形式为: #define 标识符字符串 #define PI 3.1415926 我们把标识符称为“宏名”,在预编译时将宏名替换成字符串的过程称为“宏展开”,而#define 是宏定义命令。 几个应该注意的问题: 1,是用宏名代替一个字符串,也就是做简单的置换,不做正确性检查,如把上面例子中的1写为小写字母l,预编译程序是不会报错的,只有在正式编译是才显示出来。 2,宏定义不是C语句,不必在行未加分号,如果加了分号则会连分号一起置换。 3,#define语句出现在程序中函数的外面,宏名的有效范围为定义命令之后到本源文件结束,通常#define命令写在文件开头,函数之前,作为文件的一部分,在此文件范围内有效。4,可以用#undef命令终止宏定义的作用域。如: #define PI 3.1415926 main(){ } #undef PI mysub(){ } 则在mysub中PI 不代表3.1415926。 5,在进行宏定义时,可以引用已定义的宏名,可以层层置换。 6,对程序中用双撇号括起来的字符串内的字符,即使与宏名相同,也不进行置换。 7,宏定义是专门用于预处理命令的一个专有名词,它与定义变量的含义不同,只做字符替换不做内存分配。 带参数的宏定义,不只进行简单的字符串替换,还进行参数替换。定义的一般形式为:#define 宏名(参数表)字符串 如:#define S(a,b) a*b,具体使用的时候是int area; area=(2,3); 对带参数的宏定义是这样展开置换的:在程序中如果有带参数的宏(如area=(2,3)),则按#define命令行中指定的字符串从左到右进行置换。如果串中包含宏中的形参(如a,b),则将程序语句中的相关参数(可以是常量,变量,或表达式)代替形参。如果宏定义中的字符串中的字符不是参数字符(如上*),则保留,这样就形成了置换的字符串。 带参数的宏与函数有许多相似之处,在调用函数时也是在函数名后的括号内写实参,也要求实参与形参的数目相等,但它们之间还有很大的不同,主要有: 1,函数调用时,先求出实参表达式的值,然后代入形参,而使用带参的宏只是进行简单的字符替换。 第9章预处理命令 宏定义不是C语句,所以不能在行尾加分号。如果加了分号则会连分号一起进行臵换。 可以用#undef命令终止宏定义的作用域。 对程序中用“”括起来的内容(即字符串内的字符),即使与宏名相同,也不进行臵换。宏定义只做字符替换,不分配内存空间。 宏名不是变量,不分配存储空间,也不能对其进行赋值。 在宏展开时,预处理程序仅对宏名作简单的字符串替换,不作任何检查。 在进行宏定义时,可以引用已定义的宏名 无参宏定义的一般格式: #define 标识符字符串 将这个标识符(名字)称为“宏名”,在用预编译时将宏名替换成字符串的过程称为“宏展开”。#define是宏定义命令。 带参宏定义的一般格式: #define 宏名(形参表)字符串 带参宏的调用和宏展开: 调用格式:宏名(实参表); 宏展开(又称为宏替换)的方法:用宏调用提供的实参直接臵换宏定义中相应的形参,非形参字符保持不变。 定义有参宏时,宏名与左圆括号之间不能留有空格。否则,C编译系统会将空格以后的所有字符均作为替代字符串,而将该宏视为无参宏。 有参宏的展开,只是将实参作为字符串,简单地臵换形参字符串,而不做任何语法检查。 为了避免出错,可以在所有形参外,甚至整个字符串外,均加上一对圆括号。 如: #define S(r) 3.14*(r)*(r) 则:area=S(a+b); 展开后为: area=3.14*(a+b)*(a+b); 调用有参函数时,是先求出实参的值,然后再复制一份给形参。而展开有参宏时,只是将实参简单地臵换形参。函数调用是在程序运行时处理的,为形参分配临时的内存单元;而宏展开则是在编译前进行的,在展开时不分配内存单元,不进行值的传递,也没有“返回值”的概念。调用函数只可得到一个返回值,而用宏可以设法得到几个结果。 在有参函数中,形参都是有类型的,所以要求实参的类型与其一致;而在有参宏中,形参和宏名都没有类型,只是一个简单的符号代表,因此,宏定义时,字符串可以是任何类型的数据。 使用宏次数多时,宏展开后源程序变长,因为每展开一次都是程序增长,而函数调用不会使源程序变长。 宏替换不占用运行时间,只占编译时间。而函数调用则占用运行时间(分配单元、保留现场、值传递、返回)。 在程序中如果有带实参的宏,则按#define命令行中指定的字符串从左到右进行臵换。如果字符串中包含宏中的形参,则将程序语句中相应的实参(可以是常量、变量或表达式)代替形参。如果宏定义中的字符串中的字符不是参数字符,则保留。 实验十二变量的存储类型与与编译命令(上机练习)1、输入下面的程序并运行,分析为什么会得到此结果。 #include A.11 B.12 C.13 D.15 #include “stdio.h” #define FUDGF(y) 2.84+y #define PR(a) printf(“%d”,(int)(a)) #define PRINT1(a) PR(a);putchar(‘\n’) main() { int x=2;PRINT1(FUDGF(5)*x); } 5.以下叙述正确的是()。 A.用#include包含的头文件的后缀不可以是“.a” B.若一些源程序中包含某个头文件;当该头文件有错时,只需对该头文件进行修改,包含此头文件所有源程序不必重新进行编译 C.宏命令可以看做是一行C语句 D.C编译中的预处理是在编译之前进行的。 6.以下有关宏替换的叙述不正确的是()。 A.宏替换不占用运行时间 B.宏名无类型 C.宏替换只是字符替换 D.宏名必须用大写字母表示7.宏定义#define G 9.8中的宏名G代替() A.一个单精度实数 B.一个双精度实数C.一个字符串 D.不确定类型的数8.若有宏定义: #define MOD(x,y) x%y 则执行以下程序段的输出为() int z,a=15,b=100; z=MOD(b,a); printf(“%d\n”,z++); A.11 B.10 C.6 D.宏定义不合法 9.以下程序的运行结果是()。 #define DOUBLE(r) r*r main( ) { int y1=1,y2=2,t; t=DOUBLE(y1+y2); printf(“%d\n”,t);} A.11 B.10 C.5 D.9 10.下列程序段的输出结果是() 多文件结构和编译预处理命令 C++完整的源程序一般由三部分构成:类的定义,类成员的实现,主函数 在较大的项目中,常需要多个源文件(即多个编译单元),c++要求一个类的定义必须在使用该类的编译单元中。因此,把类的定义写在头文件中。 (重点)一个项目至少分三个文件:类定义文件(.h)、类实现文件(.cpp)、类的使用文件(.cpp) (重点)对于复杂的程序:每个类都有单独的类定义和类实现。这样做的好处:可以对不同的文件进行单独编写、编译,最后链接,同时利用类的封 装性,在程序的调试和修改时只对其中某一个类的定义和实现修改,其余保持不动。 预处理指令声明中出现的注释以及一行单独一个#符号的情况在预编译处理过程中都会被 忽略掉。 宏定义在c++中依然使用,但最好的方式是在类型说明语句中用const修饰来取代宏定义。(重点)大型程序中,往往需要使用很多头文件,因此要发现重复包含并不容易。要解决这个问题,我们可以在头文件使用条件编译。(三种方式) 表1是所有预处理指令和意义 指令意义 #define 定义宏 #undef 取消定义宏 #include 包含文件 #ifdef 其后的宏已定义时激活条件编译块 #ifndef 其后的宏未定义时激活条件编译块 #endif 中止条件编译块 #if 其后表达式非零时激活条件编译块 #else 对应#ifdef, #ifndef, 或#if 指令 #elif #else 和#if的结合 #line 改变当前行号或者文件名 #error 输出一条错误信息 #pragma 为编译程序提供非常规的控制流信息 宏定义 #define指令定义宏,宏定义可分为两类:简单宏定义,带参数宏定义。 简单宏定义有如下一般形式: #define 名字替换文本 它指示预处理器将源文件中所有出现名字记号的地方都替换为替换文本,替换文本可以是任 C51几个预编译指令的用法 标签: 指令用法编译2009-07-31 10:47 预处理过程扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。可见预处理过程先于编译器对源代码进行处理。 在C 语言中,并没有任何内在的机制来完成如下一些功能: 在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换。预处理过程还会删除程序中的注释和多余的空白字符。 预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。下面是部分预处理指令: 指令用途 #空指令,无任何效果 #include 包含一个源代码文件 #define 定义宏 #undef 取消已定义的宏 #if 如果给定条件为真,则编译下面代码 #ifdef 如果宏已经定义,则编译下面代码 #ifndef 如果宏没有定义,则编译下面代码 #elif 如果前面的#if 给定条件不为真,当前条件为真,则编译下面代码 #en dif结束一个#if ......... #e条件编译块 #error 停止编译并显示错误信息 一、文件包含 #include 预处理指令的作用是在指令处展开被包含的文件。