SPSS、S-PLUS、SAS详细比较
SAS、S-PLUS、SPSS详细比较
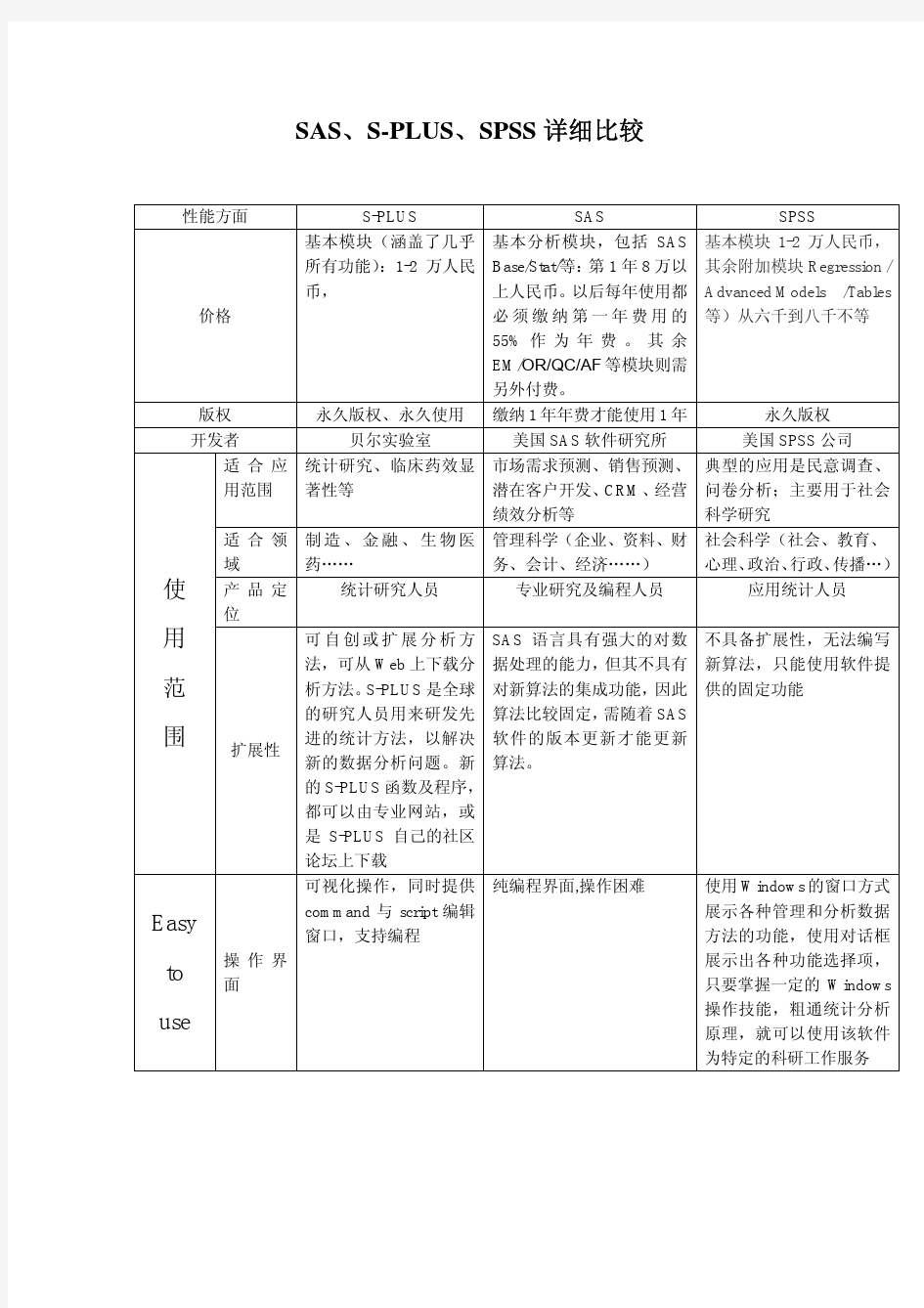
性能方面 S-PLUS SAS SPSS
价格基本模块(涵盖了几乎
所有功能):1-2万人民
币,
基本分析模块,包括SAS
Base/Stat/等:第1年8万以
上人民币。以后每年使用都
必须缴纳第一年费用的
55%作为年费。其余
EM/OR/QC/AF等模块则需
另外付费。
基本模块1-2万人民币,
其余附加模块Regression /
Advanced Models /Tables
等)从六千到八千不等
版权永久版权、永久使用缴纳1年年费才能使用1年永久版权
开发者贝尔实验室美国SAS软件研究所美国SPSS公司
适合应用范围统计研究、临床药效显
著性等
市场需求预测、销售预测、
潜在客户开发、CRM、经营
绩效分析等
典型的应用是民意调查、
问卷分析;主要用于社会
科学研究
适合领域制造、金融、生物医
药……
管理科学(企业、资料、财
务、会计、经济……)
社会科学(社会、教育、
心理、政治、行政、传播…)
产品定位统计研究人员专业研究及编程人员应用统计人员
使
用
范
围
扩展性可自创或扩展分析方
法,可从Web上下载分
析方法。S-PLUS是全球
的研究人员用来研发先
进的统计方法,以解决
新的数据分析问题。新
的S-PLUS函数及程序,
都可以由专业网站,或
是S-PLUS自己的社区
论坛上下载
SAS语言具有强大的对数
据处理的能力,但其不具有
对新算法的集成功能,因此
算法比较固定,需随着SAS
软件的版本更新才能更新
算法。
不具备扩展性,无法编写
新算法,只能使用软件提
供的固定功能
Easy
to use 操作界
面
