power designer物理数据模型

实验七 PowerDesigner物理数据模型
一、背景知识
1.物理数据模型概念
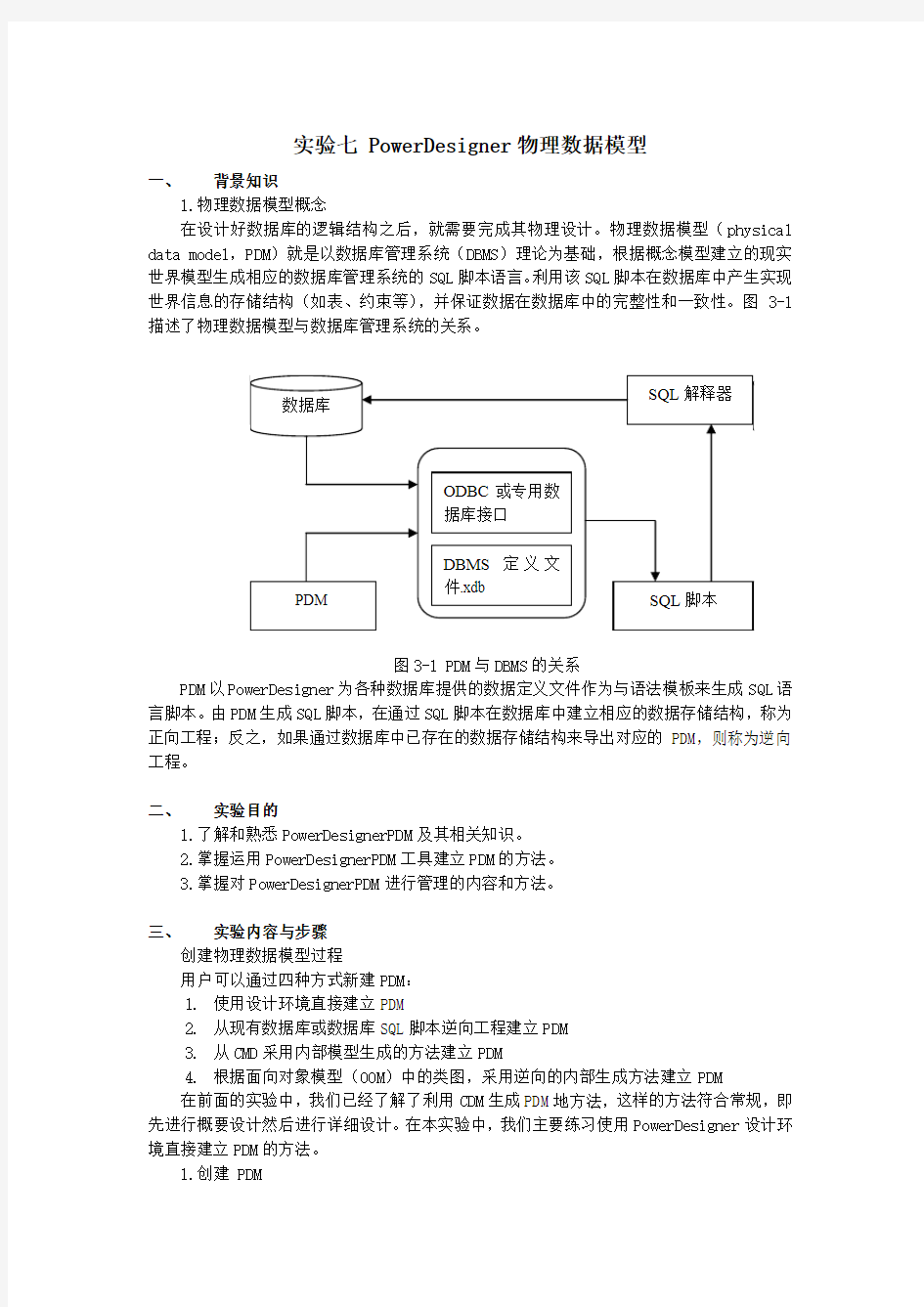
在设计好数据库的逻辑结构之后,就需要完成其物理设计。物理数据模型(physical data model,PDM)就是以数据库管理系统(DBMS)理论为基础,根据概念模型建立的现实世界模型生成相应的数据库管理系统的SQL脚本语言。利用该SQL脚本在数据库中产生实现世界信息的存储结构(如表、约束等),并保证数据在数据库中的完整性和一致性。图3-1描述了物理数据模型与数据库管理系统的关系。
图3-1 PDM与DBMS的关系
PDM以PowerDesigner为各种数据库提供的数据定义文件作为与语法模板来生成SQL语言脚本。由PDM生成SQL脚本,在通过SQL脚本在数据库中建立相应的数据存储结构,称为正向工程;反之,如果通过数据库中已存在的数据存储结构来导出对应的PDM,则称为逆向工程。
二、实验目的
1.了解和熟悉PowerDesignerPDM及其相关知识。
2.掌握运用PowerDesignerPDM工具建立PDM的方法。
3.掌握对PowerDesignerPDM进行管理的内容和方法。
三、实验内容与步骤
创建物理数据模型过程
用户可以通过四种方式新建PDM:
1.使用设计环境直接建立PDM
2.从现有数据库或数据库SQL脚本逆向工程建立PDM
3.从CMD采用内部模型生成的方法建立PDM
4.根据面向对象模型(OOM)中的类图,采用逆向的内部生成方法建立PDM
在前面的实验中,我们已经了解了利用CDM生成PDM地方法,这样的方法符合常规,即先进行概要设计然后进行详细设计。在本实验中,我们主要练习使用PowerDesigner设计环境直接建立PDM的方法。
1.创建 PDM
只有PDM才能生成应用程序的数据结构,数据结构的设计也可以直接从PDM的设计开始。使用设计环境直接建立PDM的方法如下:
步骤1:进入PowerDesigner,在File菜单中单击New命令,在打开的窗口中选择Physical Data Model。
步骤2:单击OK按钮,打开如图3-2所示窗口。
图3-2 选择DBMS及定义方式
从DBMS下拉列表框中选择一种目标DBMS,或单击DBMS栏右侧的Select a path按钮,选择包含扩展名为XML文件的目录。单击Share或Copy单选项,为新建的PDM选择使用DBMS 定义文件的方式。
步骤3:单击选择Extended Model Definitions页,显示如图3-3所示。
图3-3 扩展属性
如果要制定利用Power Builder来开发应用程序,应在此选中Power Builder复选框,这样,当Power Builder连接数据库时,会将表和列的扩展属性保存到其Catalog表中,生成的PDM可以从Catelog表中获取表和列的扩展属性。
步骤4:单击“确定”按钮,打开新建PDM的操作窗口,如图3-4所示。
图3-4 PDM操作窗口
步骤5:进一步地,利用Palette面板中的Table工具来创建表,利用Reference工具创建参照关系,利用View工具创建视图,利用Procedure工具创建存储过程等。其他工具与CDM中的工具栏使用方法一致。
(3)定义PDM的显示参数
在建立PDM前,需要定义PDM的显示参数,以满足不同的显示需求,使PDM能够更准确地描述系统信息。
定义PDM显示参数的具体方法是:
步骤1:在tools菜单中单击Display Preferences命令,窗口显示如图3-5所示,在General节点中设置整个模型的现实参数。
其中各个选项的含义是:
Windows color:窗口颜色。
Unit:长度度量单位。
Grid:网格线。Snap to grid(跳过网格)、Display(显示)、和size(网格线之间的间隔)。
Diagram:show page delimiter(显示分页线)。
图3-5 定义PDM显示参数
步骤2:在对话框左侧选择Content节点,设置在PDM图形窗口中每类对象的显示样式参数,如图3-6所示。
图3-6 显示样式参数
步骤3:在对话框左侧选择Format节点,设置每类对象的显示格式,如大小、边线颜色、填充颜色、阴影、字体等,如图3-7所示。
图3-7 对象的显示格式
步骤4:单击右下方的Modify按钮,可以进行更为详细的设置,如图3-8所示。
图3-8 对象的符号格式
(4)定义PDM的模型属性
修改PDM模型属性的操作方法是:
步骤1:在Model菜单中单击Model Properties命令,或者右键单击图形窗口的背景,在弹出的快捷菜单中选择Properties命令,打开PDM属性窗口,如图3-9所示。
图3-9 定义PDM的模型属性
步骤2:单击Database栏右侧的Create按钮,进入database Properties窗口,如图3-10所示。在该窗口中可以配置数据库选项。
图3-10 数据库属性窗口
2.创建表