包含可以是多重的,也就是说一个被包含的文件中还可以包含其他文件。标准C编译器至少支 持八重嵌套包含。 预处理过程不检查在转换单元中是否已经包含了某个文件并阻止对它的多次包含。这样就可以在多次包含同一个头文件时,通过给定编译时的条件来达到不同的效果。例如: #define AAA #include "t.c" #undef AAA #include "t.c" 为了避免那些只能包含一次的头文件被多次包含,可以在头文件中用编译时条件来进行控制。例如: #ifndef MY_H #define MY_H #endif 在程序中包含头文件有两种格式: #include C51几个预编译指令的用法 标签: 指令用法编译2009-07-31 10:47 预处理过程扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。可见预处理过程先于编译器对源代码进行处理。 在C语言中,并没有任何内在的机制来完成如下一些功能:在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换。预处理过程还会删除程序中的注释和多余的空白字符。 预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。下面是部分预处理指令: 指令用途 #空指令,无任何效果 #include包含一个源代码文件 #define定义宏 #undef取消已定义的宏 #if如果给定条件为真,则编译下面代码 #ifdef如果宏已经定义,则编译下面代码 #ifndef如果宏没有定义,则编译下面代码 #elif如果前面的#if给定条件不为真,当前条件为真,则编译下面代码 #endif结束一个#if……#else条件编译块 #error停止编译并显示错误信息 一、文件包含 #include预处理指令的作用是在指令处展开被包含的文件。包含可以是多重的,也就是说一个被包含的文件中还可以包含其他文件。标准C编译器至少支持八重嵌套包含。 预处理过程不检查在转换单元中是否已经包含了某个文件并阻止对它的多次包含。这样就可以在多次包含同一个头文件时,通过给定编译时的条件来达到不同的效果。例如: #define AAA 预处理命令行都必须以【1】号开始. 答案: ======(答案1)====== # 设有以下宏定义 # define WIDTH 80 # define LENGTH (WIDTH +40) 则执行赋值语句:v= LENGTH*20;(v为int型变量)后,v的值是【1】. 答案: ======(答案1)====== 2400 设有以下宏定义 # define WIDTH 80 # define LENGTH WIDTH +40 则执行赋值语句:v= LENGTH*20;(v为int型变量)后,v的值是【1】.80+40*20 答案: ======(答案1)====== 880 以下程序的运行结果是【1】. #include #define MIN(x,y) (x) main() { inti=10,j=15,k ; k=10*MIN(i,j); printf("%d\n",k); } 答案: ======(答案1)====== 100 下列程序运行结果为: #define P 3 #define S(a) P*a*a main() {intar; ar=S(3+5);//3*3+5*3+5 printf("\n%d",ar); } #define宏都是直接替换的,不会计算后再替换。s(3+5) = p*3+5*3+5 = 9+15+5 =29 若想计算后在替换,需要加上括号: #define S(a) P*(a)*(a) 若有宏定义如下: #define X 5 #define Y X+1 #define Z Y*X/2 则执行以下printf语句后,输出结果是(). inta;a=Y; printf("%d ",Z); printf("%d\n",--a); A) 7 6 B) 12 6 C) 12 5 D) 7 5 答案:D 请读程序: #include 在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的情况下,给出主机或操作系统专有的特征。依据定义,编译指示是机器或操作系统专有的,且对于每个编译器都是不同的。 其格式一般为: #Pragma Para 其中Para 为参数,下面来看一些常用的参数。 (1)message 参数。Message 参数是我最喜欢的一个参数,它能够在编译信息输出窗口中输出相应的信息,这对于源代码信息的控制是非常重要的。