可视化操作,同时提供
command与script编辑
窗口,支持编程
纯编程界面,操作困难使用Windows的窗口方式
展示各种管理和分析数据
方法的功能,使用对话框
展示出各种功能选择项,
只要掌握一定的Windows
操作技能,粗通统计分析
原理,就可以使用该软件
为特定的科研工作服务
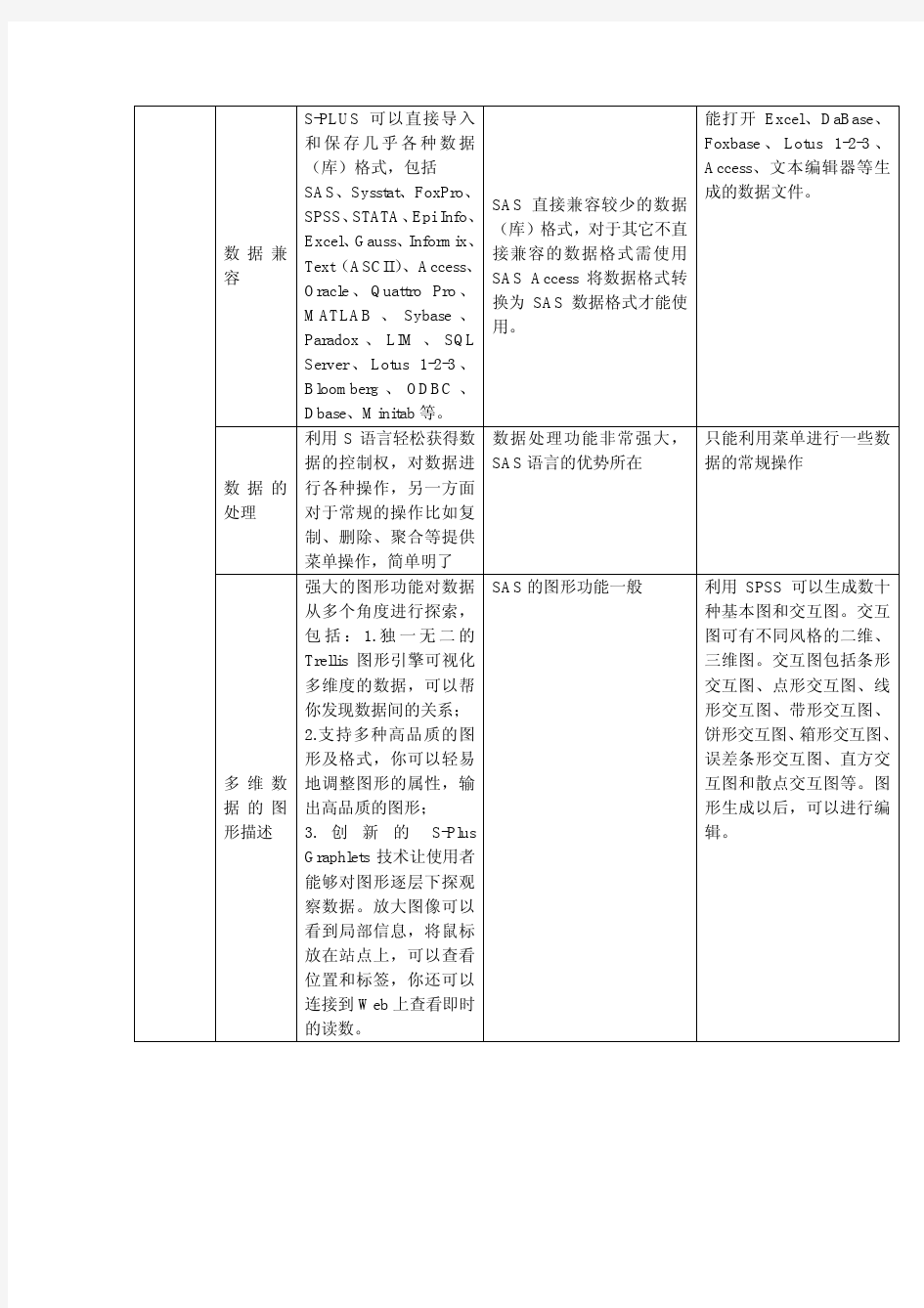
数据兼容S-PLUS可以直接导入
和保存几乎各种数据
(库)格式,包括
SAS、Sysstat、FoxPro、
SPSS、STATA、Epi Info、
Excel、Gauss、Informix、
Text(ASCII)、Access、
Oracle、Quattro Pro、
MATLAB、Sybase、
Paradox、LIM、SQL
Server、Lotus 1-2-3、
Bloomberg、ODBC、
Dbase、Minitab等。
SAS直接兼容较少的数据
(库)格式,对于其它不直
接兼容的数据格式需使用
SAS Access将数据格式转
换为SAS数据格式才能使
用。
能打开Excel、DaBase、
Foxbase、Lotus 1-2-3、
Access、文本编辑器等生
成的数据文件。
数据的处理利用S语言轻松获得数
据的控制权,对数据进
行各种操作,另一方面
对于常规的操作比如复
制、删除、聚合等提供
菜单操作,简单明了
数据处理功能非常强大,
SAS语言的优势所在
只能利用菜单进行一些数
据的常规操作
多维数据的图形描述强大的图形功能对数据
从多个角度进行探索,
包括:1.独一无二的
Trellis图形引擎可视化
多维度的数据,可以帮
你发现数据间的关系;
2.支持多种高品质的图
形及格式,你可以轻易
地调整图形的属性,输