PDM中的表与DBMS中存储的数据的表是同一个概念。表是PDM的基本出发点,表的设
计关系到PDM是否能正确反映客观世界。
创建表的方法是:
步骤1:在PDM窗口中选择Palette面板中的Table工具,并在窗口的空白区域单击,将在指定位置增加一个表的图形符号。
步骤2:在空白区域单击右键以释放表形状的光标。在双击窗口中表的图形符号,打开表属性窗口,如图3-11所示。
图3-11 表定义窗口
图3-12 列定义页
3.创建列
在PDM中创建的列包括计算列和序列。
(1)创建列
列是试题属性在数据库中的物理表现,PDM中的列等同于数据库表中的列。需要为每个列指定名称、代码及数据类型等基本属性。定义列的方法是:
步骤1:在表定义窗口中单击选择Column页,在其中键入列的节本属性,如图3-12所示。
步骤2:选中某一列(例如“作者编号”),右键单击Properties按钮,打开列属性定义窗口,如图3-13所示,其中定义列的其他属性。
图3-13 定义其他属性
在General页中可以定义以下属性:
Display:是否在图形符号中显示。
Foreign key:外部键。
Computed:计算列。
Identify:自增效列,即列中的数据是否可以自动增加。
步骤3:单击选择detail页,在其中可以定义通用的数据约束,如图3-14所示。
其中可以定义的属性包括:
Column file parameters:null values(允许空值列个数的百分比)、distinct values (允许不同值列个数的百分比)和average length(列值的平均长度)。
Test data parameters:profile(测试数据的取值)。单击右面的List按钮,可以进一步定义测试的取值方式,可以是字符型、数值型或日期/时间型
Computed expression:定义计算列表达式。
步骤4:定义完毕后,单击OK按钮返回。
图3-14 定义通用的数据约束
(2)创建计算列
计算力中存放通过表达是对其他列的值进行运算后得到的结果值,是一种特殊的列。
定义计算列的方法是:在列属性定义窗口的Details页中单击computed expression 编辑框右面的Edit按钮,弹出计算列表达式定义窗口,在其中定义计算表达式,如图3-15所示。
图3-15 计算列表达式定义窗口
(3)设置检查约束
在列属性定义窗口中选择Standard checks页,在其中定义检查约束,如图3-16所示。
图3-16 定义检查约束
(4)创建序列(Sequence)
前面介绍了列的基本属性中有一个Identify(自增效列)选项,含义是当表中增加一条记录时,列值会自动增加1。这样的列可以应用在一些特殊系统中,例如物资入库的流水号、商场的销售号等。序列则是特殊的自增效列,它允许定义一个复杂的增加方式。例如,可以定义介于两个数之间的、特定增量的一组数。序列的数据类型必须是数字型的。
序列的使用过程有两步,首先是定义一个序列,然后把它应用到列上。前提条件是当前DBMS必须支持序列。
注:https://www.sodocs.net/doc/6f11162890.html,/j2eeweiwei/article/details/6047691
4.创建参照及参照完整性
参照是父表和子表之间的连接,它定义了两个表中对应列之间的参照完整性约束,对应列是指主键(包括候选键)与外间或两个表中用户指定的两个列。当参照连接对应列后,子表中列的每一个值都引用父表中应对列的值。再参照中,对应列使用Join连接,根据主键、候选键、外键中包含的列的个数,一个参照可以包含一个或多个Join。
通常在主键或候选键和外键之间建立参照。根据参照连接对应列性质的不同,可把连接分成键之间的连接和用户指定列之间的连接。键之间的连接把父表中的主键或候选键连接到子表中的外键上;用户指定列之间的连接把父表中的一个或多个列连接到子表中相应的列上例如,如图3-17中的作品表和出版社表建立了参照联系。
图3-17 建立参照联系
出版社表(父表)中的主键“出版社编号”作为被参照列(
(1)设置参照相关的模型选项
模型选项决定了参照的特性。打开PDM,在Tools菜单中单击Model options命令,打开模型选项窗口,如图3-18所示。
图3-18 模型选项窗口
其中,Model节点以及其下节点可以用来设置模型的整体选项,包括:
1)Tablet&View:ignore identifying owner,不选则表示表或视图建立时,只有指定的属主(用户)可以修改,否则任何用户都可以修改。
2)Column&Domain:enforce non-divergence:列与域是否分离。与域相关的列的data type、check、rule、mandatory(强制)和profile(在目标数据库
中生成测试数据的描述文件)也可以随之改变。
3)Default data type:表示默认的数据类型。
4)Reference:unique code:表示模型中的参照代码唯一。
5)Auto-reuse Column:自动重用列。表示同父表主键拥有相同的代码和列或子表列,但不是其他表的外部键,则该列被当作子表的外部键。