其使用方法为: #Pragma message(“消息文本”) 当编译器遇到这条指令时就在编译输出窗口中将消息文本打印出来。 当我们在程序中定义了许多宏来控制源代码版本的时候,我们自己有可能都会忘记有没有正确的设置这些宏,此时我们可以用这条指令在编译的时候就进行检查。 假设我们希望判断自己有没有在源代码的什么地方定义了_X86这个宏可以用下面的方法 #ifdef _X86 #Pragma message(“_X86 macro activated!”) #endif 当我们定义了_X86这个宏以后,应用程序在编译时就会在编译输出窗口里显示“_ X86 macro activated!”。我们就不会因为不记得自己定义的一些特定的宏而抓耳挠腮了。 (2)另一个使用得比较多的pragma参数是code_seg。格式如: #pragma code_seg( ["section-name"[,"section-class"] ] ) 它能够设置程序中函数代码存放的代码段,当我们开发驱动程序的时候就会使用到它。 (3)#pragma once (比较常用) 只要在头文件的最开始加入这条指令就能够保证头文件被编译一次,这条指令实际上在VC6中就已经有了,但是考虑到兼容性并没有太多的使用它。 (4)#pragma hdrstop表示预编译头文件到此为止,后面的头文件不进行预编译。BCB可以预编译头文件以加快链接的速度,但如果所有头文件都进行预编译又可能占太多磁盘空间,所以使用这个选项排除一些头文件。 有时单元之间有依赖关系,比如单元A依赖单元B,所以单元B要先于单元A 编译。你可以用#pragma startup指定编译优先级,如果使用了#pragma package(smart_init) ,BCB就会根据优先级的大小先后编译。 (5)#pragma resource "*.dfm"表示把*.dfm文件中的资源加入工程。*.dfm中包括窗体外观的定义。 C语言预处理命令总结大全 (2012-02-13 17:18) 标签: C语言预处理分类:C编程 C程序的源代码中可包括各种编译指令,这些指令称为预处理命令。虽然它们实际上不是C语言的一部分,但却扩展了C程序设计的环境。本节将介绍如何应用预处理程序和注释简化程序开发过程,并提高程序的可读性。ANSI标准定义的C 语言预处理程序包括下列命令: #define,#error,#include,#if,#else,#elif,#endif,#ifdef,#ifndef,#undef,#line,#pragma等。非常明显,所有预处理命令均以符号#开头,下面分别加以介绍。 一 #define 命令#define定义了一个标识符及一个串。在源程序中每次遇到该标识符时,均以定义的串代换它。ANSI标准将标识符定义为宏名,将替换过程称为宏替换。命令的一般形式为: #define identifier string 注意: 1该语句没有分号。在标识符和串之间可以有任意个空格,串一旦开始,仅由一新行结束。 2宏名定义后,即可成为其它宏名定义中的一部分。 3 宏替换仅仅是以文本串代替宏标识符,前提是宏标识符必须独立的识别出来,否则不进行替换。例如: #define XYZ this is a tes 使用宏printf("XYZ");//该段不打印"this is a test"而打印"XYZ"。因为预编译器识别出的是"XYZ" 4如果串长于一行,可以在该行末尾用一反斜杠' \'续行。 #defineLONG_STRING"this is a very long\ string that is used as an example" 5 C语言程序普遍使用大写字母定义标识符。 6 用宏代换代替实在的函数的一大好处是宏替换增加了代码的速度,因为不 存在函数调用的开销。但增加速度也有代价:由于重复编码而增加了程序长度。 二 #error 命令#error强迫编译程序停止编译,主要用于程序调试。 #error指令使预处理器发出一条错误消息,该消息包含指令中的文本.这条指令的目的就是在程序崩溃之前能够给出一定的信息。 三 #include C++ 预编译命令C++预处理指令 #include #define #undef #pragma #import #error #line #ifdef #ifndef #if #else #elif #endif 宏以#起始不以;结束 一. #include 文件包含 预编译期发现#include后,将会寻找HeaderName并把其包含到当前文件中EG:#include 编译器对每个文件只编译一次生成一份机器代码.obj,如果在多个地方包含了同一个头文件,则会出现多次包含的错误,即试图让编译器将此文件编译多次生成多份机器代码。 