出高品质的图形;
3.创新的S-Plus
Graphlets技术让使用者
能够对图形逐层下探观
察数据。放大图像可以
看到局部信息,将鼠标
放在站点上,可以查看
位置和标签,你还可以
连接到Web上查看即时
的读数。
SAS的图形功能一般利用SPSS可以生成数十
种基本图和交互图。交互
图可有不同风格的二维、
三维图。交互图包括条形
交互图、点形交互图、线
形交互图、带形交互图、
饼形交互图、箱形交互图、
误差条形交互图、直方交
互图和散点交互图等。图
形生成以后,可以进行编
辑。
分析方法S-PLUS提供超过4200
种包含传统及现代技巧
的数据分析函数。方便
的菜单、工具列及对话
框,让你轻松地存取和
分析数据。容易地选择
能提供最佳结果的分析
模型。面向对象环境,
所有函数、数据及模型
都视为对象,可以让你
使用传统及现代的不同
方法来符合不同的模
型,并选择最佳结果的
模型
SAS是确切地说是一套大
型集成应用软件系统,具有
完备的数据存取、数据管
理、数据分析和数据展现功
能。
SAS系统中提供的主要分
析功能包括统计分析、经济
计量分析、时间序列分析、
决策分析、财务分析和全面
质量管理工具等等,功能相
当强大。
提供很多常用统计方法,
但是分析功能仍然有所欠
缺
编程灵活性使用S语言可以很方便
编写自己的算法,得到
你想要的结果
对于数据预处理、操作方面
具有很强大的灵活性,但是
对于统计分析功能灵活性
不强,只能通过设置不同参
数来改变输出结果。
几乎是固定的用法,不具
备灵活性
分析结果的演示支持图形化、文字框或
是HTML表格。.用鼠标
轻松点击,就可以把分
析结果自动生成为Word
文档和PowerPoint文档
中。
统计分析结果详细,支持
Word和HTML格式,但是
输出图形品质不高.