6)Auto-migrate Columns:自动迁移列。表示产生参照表,父表的主键将迁移到子表中成为外部键。
7)Domain:表示如果选择了Auto-migrate Columns 和Domain,在建立参照时,主键的域将迁移到外部键上。
8)Check:表示如果选择了Auto-migrate Columns和check,在建立参照时,主
键的检查参数将迁移到外部键上。
9)Rules:表示如果选择了Auto-migrate Columns和Rules,在建立参照时,主键的业务规则将迁移到外部键上。
10)Default link on creation primary key:表示参照连接主键列到外部键列。
11)Default link on creation user-defined:表示参照不长生连接。
(2)创建参照及定义相关属性
步骤1:在PDM的Palette面板中,选择Reference(参照)工具。
在子表的图形符号内单击鼠标,然后拖拽鼠标至父表的图形符号内再释放,在子表和父表之间建立一个连接。
步骤2:双击新建立的连接,打开参照属性窗口,在其中可以修改参照的各个属性,如图3-19所示。
图3-19 定义参照属性
步骤3:Join(连接)可以用来连接主键、候选键和外部键,或在用户指定的列之间建立连接,如图3-20所示。
步骤4:连接可以通过设置模型选项自动建立,也可以手工建立。
步骤5:Integrity页可用来定义参照完整性。参照完整性是维护主键、候选键和外部键之间数据一致性的规则集合,表示父表中修改或删除参照列的数据对子表的影响。具体属性如图3-21所示。
图3-20 定义表与表之间的连接
图3-21 参照的属性
其中各个选项的含义是:
Constraint name:约束名。
Implementation:实现方式。
Declarative:把参照完整性约束定义成一种特殊的引用,在相应DBMS中,用于维护数据的有效性。
Trigger:通过触发器在相应DBMS中维护数据的有效性。
Cardinality:基数。表示父表中的每个实例,子表中可能拥有的实例的最少和最多数。
Update/delete constraint:表示修改父表列值后子表列值如何修改。
None:修改或删除父表,对子表无影响。
Restrict:如果子表中存在一个或多个对应值存在,不能修改或删除父表中的值。
Cascade:修改或删除父表中值的同时将子表中对应的值也修改或删除。
Set null:修改或删除父表中值的同时将子表中对应的值置为NULL。
Set default:修改或删除父表中值的同时将子表中对应的值置为默认值。
Mandatory parent:是否强制子表中的外部键列值都必须在父表中有相应的列值。
Check on commit:是否在提交时验证参照完整性。
Change parent allowed:是否允许提交时验证参照完整性。
步骤6:还可以修改参照图形符号上显示的文本信息,以满足不同系统的需求。方法是在PDM窗口中,在Tools菜单中单击Display References命令,打开display Reference 对话框,选择Content下的Reference节点,如图3-22所示。
图3-22 设置参照的文本信息
其中各个选项的含义是:
Name是参照的名称;constraint name参照完整性约束的名称;join是两个表相同列的联系名称;Reference integrity为参照完整性;cardinality为基数;implementation 为参照完整性实现的方式。其中,relational,连线的箭头指向父表;CODASYL,连线的箭
头指向子表;Conceptual,用一对多的方式显示基数。
5.创建域
在PDM中,使用域有助于识别信息的类型易于使用不同表中列的数据特征标准化,域为列定义了一组有效的值。可以把Data type、check、rule、mandatory等信息关联到域上。
创建域的具体方法是:
步骤1:打开PDM,在model菜单中单击Domain命令,打开list of Domains(显示域列表)窗口。
步骤2:在该窗口中单击空白行,可以增加一行,分别在name、code和data type栏中输入名称、代码和数据类型,如图3-23所示。
图3-23 域列表窗口
步骤3:双击新增加的行,可带开Domain Properties窗口,如图3-24所示。
图3-24 域属性定义窗口
其中general页中各个选项的含义是:name名称;code代码;Comment注释,data type 数据类型,length长度;precision精度;mandatory强制。
步骤4:除此之外,还可以定义standard check、additional check和rule等属性。
步骤5:单击data type选项右边的“?”按钮,可打开standard data type窗口,从中选择系统数据类型。
步骤6:单击ok,返回PDM窗口。