预编译保护解决此问题。 二. #define #undef 宏替换 #define 宏宏主体 宏展开:在代码中出现宏,会用宏实体代替宏 #define 定义常量、函数宏 #undef 结束常量、函数宏定义 1. 常量宏 常量宏:是最常见的一种形式。即使用一个宏代替实际的常量,如数据、字符、字符串常量等 #define CONST_VAL 2 #define MEG_EG "Test Macro!" #define CHARACTOR_EG 'M' 注: C语言预处理命令总结大全 标签: C语言预处理分类:C编程 C程序的源代码中可包括各种编译指令,这些指令称为预处理命令。虽然它们实际上不是C语言的一部分,但却扩展了C程序设计的环境。本节将介绍如何应用预处理程序和注释简化程序开发过程,并提高程序的可读性。ANSI标准定义的C语言预处理程序包括下列命令: #define,#error,#include,#if,#else,#elif,#endif,#ifdef,#ifndef,#undef,#line,#pragma等。非常明显,所有预处理命令均以符号#开头,下面分别加以介绍。 一 #define 命令#define定义了一个标识符及一个串。在源程序中每次遇到该标识符时,均以定义的串代换它。ANSI标准将标识符定义为宏名,将替换过程称为宏替换。命令的一般形式为: #define identifier string 注意: 1该语句没有分号。在标识符和串之间可以有任意个空格,串一旦开始,仅由一新行结束。 2宏名定义后,即可成为其它宏名定义中的一部分。 3 宏替换仅仅是以文本串代替宏标识符,前提是宏标识符必须独立的识别出来,否则不进行替换。例如: #define XYZ this is a tes 使用宏printf("XYZ");//该段不打印"this is a test"而打印"XYZ"。因为预编译器识别出的是"XYZ" 4如果串长于一行,可以在该行末尾用一反斜杠' \'续行。 #defineLONG_STRING"this is a very long\ string that is used as an example" 5 C语言程序普遍使用大写字母定义标识符。 6 用宏代换代替实在的函数的一大好处是宏替换增加了代码的速度,因为不存在函数调用 的开销。但增加速度也有代价:由于重复编码而增加了程序长度。 二 #error 命令#error强迫编译程序停止编译,主要用于程序调试。 #error指令使预处理器发出一条错误消息,该消息包含指令中的文本.这条指令的目的就是在程序崩溃之前能够给出一定的信息。 三 #include 命令#i nclude使编译程序将另一源文件嵌入带有#include的源文件,被读入的源文件必须用双引号或尖括号括起来。例如: #include"stdio.h"或者#include 第一题、单项选择题(每题1分,5道题共5分) 1、有定义char p[]="AB\0CD\0E";,能输出字符串”ABCDE”的语句为: B、printf("%s%s%s",&p[0],p+3, A、printf("%s",p); p+6); C、printf("%s%s%s",&p[0],&p D、printf("%s",&p[0]); [2],&p[3]); 2、已知int a[]={1,2,3,4,5,6,7,8,9},*p = a; 则值为3的表达式是() A、p+=2,*(p++) B、p+=2,*++p C、p+=3,*p++ D、p+=2,++*p 3、若有int f(int a,int b);,则说明函数f( )。 B、能被同一源程序其他文件中的函数 A、是一个内部函数 调用 C、是一个外部函数 D、只能在本文件中使用 4、在主函数中定义的变量( )。 A、只在主函数中有效 B、可以在整个文件中有效 C、可以在所有函数中有效 D、可以在被调用的函数中有效 5、如果全局的外部变量和函数体内定义的局部变量重名,则( )。 A、出错 B、局部变量优先 C、外部变量优先 D、全局的外部变量优先 第二题、多项选择题(每题2分,5道题共10分) 1、以下叙述中,正确的叙述是: A、预处理命令须以#开始 B、在程序中凡以#开始的语句都是预处理命令 C、预处理行不是c的可编译语句 D、C程序在执行过程中对预处理命令进行处理 2、以下叙述中,正确的叙述是: A、预处理命令必须在程序编译前进行处理 B、在程序中凡以#开始的语句都是预处理命令 C、C程序在执行过程中对预处理命令进行处理 D、预处理行在编译阶段进行处理 3、以下叙述中,不正确的叙述是( )。 