分析结果清晰、直观、易
学易用。支持HTML格式
报告. 但是它很难与一般
办公软件如Office直接兼
容,在撰写调查报告时往
往要用电子表格软件及专
业制图软件来重新绘制相
关图表
结果的配置可以整合到几乎任何系
统内。在Unix系统上,
S-PLUS的Connect/Java
界面,可以让S-PLUS
整合到Java程序中。在
Windows上,S-PLUS的
Connect/C++界面,可以
在你开发的C++程序内
使用全部的S-PLUS分
析方法。另外S-PLUS
的DDE及OLE自动化
界面,可以使S-PLUS
与其他Windows应用软
件无缝集成,允许你从
Excel或是Visual Basic
应用软件中执行
S-PLUS功能。
可以承担OLE SERVER 的
功能,并支持所有对OLE
进行支持的前端表现工具
厂家
现在的SPSS软件支持
OLE技术和ActiveX技术,
使生成的表格或交互图对
象可以与其他同样支持该
技术的软件进行自动嵌入
与链接。SPSS还有内置的
VBA客户语言,可以通过
Visual Basic编程来控制
SPSS。
附加模块介绍S+ArrayAnalyzer 生物
科技Microarray DNA分
析
S+FinMetrics 财经分析
和金融风险控制
S+NuOPT 数值计算优
化
S+SeqTrial 临床试验设
计
S+Wavelets 小波分析模
块
S+SpatialStats 空间统
计模块
SAS WA? 建立数据仓库
的集成工具
Enterprise Miner? 数据挖
掘模块
SAS? Text Miner 文本挖掘
模块
SAS/AF:应用开发工具。
采用面向对象的技术,开发
用户自己的图形用户界面
(GUI)的应用系统
SAS/EIS:行政管理系统或
个人的信息系统
SAS/OR? 运筹学和工程管
理的软件,提供运筹学方
法,是强有力的决策支持工
具
SAS/QC?用于质量的专用
软件,为全面质量管理提供
一系列工具,进行标准的过
程控制以及试验设计
SPSS Tables 用易于理解
的方式表示分析结果,并
包含35种统计功能
SPSS Regression Models:
更好地预示和测度数据
SPSS Advanced Models 用
成熟的过程分析复杂关系
SPSS Conjoint 一个包括
三个相关过程的系统,用
于全轮廓联合分析
SPSS Categories 揭示消
费者特性,改良产品并合
理定价
SPSS Trends 强大的时间
序列分析工具,用于预测
分析
SPSS Exact Tests 得到甚
至是小规模数据的正确p-
值
GOLDMineR 顺序和分类
变量回归
TextSmart 快速、精确、完
整地分析开放式文字问题
Amos 用强大易用的结构
化方程模型突破回归和因
子分析的极限
DeltaGraph 即刻得到世界
级的图形
spss 统计分析报告
Spss统计分析实验报告 一.实验目的: 通过统计分析检验贫血患儿在接受新药物与常规药物 之后血红蛋白增加量的情况,得出两者疗效是否存在差异, 并且可以判断那种药物疗效好。 二.实验步骤 例题:某医院用某种新药与常规药物治疗婴幼儿贫血,将20 名贫血患儿随机等分为2 组,分别接受两种药物治疗,测得 血红蛋白增加量(g/L)如下,问新药与常规药物的疗效有别 差别? 新药 24 36 25 14 26 34 23 20 15 19 组 常规 14 18 20 15 22 24 21 25 27 23 药物 组 解题: 1)根据题意,我们采用独立样本T检验的方法进行统计分析。提出:无效假设H0:新药物与常规药物的疗效没 有差别。 备择假设HA:新药物与常规药物的疗效有差别。
2)在spss中的“变量视图”中定义变量“药组”,“血红蛋白增加量”,之后在数据视图中输入数据,其中新药组定义为组1,常规药物组定义为组 2. 保存数据 。 3)在spss软件上操作分析过程如下:分析——比较变量——独立样本T检验——将“血红蛋白增加量变量”导入“检验变量”,
——将“药组变量”导入“分组变量”——定义组1为 新药组,组2为常规药物组——单击选项将置信度区间 设为95%,输出分析数据如下: 表1: 组统计量 药组N 均值标准差均值的标准误 血红蛋白增加量新药组10 23.6000 7.22957 2.28619 常规药组10 20.9000 4.22821 1.33708 表2: 独立样本检验 方差方程的 Levene 检验均值方程的 t 检验 F Sig. t df Sig.(双侧) 均值差值标准误血红蛋白增加量假设方差相等 1.697 .209 1.019 18 .321 2.70000 2. 假设方差不相等 1.019 14.512 .325 2.70000 2. 4)输出结果分析 由上述输出表格分析知:接受新药物组和常规药物组的
SPSS期末统计分析报告(可打印修改)
大学生参加校园比赛活动积极性调查 统计分析报告
目录 一.研究背景 (3) 1.调查背景及目的 (3) 2.研究分析方法 (3) 二.数据分析过程 (3) 1.频数分析 (3) 2.交叉分组下的频数分析 (4) 3.两独立样本非参数检验 (5) 4.相关分析 (6) 5.回归分析 (6) 三.结论 (7) 四.建议 (7) 五.小组成员及分工 (7) 六.调查问卷 (8)