6.创建表中的域
键是表中可以唯一识别一条记录的一个或多个列的集合。PDM支持3种类型的键:主键、候选键、和外部键。
(1)主键
主键是表的主标识符,它可以是一个或多个列,列的值是唯一的。
定义主键的方法是:
步骤1:双击PDM模型中的某个表,打开table Properties窗口。
步骤2:选中作为主键列的P复选框,再单击“确定”按钮即可。
如果利用逆向工程,从已经存在的数据库逆向生成PDM模型,则可能无法生成主键或者在逆向工程数据库时没有选择重建主键选项,此时需要重建主键。
重建主键的方法是:
在Tools菜单中单击rebuild Object、rebuild primary key命令,打开primary key rebuild窗口,从中选择需要重建逐渐的复选框,然后单击“确定”按钮。如图3-25所示。
图3-25 重建表主键窗口
(2)外部键
外部键是值与主键匹配的一列或多列的组合。外部键的值应该是主表的主键值的拷贝,即在外部件中不应该有主键不存在的值。如果在CDM中定义了联系,在生成PDM时,将转化为外部键。根据需要,也可以修改、重建或迁移外部键。
(3)候选键
候选键只是一系列或多列,表中每条记录的列值都是唯一的。候选键不能是主键,但可以是外部键。每个候选键都在数据库中生成唯一索引或唯一约束。
定义候选键的方法与修改外部键地方法相同。
7.创建索引
建立索引可以为查询表提供多种存取途径,从而有效地提升查询速度。可以为相关的一列或多列建立索引,也可以为主键、候选键和外部键建立相应的索引。
建立索引的具体方法如下:
步骤1:在PDM窗口中,双击要建立索引的表,打开表的属性定义窗口,在其中选择indexes页。
步骤2:在name列或code列的空白行处单击,则可以增加一个新索引。系统自动给出索引的名称和代码,可以根据需要进行修改,如图3-26所示。
图3-26 表属性定义窗口的Indexes页
步骤3:单击Properties按钮,打开索引属性定义窗口,如图3-27所示。General页中所包含选项的多少与具体的DBMS有关.
其中主要有:name索引名称;code索引代码;Comment索引注释;owner索引的数据库属主;table包含索引的表;type索引的类型,包括unique(唯一索引)和cluster(聚簇索引)。唯一索引表示索引列不包含重复值,主键的索引都是唯一索引。聚簇索引表示索引项的顺序与表中记录的物理顺序相同。每个表只能建立一个聚簇索引。建立聚簇索引后,更新索引列中的数据时,记录的物理顺序需要变更,代价更大,所以聚簇索引适合建立在不常更新的列上。
图3-27 索引属性定义窗口
步骤4:选择Columns页,可以选择索引包含的列,如图3-28所示。
图3-28 索引列的属性定义窗口
步骤5:单击add Columns图标,打开如图3-29所示的选择列窗口。在窗口中列出了所有表中包含的列,可以从中选择一列或几列作为索引。
图3-29 索引列选择窗口
步骤6:单击OK按钮返回,在新增索引的sort列中选择ascending或descending的记录排列方式。
步骤7:单击“确定”按钮,关闭所有窗口,返回PDM窗口。
打开PDM窗口,在Tools菜单中单击rebuild indexes名令,可以重建索引。某个索引如果不在需要也可以将其删除。删除索引有两种方法:
1)从索引列表中删除索引。在model菜单中单击indexes命令,可以删除模型
中包含的索引。
2)从表中删除索引。在表的属性定义窗口的indexes页中,可以查看该表包含
的索引,利用delete图标即可删除索引。
8.创建视图
视图为用户提供了多种观察数据的角度,通过视图用户可以看到其它感兴趣的数据。视图是建立在一个或几个基本表或视图之上的虚拟表,实质上就是一个SQL查询语句。
为创建视图,可以先创建一个空视图,然后选择表或直接定义SQL语句。具体步骤是:步骤1:在PDM窗口中,选择palette面板中的View工具,并在窗口的空白区域单击鼠标,增加一个视图图形符号。双击该视图符号,打开视图属性窗口,在general页中可定义视图的基本属性,如图3-30所示。
其中general页中主要选项的含义是:
Name视图的名称;code视图的代码;usage视图的用途,query only表示查询数据;updateable查询和修改数据;with check options在视图插入数据时要受到表中已定义约束的限制。根据DBMS的不同,选项有所不同。Generation是否在数据库中生成视图;user_defined在用户自定义视图时,是否访问查询编辑器。
图3-30 General页
步骤2:选择SQL query页,为视图定义对应的SQL语句。如图3-31所示。标志间的连接方式包括:
图3-31 SQL Query页
Union:合并两个或多个Select语句,查询结果显示所有数据,重复值不显示。
Union All:合并两个或多个Select语句,查询结果显示所有数据和重复值。
Intersect:合并两个或多个Select语句,查询结果显示交集。