A、函数的形参都属于全局变量 B、全局变量的作用域不比局部变量的作用域范围大 C、静态(static)类别变量的生存期贯穿整个程序的运行期间 D、未在定义语句中赋初值的auto变量和static变量的初值都是随机值 4、设char s[10];int i=5;,下列表达式中,不正确的表达式是( )。 A、s[i+6] B、*(s+i) C、*(&s+i) D、*((s++)+i 5、函数中的形参若为指针,则调用时对应位置上的实参可以是( )。 A、地址 B、数组名 C、简单变量的地址 D、指针变量 第三题、判断题(每题1分,5道题共5分) 1、允许在不同的函数中使用相同的变量名。 正确错误 2、设int x=5,*p=&x;则&(*p)与p是同一回事。 正确错误 3、可以利用全局变量从函数中得到多个返回值。 正确错误 C程序的源代码中可包括各种编译指令,这些指令称为预处理命令。虽然它们实际上不是C 语言的一部分,但却扩展了C程序设计的环境。本节将介绍如何应用预处理程序和注释简化程序开发过程,并提高程序的可读性。ANSI标准定义的C语言预处理程序包括下列命令:#define,#error,#include,#if,#else,#elif,#endif,#ifdef,#ifndef,#undef,#line,#pragma等。非常明显,所有预处理命令均以符号#开头,下面分别加以介绍。 一#define 命令#define定义了一个标识符及一个串。在源程序中每次遇到该标识符时,均以定义的串代换它。ANSI标准将标识符定义为宏名,将替换过程称为宏替换。命令的一般形式为: #define identifier string 注意: 1该语句没有分号。在标识符和串之间可以有任意个空格,串一旦开始,仅由一新行结束。 2宏名定义后,即可成为其它宏名定义中的一部分。 3 宏替换仅仅是以文本串代替宏标识符,前提是宏标识符必须独立的识别出来,否则不进行替换。例如: #define XYZ this is a tes 使用宏printf("XYZ");//该段不打印"this is a test"而打印"XYZ"。因为预编译器识别出的是"XYZ" 4如果串长于一行,可以在该行末尾用一反斜杠' \'续行。 #defineLONG_STRING"this is a very long\ string that is used as an example" 5 C语言程序普遍使用大写字母定义标识符。 6 用宏代换代替实在的函数的一大好处是宏替换增加了代码的速度,因为不存在函数调用的开销。但增加速度也有代价:由于重复编码而增加了程序长度。 二#error 命令#error强迫编译程序停止编译,主要用于程序调试。 常见的预处理命令及功能 1.常见的预处理功能: 预处理器的主要作用就是把通过预处理的内建功能对一个资源进行等价替换,最常见的预处理有:文件包含,条件编译、布局控制和宏替换4种。 文件包含:#include 是一种最为常见的预处理,主要是做为文件的引用组合源程序正文。 条件编译:#if,#ifndef,#ifdef,#endif,#undef等也是比较常见的预处理,主要是进行编译时进行有选择的挑选,注释掉一些指定的代码,以达到版本控制、防止对文件重复包含的功能。 布局控制:#progma,这也是我们应用预处理的一个重要方面,主要功能是为编译程序提供非常规的控制流信息。 宏替换:#define,这是最常见的用法,它可以定义符号常量、函数功能、重新命名、字符串的拼接等各种功能。 2.下面我们看一下常见的预处理指令: #define 宏定义 #undef 未定义宏 #include 文本包含 #ifdef 如果宏被定义就进行编译 #ifndef 如果宏未被定义就进行编译 #endif 结束编译块的控制 #if 表达式非零就对代码进行编译 #else 作为其他预处理的剩余选项进行编译 #elif 这是一种#else和#if的组合选项 #line 改变当前的行数和文件名称 #error 输出一个错误信息 #pragma 为编译程序提供非常规的控制流信息 3.下面我们对这些预处理进行一一的说明,考虑到宏的重要性和繁琐性,我们把它放到最后讲。 文件包含指令: 这种预处理使用方式是最为常见的,平时我们编写程序都会用到,最常见的用法是: #include C语言习题集(预处理命令篇)
编译预处理
c语言中预编译指令的应用
c语言预处理命令之条件编译(ifdefelseendifif等)
C中的预处理命令
第9章 预处理命令
变量的存储类型与预编译命令
多文件结构和编译预处理命令
C51几个预编译指令的用法
C51几个预编译指令的用法
预处理命令行
c++预编译命令
C语言预处理命令总结大全
C++ 预编译命令
C语言预处理命令总结大全
预处理命令
C语言预处理命令的总结大全
常见的预处理命令及功能