一.研究背景 1.调查背景及目的 随着时代的发展,大学生在校学习已经不仅仅局限于书本知识的掌握,现代教育更需要的是大学生书本知识的运用与实践。每学期学校都会组织了大量丰富多彩的比赛,这些比赛极大地丰富了大学生的校园文化生活。不过一些比赛活动并不能得到大学生的积极参与或支持,比赛活动该怎样做才能让大学生满意,提高大学生参加学校活动的积极性。本组进行关于“大学生参加校园比赛活动积极性调查”的问卷调查,为了使活动更有针对性,使更多的同学积极参加到学校的各项活动,丰富同学们的课余文化生活,营造良好的学习氛围。 2.研究分析方法 报告分析方法包括:SPSS的基本统计分析、SPSS的非参数检验、SPSS的相关分析、SPSS的线性回归分析 二.数据分析过程 1.频数分析
由上述表格可得,本次调查的总人数为101人,其中男生44人,女生57人。年级分布情况是:人数最多的是大三,其次是大一,人数较少的是大二和大四,人数大致相当。在被调查的同学中,对参加比赛的态度情况是:“偶尔会考虑参加”占比例最多,其次是“是自己课余活动的一部分”和“很排斥”,比例最少的是“可有可无”,该特征从饼图中表现得更直观。 2.交叉分组下的频数分析
spss统计分析报告期末考精彩试题
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
spss期末大数据分析报告
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级xxx班姓名xxx 学号xxx 题号一二三四五六总成绩成绩 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
SPSS数据分析报告
SPSS期末报告 关于员工受教育程度对其工资水平的影响 统计分析报告 课程名称:SPSS统计分析方法 姓名:汤重阳 学号:1402030108 所在专业:人力资源管理 所在班级:三班
目录 一、数据样本描述 (1) 二、要解决的问题描述 (1) 1 数据管理与软件入门部分 (1) 1.1 分类汇总 (1) 1.2 个案排秩 (1) 1.3 连续变量变分组变量 (1) 2 统计描述与统计图表部分 (1) 2.1 频数分析 (1) 2.2 描述统计分析 (1) 3 假设检验方法部分 (1) 3.1 分布类型检验 (2) 3.1.1 正态分布 (2) 3.1.2 二项分布 (2) 3.1.3 游程检验 (2) 3.2 单因素方差分析 (2) 3.3 卡方检验 (2) 3.4 相关与线性回归的分析方法 (2) 3.4.1 相关分析(双变量相关分析&偏相关分析) (2) 3.4.2 线性回归模型 (2) 4 高级阶段方法部分 (2) 三、具体步骤描述 (3) 1 数据管理与软件入门部分 (3) 1.1 分类汇总 (3) 1.2 个案排秩 (4) 1.3 连续变量变分组变量 (4) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (7) 3 假设检验方法部分 (8) 3.1 分布类型检验 (8) 3.1.1 正态分布 (8) 3.1.2 二项分布 (10) 3.1.3 游程检验 (10) 3.2 单因素方差分析 (12) 3.3 卡方检验 (13) 3.4 相关与线性回归的分析方法 (14) 3.4.1 相关分析 (14) 3.4.2 线性回归模型 (15) 4 高级阶段方法部分 (17) 4.1 信度 (18) 4.2 效度 (18)
SPSS统计软件期末作业
统计软件及应用期末作业 完成作业:3、5、11、12题 第3题:基本统计分析3 利用居民储蓄调查数据,从中随机选取85%的样本,进行分析,实现以下目标: 1、分析不同职业储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格; 2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度;分析储户一次存款金额的分布,并对不同年龄段的储户进行比较。 基本思路: 首先通过随机抽样中的近似抽样方式,对居民储蓄调查数据进行抽样。 操作步骤:选择菜单数据→选择个案→随机个案样本,样本尺寸填大约所有个案85%。 1、题目:分析不同职业储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格。 基本思路:首先进行多选项分析,定义名为X的多选项变量集,其中包括a7_1、a7_2、a7_3三个变量,然后对多选项变量集进行频数分析;对不同职业储户储蓄目的进行分析,采用多选项交叉分组下的频数分析。 操作步骤:
分析:从折线图看出,储户中商业服务业的人数最多,总体上所有职业储户的正常生活零用所占的百分比最大,买证券及单位集资的人较少,说明大部分人群还没有这方面的意识。 2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度。 基本思路:该问题列联表的行变量为户口,列变量为未来收入状况,在列联表中输出各种百分比、期望频数、剩余、标准化剩余,显示各交叉分组下频数分布柱形图,并利用卡方检验方法,对城镇和农村储户对该问题的态度是否一致进行分析。 操作步骤:分析→描述统计→交叉表,显示复式条形图前打勾,行选择户口,列选择未来收入情况,统计量选择卡方,点击单元格,在观察值、期望值、行、列、总计、四舍五入单元格计数前打勾,最后确认。