Minus:合并两个或多个select语句,查询结果显示补集。
步骤3:单击Query栏右侧的Edit按钮,打开SQL编辑器,在其中可以方便地书写SQL
数据仓库物理模型设计
数据仓库物理模型设计 数据仓库的物理模型就是数据仓库逻辑模型在物理系统中的实现模式。其中包括了逻辑模型中各种实体表的具体化,例如表的数据结构类型、索引策略、数据存放位置和数据存储分配等。在进行物理模型的设计实现时,所考虑的因素有:I/O存取时间、空间利用率及维护的代价。 为确定数据仓库的物理模型,设计人员必须做这样几方面工作:首先要全面了解所选用的数据库管理系统,特别是存储结构和存取方法;其次了解数据环境、数据的使用频率、使用方式、数据规模及响应时间要求等,这些都是对时间和空间效率进行平衡和优化的重要依据;最后还需要了解外部存储设备的特征。只有这样才能在数据的存储需求与外部存储设备条件两者之间获得平衡。 1 设计存储结构 在物理设计时,常常要按数据的重要性、使用频率及对反应时间的要求进行分类,并将不同类型的数据分别存储在不同的存储设备中。重要性高、经常存取并对反应时间要求高的数据存放在高速存储设备上;存取频率低或对存取响应时间要求低的数据则可以存放在低速存储设备上。另外,在设计时还要考虑数据在特定存储介质上的布局。在设计数据的布局时要注意遵循以下原则。 l 不要把经常需要连接的几张表放在同一存储设备上,这样可以利用存储设备的并行操作功能加快数据查询的速度。 l 如果几台服务器之间的连接会造成严重的网络业务量的问题,则要考虑服务器复制表格,因为不同服务器之间的数据连接会给网络带来沉重的数据传输负担。 l 考虑把整个企业共享的细节数据放在主机或其他集中式服务器上,提高这些共享数据的使用速度。 l 不要把表格和它们的索引放在同一设备上。一般可以将索引存放在高速存储设备上,而表格则存放在一般存储设备上,以加快数据的查询速度。 在对服务器进行处理时往往要进行大量的等待磁盘数据的工作,此时,可以在系统中使用RAID(Redundant Array of Inexpensive Disk,廉价冗余磁盘阵列)。 2 设计索引策略 数据仓库的数据量很大,因而需要对数据的存取路径进行仔细地设计和选择。由于数据仓库的数据一般很少更新,所以可以设计索引结构来提高数据存取效率。在数据仓库中,设计人员可以考虑对各个数据存储建立专用的索引和复杂的索引,以获取较高的存取效率,虽然建立它们需要付出一定的代价,但建立后一般不需要过多的维护。 数据仓库中的表通常要比联机事务处理系统(OLTP)中的表建立更多的索引,表中应用的最大索引数应与表格的规模成正比。数据仓库是个只读的环境,建立索引可以取得灵活性,对性能极为有利。但是表若有很多索引,那么数据加载时间就会延长,因此索引的建立需要进行综合的考虑。在建立索引时,可以按照索引使用的频率由高到低逐步添加,直到某一索引加入后,使数据加载或重组表的时间过长时,就结束索引的添加。 最初,一般都是按主关键字和大多数外部关键字建立索引,通常不要添加很多的其他索引。在表建立大量的索引后,对表进行分析等具体使用时,可能需要许多索引,这会导致表的维护时间也随之增加。如果从主关键字和外部关键字着手建立索引,并按照需要添加其他索引,就会避免首先建立大量的索引带来的后果。如果表格过大,而且需要另外增加索引,那么可以将表进行分割处理。如果一个表中所有用到的列都在索引文件中,就不必访问事实表,只要访问索引就可以达到访问数据的目的,以此来减少I/O操作。如果表太大,并且经常要对它进行长时间的扫描,那么就要考虑添加一张概括表以减少数据的扫描任务。 3 设计存储策略
高校图书管理系统数据库物理结构设计
高校图书管理系统数据库物理结构设计 一、设计前要了解的信息(该部分不出现在设计说明书中) 1、数据库的查询事务 (1)按卡号查询读者信息及借书信息(查询读者借书信息时涉及读者、图书与借还关系的连接操作,连接属性:卡号、书号)。 (2)按姓名查询读者信息及借书信息(查询读者借书信息时涉及读者、图书与借还关系的连接操作,连接属性:卡号、书号)。 (3)按书名查询图书信息。 (4)按作者与出版社查询图书信息。 (5)按出版社统计图书信息。 (6)按书号查询图书被借信息(查询图书被借信息时涉及读者、图书与借还关系的连接操作,连接属性:卡号、书号)。 (7)按书名查询图书被借信息(查询图书被借信息时涉及读者、图书与借还关系的连接操作,连接属性:卡号、书号)。 2、数据库的更新事务 (1)办理借书证(读者注册)。 (2)借书(增加借还记录、修改图书的库存数量)。 (3)还书(修改借还记录、修改图书的库存数量)。 3、查询事务的操作频率与性能要求 (1)按卡号查询读者信息及借书信息 操作频率:200次/天 性能要求:3s内完成 (2)按姓名查询读者信息及借书信息 操作频率:80次/天 性能要求:5s内完成 (3)按书名查询图书信息 操作频率:250次/天 性能要求:3s内完成 (4)按作者与出版社查询图书信息 操作频率:250次/天 性能要求:3s内完成 (5)按出版社统计图书信息 操作频率:1次/月 性能要求:10s内完成 (6)按书号查询图书被借信息 操作频率:10次/月