统计分析与SPSS应用_期末作业
统计分析与SPSS的应用 摘要:为对统计分析与spss应用分析所学知识进行巩固和检验,特运用所学知识进行简单的统计分析应用,下文以某校学生学期成绩进行模拟分析。 一:原始数据:10级市场营销2班成绩 分析一:综测成绩四分位数 上表表明:综测成绩的最小值为68.61分,最大值为89.15分。其中25%的学生综测成绩为74.4100分,50%的学生综测成绩为80.3740分,75%的学生综测成绩为85.2200分。四分位数差从侧面证实了学生综测成绩呈一定左偏分布。
分析二:综测成绩直方图 上图表明:该班学生的综测成绩均分为80.07分,标准差为5.62。从图中可以看出,综测成绩呈左偏性分布,在85分左右的学生人数最多,70分左右的学生人数最少。 分析三:综测成绩的基本统计量分析 上表表明:综测成绩的极差为20.55分,意味着数据相对较分散。另外,综测成绩的最小值和最大值分别为68.61分和89.15分,平均分为80.0734分,标准差为5.61963。从偏度系数可以看出,系数小于0,偏度标准误差为0.421,因而该班综测成绩呈左偏分布,。从峰度系数可以看出,峰度值小于0,峰度标准误差为0.821,因而数据的分布比标准正态分布更加平缓,称
为平峰分布。 分析四:各科成绩的统计量分析比较 各科成绩统计量结果分析表 由上表可知:宏观经济学的全距最大,而生产与运作管理的全距最小,表明宏观经济学的成绩离散程度最高,而生产与运作管理的成绩离散程度最低;同时,对于标准差而言,也是宏观经济学的标准差最大而生产与运作管理的标准差最小。各科成绩平均分最高的为体育成绩,平均分最低的为英语成绩。各科成绩中只有人力资源管理的成绩是呈右偏分布,其他各科成绩均呈左偏分布。另外,各科成绩中,只有宏观经济学的成绩呈尖峰分布,其他各科呈平峰分布。
SPSS分析报告实例
SPSS与数据统计分析期末论文影响学生对学校服务满意程度的因素分析
一、数据来源 本次数据主要来源自本校同学,调查了同学们年级、性别、助学金申请情况、生源所在地、学院、毕业学校、游历情况、家庭情况、升高、体重、近视程度、学习时间、经济条件、兴趣、对学校各方面的评价、与对学校总评价以及建议等共41条信息,共收集数据样本724条。我们将运用SPSS,对变量进行频数分析、样本T检验、相关分析等手段,旨在了解同学们对学校提供的满意程度与什么因素有关。 二、频数分析 可靠性统计 克隆巴赫 Alpha 项数 .985 62 对全体数值进行可信度分析
本次数据共计724条,首先从可靠性统计来看,alpha值为0.985,即全体数据绝大部分是可靠的,我们可以在原始数据的基础上进行分析与处理。 其中,按年级来看,绝大多数为大二学生填写(占了总人数的67.13%),之后分别依次为大二(23.76%)、大四(4.14%)、大一(4.97%)。而从专业来看,占据了数据绝大多数样本所在的学院为机械、材料、经管、计通。 三、数据预处理 拿到这份诸多同学填写的问卷之后,我们首先应对一些数据进行处理,对于数据的缺失值处理,由于我们对本份调查的分析重点方面是关于学生的经济情况的,因此对于确实的部分数据,升高、体重、近视度数、感兴趣的事等无关项我们均不需要进行缺失值的处理,而我们可能重点关注的每月家里给的钱、每月收入以及每月支出,由于其具有较强主观性,如果强行处理缺失值反而会破坏数据的完整性,因此我们筛去未填写的数据,将剩余数据当作新的样本进行分析。 而对于一些关键的数据,我们需要做一些必要的预处理,例如一些调查项,我们希望得到数值型变量,但是填写时是字符型变量,我们就应该新建一个数字型变量并将数据复制,以便后续分析。同时一些与我们分析相关的缺省值,一些明显可以看出的虚假信息,我们都需要先进行处理。而具体预处理需要怎么做,这将会在其后具体分析时具体给出。
spss的数据分析报告.doc
关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够了解变量的取值状 况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下: Gender 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分 布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。
spss的数据分析报告
spss的数据分析报告 关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够了解变量的取值状 况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统 计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而 了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics Educational Gender Level (years) N Valid 474 474 Missing 0 0 首先,对该公司的男女性别分布进行频数分析,结果如下: Gender