性能要求:6s内完成 (7)按书名查询图书被借信息 操作频率:10次/月 性能要求:6s内完成 二、设计结果 1、数据库名称 Book_Borrow 2、关系表 主键:lbdm 主键:kh 索引:xm(升序) check约束:性别的取值只能为男或女 default约束:性别默认为男
初中物理模型--最新版
初中物理模型--精选全解 一、电学模型(一) 模型口诀 先判串联和并联,电表测量然后判; 一路通底必是串,若有分支是并联; A 表相当于导线,并联短路会出现; 如果发现它并源,毁表毁源太凄惨; 若有电器与它并,电路发生局部短; V 表可并不可串,串时相当电路断; 如果发现它被串,电流为零应当然。 模型思考 你想知道常用、快捷、有效、正确识别电路连接方式的四种方法吗? 你会迅速、快捷、无误地判断出电路发生变化时电流表、电压表的示数如何变化吗? 你能根据实验现象或者题中给出的器材,准确、有效、方便的查找到电路中发生故障的原因吗? 模型归纳示图 去表法 串联电路 标电流法 并联电路 节点法 去元件法 正确识别电路办法 A V
明晰电压表电流表测量电路部分 部分电阻变化 总电阻变化 总电流变化 部分电流、部分电压、电表示数 电功、电功率 故障已给出 假设法 判断电路故障 电路图分析 故障未给出短路 串、并连接 断路 电器连接方式 使用注意 电表用途 判断电流电压示数
串、并联电路的识别方法 电路连接有两种基本方法──串联与并联。对于初学者要能够很好识别它们有点难度,下面结合串并联电路特点和实例,学习区别这两种电路的基本方法,希望对初学者有所帮助。 一、串联电路 如果电路中所有的元件是逐个顺次首尾连接起来的,此电路就是串联。我们常见装饰用的“满天星”小彩灯,就是串联的。家用电路中的开关与它所控制的用电器之间也是串联的。串联电路有以下一些特点: (1)电路连接特点:串联的整个电路只有一条电流的路径,各用电器依次相连,没有“分支点”。 (2)用电器工作特点:各用电器相互影响,电路中若有一个用电器不工作,其余的用电器就无法工作。 (3)开关控制特点:串联电路中的开关控制整个电路,开关位置变了,对电路的控制作用没有影响。即串联电路中开关的控制作用与其在电路中的位置无关。 二、并联电路 如果电器中各元件并列连接在电路的两点间,此电路就是并联电路。教室里的电灯、马路上的路灯、家庭中的电灯、电风扇、电冰箱、电视机等用电器之间都是并联在电路中的。并联电路有以下特点: (1)电路连接特点:并联电路由干路和几条支路组成,有“分支点”。每条支路各自和干路形成回路,有几条支路,就有几个回路。 (2)用电器工作特点:在并联电路中各用电器之间相不影响。某一条支路中的用电器若不工作,其他支路的用电器仍能工作。比如教室里的电灯,有一只烧坏,其它的电灯仍然能亮。这就是互不影响。 (3)开关控制特点:并联电路中,干路开关的作用与支路开关的作用不同。干路开关起着总开关的作用,控制整个电路。而各条支路开关只控制它所在的那条支路。 三、识别电路方法
概念模型、逻辑模型、物理模型区别(专业教育)
数据库设计 概念模型、逻辑模型、物理模型区别 侯在钱 目录 1.模型种类 (2) 1.1.概念模型 (2) 1.2.逻辑模型 (3) 1.3.物理模型 (3) 1.4.模型区别 (4) 1.4.1.对象转换 (4) 1.4.2.其它对比 (4) 2.常用工具 (5) 2.1.ERWIN (5) 2.1.1.逻辑模型 (5) 2.1.2.物理模型 (6) 2.1.3.常用操作 (6) 2.2.PowerDesigner (8) 2.2.1.概念模型 (8) 2.2.2.逻辑模型 (9) 2.2.3.物理模型 (9) 2.2.4.常用操作 (10)
1.模型种类 一般在建立数据库模型时,会涉及到几种模型种类:概念模型、逻辑模型、物理模型。数据库设计中概念模型和逻辑模型区别比较模糊,所以在数据库设计工具ERWIN中只提供了逻辑模型和物理模型,而在PowerDesigner早期版本中也只提供了概念模型和物理模型两种模型,只是在PowerDesigner15版本中提供了三种模型:概念模型、逻辑模型、物理模型。 1.1.概念模型 概念模型是对真实世界中问题域内的事物的描述,不是对软件设计的描述。 表示概念模型最常用的是"实体-关系"图。 E-R图主要是由实体、属性和关系三个要素构成的。在E-R图中,使用了下面几种基本的图形符号。 实体,矩形 E/R图三要素属性,椭圆形 关系,菱形
关系:一对一关系,一对多关系,多对多关系。 E/R图中的子类(实体): 子类is a 超类 1.2.逻辑模型 逻辑数据模型反映的是系统分析设计人员对数据存储的观点,是对概念数据模型进一步的分解和细化。 1.3.物理模型 物理模型是对真实数据库的描述。数据库中的一些对象如下:表,视图,字段,数据类型、长度、主键、外键、索引、是否可为空,默认值。 概念模型到物理模型的转换即是把概念模型中的对象转换成物理模型的对象。
概念数据模型,逻辑数据模型,物理数据模型 (原创)