Cumulative Frequency Percent Valid Percent Percent Valid Female 216 45.6 45.6 45.6 Male 258 54.4 54.4 100.0 Total 474 100.0 100.0 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表 : Educational Level (years) Cumulative Frequency Percent Valid Percent Percent Valid 8 53 11.2 11.2 11.2 12 190 40.1 40.1 51.3 14 6 1.3 1.3 52.5 15 116 24.5 24.5 77.0 16 59 12.4 12.4 89.5 17 11 2.3 2.3 91.8 18 9 1.9 1.9 93.7 19 27 5.7 5.7 99.4 20 2 .4 .4 99.8 21 1 .2 .2 100.0 Total 474 100.0 100.0 Histogram 200
SPSS期末大作业-完整版
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.008234.634.634.6 2.007632.132.166.7 3.0010 4.2 4.270.9 4.00229.39.380.2 5.004719.819.8100.0合计237100.0100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效1 缺失0百分位数 2550.00 5050.00 7550.00 20~35岁 N 有效131 缺失0百分位数 25500.00 501000.00 755000.00 35~50岁 N 有效73 缺失0百分位数 25500.00 501000.00 754500.00 50岁以上 N 有效32 缺失0百分位数 25525.00 501000.00 752000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
利用SPSS进行量表分析报告文案
第五节利用SPSS进行量表分析 在第五章调查研究中,我们介绍了量表的类型、编制的步骤及其应用,在本节将介绍利用SPSS 软件对量表进行处理分析。 在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析和信度分析。 项目分析,目的是找出未达显著水准的题项并把它删除。它是通过将获得的原始数据求出量表中题项的临界比率值一一CR值来作出判断。通常,量表的制作是要经过专家的设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者的反应程度。故往往在量表处理中可以省去这一步。 因素分析,目的是在多变量系统中,把多个很难解释,而彼此有关的变量,转化成少数有概念化意义而彼此独立性大的因素,从而分析多个因素的关系。在具体应用时,大多数采用“主成份因素分析”法,它是因素分析中最常使用的方法。 信度分析,目的是对量表的可靠性与有效性进行检验。如果一个量表的信度愈高,代表量表愈稳定。也就表示受试者在不同时间测量得分的一致性,因而又称“稳定系数”。根据不同专家的观点,量表的信度系数如果在0.9 以上,表示量表的信度甚佳。但是对于可接受的最小信度系数值是多少,许多专家的看法也不一致,有些专家定为0.8 以上,也有的专家定位0.7 以上。通常认为,如果研究者编制的量表的信度过低,如在0.6 以下,应以重新编制 较为适宜。 在本节中,主要介绍利用SPSS软件对量表进行因素分析。 一、因素分析基本原理 因素分析是通过求出量表的“结构效度”来对量表中因素关系作出判断。在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目的即在此。变量的第一个线性组合可以解释最大的变异量,排除前述层次,第二个线性组合可以解释次大的变异量,最后一个成份所能解释总变异量的部份会较少。 主成份数据分析中,以较少成份解释原始变量变异量较大部份。成份变异量通常用“特征值” 表示,有时也称“特性本质”或“潜在本质”。因素分析是一种潜在结构分析法,其模式理论中,假定每个指针(外在变量或称题项)均由两部分所构成,一为“共同因素”、一为“唯一因素”。共同因素的数目会比指针数(原始变量数)还少,而每个指针或原始变量皆有一个唯一因素,亦即一份量表共有n个题项数,则会有n个唯一因素。唯一因素性质有两个假定: (1)所有的唯一因素彼此间没有相关; (2)所有的唯一因素与所有的共同因素间也没有相关。 至于所有共同因素间彼此的关系,可能有相关或可能皆没有相关。在直交转轴状态下,所有的共同因素间彼此没有相关;在斜交转轴情况下,所有的共同因素间彼此就有相关。因素分析最 常用的理论模式如下: 其中
SPSS调查报告期末作业样本
----------- ------- ------- -------- --- ---------装------------ --------------------- - -------- 订 ----------------- ------- ------- -------- --线 - -------------- ------------------------- 班级 姓名 学号
二、调查目的 我们希望经过本次调查了解广东财经大学本部学生选择收费代课的原因, 以及对本专业学习、实习实践的认知程度, 是否支持放弃学习去实习或者做自己的事情, 是否支持收费代课。同时, 我们也希望经过这份调查报告揭露出的一些情况, 一方面, 帮助学生更好地权衡学习与实习的利弊, 更加理性地对待收费代课的行为, 做出对自己正确合适的选择; 另一方面, 引起学校对这种收费代课现象的重视, 给学校提一些建议, 希望学校采取一些措施改进这种不良校风。 三、调查方法 从可行性角度出发, 本次调查采用非概率随机抽样的街头拦截法, 集中对象为本部大三大四的同学, 以自愿形式对本部同学分发调查问卷, 总共发出80份问卷, 回收80份, 有效问卷80份。收集问卷之后, 利用spss软件进行数据整理与分析, 最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有: 频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表能够看出, 这次填写问卷的女生较多, 占了样本的66.3%, 这与我们学校男女比例不均衡有很大的关系, 样本的男女比例不相等, 也能够较好地接近学校的实际情况, 有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知, 参加问卷调查的大三大四学生比例明显比较高, 这与一开始我们预期相符, 样本中大三大四学生所占比例较多, 有利于我们得到更为有针对性的结论。
SPSS统计分析报告分析报告案例
SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费质量和消费结构都发生了明显的变化。城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势,其中食品类支出比重降幅最大;衣着类有所下降;家庭
应用统计spss分析报告
学生姓名:肖浩鑫学号:31407371 一、实验项目名称:实验报告(三) 二、实验目的和要求 (一)变量间关系的度量:包括绘制散点图,相关系数计算及显著性检验; (二)一元线性回归:包括一元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验,利用回归方程进行估计和预测; (三)多元线性回归:包括多元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验等,多重共线性问题与自变量选择,哑变量回归; 三、实验内容 企业编号产量(台)生产费用(万元)企业编号产量(台)生产费用(万元) 1 40 130 7 84 165 2 42 150 8 100 170 3 50 155 9 116 167 4 5 5 140 10 125 180 5 65 150 11 130 175 6 78 154 12 140 185 (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数,并对相关系数的显著性进行检验(),并说明二者之间的关系强度。 地区人均GDP(元)人均消费水平(元) 北京22460 7326 辽宁11226 4490 上海34547 11546 江西4851 2396 河南5444 2208 贵州2662 1608 陕西4549 2035
(1)绘制散点图,并计算相关系数,说明二者之间的关系。 (2)人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (3)计算判定系数和估计标准误差,并解释其意义。 (4)检验回归方程线性关系的显著性() (5)如果某地区的人均GDP为5000元,预测其人均消费水平。 (6)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 航空公司编号航班正点率(%)投诉次数(次) 1 81.8 21 2 76.6 58 3 76.6 85 4 75.7 68 5 73.8 74 6 72.2 93 7 71.2 72 8 70.8 122 9 91.4 18 10 68.5 125 (1)用航班正点率作自变量,顾客投诉次数作因变量,估计回归方程,并解释回归系数的意义。(2)检验回归系数的显著性()。 (3)如果航班正点率为80%,估计顾客的投诉次数。 4. 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果: 方差分析表 变差来源df SS MS F Significance F 回归 2.17E-09 残差40158.07 —— 总计11 1642866.67 ——— 参数估计表 Coefficients 标准误差t Stat P-value Intercept 363.6891 62.45529 5.823191 0.000168 X Variable 1 1.420211 0.071091 19.97749 2.17E-09 (1)完成上面的方差分析表。 (2)汽车销售量的变差中有多少是由于广告费用的变动引起的?