概念数据模型设计与逻辑数据模型设计、物理数据模型设计是数据库及数据仓库模型设计的三个主要步骤。 在数据仓库领域有一个概念叫conceptual data model,中文一般翻译为“概念数据模型”。 概念数据模型是最终用户对数据存储的看法,反映了最终用户综合性的信息需求,它以数据类的方式描述企业级的数据需求,数据类代表了在业务环境中自然聚集成的几个主要类别数据。 概念数据模型的内容包括重要的实体及实体之间的关系。在概念数据模型中不包括实体的属性,也不用定义实体的主键。这是概念数据模型和逻辑数据模型的主要区别。 概念数据模型的目标是统一业务概念,作为业务人员和技术人员之间沟通的桥梁,确定不同实体之间的最高层次的关系。 在有些数据模型的设计过程中,概念数据模型是和逻辑数据模型合在一起进行设计的。 在数据仓库领域有一个概念叫logical data model,中文一般翻译为“逻辑数据模型”。 逻辑数据模型反映的是系统分析设计人员对数据存储的观点,是对概念数据模型进一步的分解和细化。逻辑数据模型是根据业务规则确定的,关于业务对象、业务对象的数据项及业务对象之间关系的基本蓝图。 逻辑数据模型的内容包括所有的实体和关系,确定每个实体的属性,定义每个实体的主键,指定实体的外键,需要进行范式化处理。 逻辑数据模型的目标是尽可能详细的描述数据,但并不考虑数据在物理上如何来实现。 逻辑数据建模不仅会影响数据库设计的方向,还间接影响最终数据库的性能和管理。如果在实现逻辑数据模型时投入得足够多,那么在物理数据模型设计时就可以有许多可供选择的方法。 在数据仓库领域有一个概念叫physical data model,中文一般翻译为“物理数据模型”。 物理数据模型是在逻辑数据模型的基础上,考虑各种具体的技术实现因素,进行数据库体系结构设计,真正实现数据在数据库中的存放。 物理数据模型的内容包括确定所有的表和列,定义外键用于确定表之间的关系,基于用户的需求可能进行发范式化等内容。在物理实现上的考虑,可能会导致物理数据模型和逻辑数据模型有较大的不同。
(pdm产品数据管理)物理数据模型(PDM)
物理数据模型(PDM) 本篇较简单,请读者先阅读上一篇(概念数据模型(CDM).doc)物理数据模型与数据库中建立表很像,最终可以生成数据库脚本 工具栏 1.表(Table) 2.存储过程(procedure) 3.视图(view) 4.关联(reference) 5.依赖(dependency) 创建项目工程 1.新建工程,选择“File->New Model”,弹出如图所示的对话框,选择Model types,在Model name中输入名称,单击“OK”按钮建立模型、如图所示 创建实体 1,在右侧的“图标窗口”中,单击工具箱上的“Entity”工具,在单击窗口的空白处,在单击的位置就数显了一个实体符号。单击“Pointer”工具或单击鼠标右键,可以释放Entity 工具,如图
. 2. 双击刚创建的实体集符号,弹出“实体属性”对话框,选择“General”属性页,在“Name”文本框中输入“users”、“Comment”中输入“用户实体”,如图 添加属性 1.在上述对话框中选择Attributes属性页。单击最左边的一个按钮“Insert a Row”,添 加新的属性。修改Name为userid,DataType为Integer,并把P、M上个复选框都打钩 (P列表示该属性是否为主标识符,主标识符类似于数据库中的主键;M列表示 改属性是否为强制的,打钩表示不能为空)
2,同理为“userlevel”实体添加如下属性,如图所示
定义属性的标准检查约束 1.在左侧的对象浏览器窗口中,选择“username”节点,双击该节点,弹出“username属 性设置”对话框,设置用户名的最小长度为6,最大长度为15,如图所示
数据仓库模型的设计.doc
2.5数据仓库模型的设计 数据仓库模型的设计大体上可以分为以下三个层面的设计151: .概念模型设计; .逻辑模型设计; .物理模型设计; 下面就从这三个层面分别介绍数据仓库模型的设计。 2.5.1概念模型设计 进行概念模型设计所要完成的工作是: <1>界定系统边界 <2>确定主要的主题域及其内容 概念模型设计的成果是,在原有的数据库的基础上建立了一个较为稳固的概念模型。因为数据仓库是对原有数据库系统中的数据进行集成和重组而形成的数据集合,所以数据仓库的概念模型设计,首先要对原有数据库系统加以分析理解,看在原有的数据库系统中“有什么”、“怎样组织的”和“如何分布的”等,然后再来考虑应当如何建立数据仓库系统的概念模型。一方面,通过原有的数据库的设计文档以及在数据字典中的数据库关系模式,可以对企业现有的数据库中的内容有一个完整而清晰的认识;另一方面,数据仓库的概念模型是面向企业全局建立的,它为集成来自各个面向应用的数据库的数据提供了统一的概念视图。 概念模型的设计是在较高的抽象层次上的设计,因此建立概念模型时不用考虑具体技术条件的限制。 1.界定系统的边界 数据仓库是面向决策分析的数据库,我们无法在数据仓库设计的最初就得到详细而明确的需求,但是一些基本的方向性的需求还是摆在了设计人员的面前: . 要做的决策类型有哪些?
. 决策者感兴趣的是什么问题? . 这些问题需要什么样的信息? . 要得到这些信息需要包含原有数据库系统的哪些部分的数据? 这样,我们可以划定一个当前的大致的系统边界,集中精力进行最需要的部分的开发。因而,从某种意义上讲,界定系统边界的工作也可以看作是数据仓库系统设计的需求分析,因为它将决策者的数据分析的需求用系统边界的定义形式反映出来。 2,确定主要的主题域 在这一步中,要确定系统所包含的主题域,然后对每个主题域的内容进行较明确数据仓库建模技术在电信行业中的应用的描述,描述的内容包括: . 主题域的公共码键; . 主题域之间的联系: . 充分代表主题的属性组。 2.5.2逻辑模型设计 逻辑建模是数据仓库实施中的重要一环,因为它能直接反映出业务部门的需求,同时对系统的物理实施有着重要的指导作用。在这一步里进行的工作主要有: . 分析主题域,确定当前要装载的主题; . 确定粒度层次划分; . 确定数据分割策略; . 关系模式定义; . 记录系统定义 逻辑模型设计的成果是,对每个当前要装载的主题的逻辑实现进行定义,并将相关内容记录在数据仓库的元数据中,包括: . 适当的粒度划分;
使用PowerDesinger创建数据库概念模型并转换为物理模型实例说明
1、在powerdesigner中进行数据库的概念设计(一) 一、概念数据模型概述 数据模型是现实世界中数据特征的抽象。数据模型应该满足三个方面的要求: 1)能够比较真实地模拟现实世界 2)容易为人所理解 3)便于计算机实现 概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。 通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系(Relationship),它并不依赖于具体的计 算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。 CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的静态特性、动态特性以及完整性约束条件等,其中包括了数据结构、数据操作和完整性约束三部分。 1)数据结构表达为实体和属性; 2)数据操作表达为实体中的记录的插入、删除、修改、查询等操作;
3)完整性约束表达为数据的自身完整性约束(如数据类型、检查、规则等)和数据间的参照完整性约束(如联系、继承联系等); 二、实体、属性及标识符的定义 实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。 每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。 实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。 实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。 实体类型中的每个实体包含唯一标识它的一个或一组属性,这些属性称为实体类型的标识符(Identifier),如“学号”是学生实体类型的标识符,“姓名”、“出生日期”、“信址”共同组成“公民”实体类型的标识符。
用PowerDesigner进行数据库物理模型设计
网上书店系统的数据库设计 需求分析名词(实体)动词(关系)用户能购买图书用户、图书购买 用户能评论图书用户、图书评论 能指定图书的类别图书、图书类别隶属 能指定用户的组用户、用户组隶属 用户组、功能权限 能指定用户组能使用 的功能 能指定购买项所属的 购买项、订单隶属 订单 3 Sept. 2008
3 Sept. 2008图书用户 用户组图书类别功能购买评论权限 隶属隶属
一、安装PowerDesigner建模软件 powerDesigner软件是Sysbase公司开发的,用于数据建模的软件。用它可对数据库进行建模。 二、用PowerDesigner为数据库建立概念模型(E-R模型) 三、用PowerDesigner为数据库建立物理模型 3 Sept. 2008
四、创建数据库 ①用powerDesigner创建数据库脚本 ②在企业管理器中创建数据库bookshop ③用数据库脚本创建bookshop库中的表 3 Sept. 2008
五、设计数据库总结 用powerDesigner设计数据库的步骤 步骤一:根据项目的需求分析设计数据库的E-R模型 项目的需求分析→ E-R模型 ?找出需求分析中的名词,这些名词是E-R模型中的实 体和实体中的属性→在E-R图中画实体和添加属性 ?找出需求分析中实体名词间的动词,这些动词是E-R 模型中实体间的关系→在E-R图中添加实体间的关系 3 Sept. 2008
用powerDesigner设计数据库的步骤 步骤二:根据已设计好的数据库的E-R模型生成对应的特定数据库的物理模型:E-R模型→物理模型 ?用tools->check model菜单项检查E-R模型的正确性, 如果有错误和警告应改正 ?用tools->Generate physical Data Model菜单项生成此 E-R模型的物理模型 3 Sept. 2008
oracle物理设计原则
数据库物理设计原则 1.1 数据库环境配置原则 1.1.1 操作系统环境: 对于中小型数据库系统,采用linux操作系统比较合适,对于数据库冗余要求负载均衡能力要求较高的系统,可以采用Oracle9i RAC的集群数据库的方法,集群节点数范围在2—64个。对于大型数据库系统,可以采用Sun Solaris SPARC 64位小型机系统或HP 9000 系列小型机系统。RAD5 适合只读操作的数据库,RAD1 适合OLTP数据库 1.1.2 内存要求 对于linux操作系统下的数据库,由于在正常情况下Oracle对SGA的管理能力不超过1.7G。所以总的物理内存在4G以下。SGA的大小为物理内存的50%—75%。对于64位的小型系统,Oracle数据库对SGA的管理超过2G的限制,SGA设计在一个合适的范围内:物理内存的50%—70%,当SGA过大的时候会导致内存分页,影响系统性能。 1.1.3 交换区设计 当物理内存在2G以下的情况下,交换分区swap为物理内存的3倍,当物理内存>2G的情况下,swap大小为物理内存的1—2倍。 1.1.4 其他环境变量参考Oracle相关的安装文档和随机文档。 1.2 数据库设计原则 1.2.1 数据库SID 数据库SID是唯一标志数据库的符号,命名长度不能超过5个字符。对于单节点数据库,以字符开头的5个长度以内字串作为SID的命名。对于集群数据库,当命名SID后,各节点SID自动命名为SIDnn,其中n n为节点号:1,2,…,64。例如rac1、rac2、rac24。 1.2.2 数据库全局名 数据库全局名称: 1.2.3 数据库类型选择
power designer物理数据模型
实验七 PowerDesigner物理数据模型 一、背景知识 1.物理数据模型概念 在设计好数据库的逻辑结构之后,就需要完成其物理设计。物理数据模型(physical data model,PDM)就是以数据库管理系统(DBMS)理论为基础,根据概念模型建立的现实世界模型生成相应的数据库管理系统的SQL脚本语言。利用该SQL脚本在数据库中产生实现世界信息的存储结构(如表、约束等),并保证数据在数据库中的完整性和一致性。图3-1描述了物理数据模型与数据库管理系统的关系。 图3-1 PDM与DBMS的关系 PDM以PowerDesigner为各种数据库提供的数据定义文件作为与语法模板来生成SQL语言脚本。由PDM生成SQL脚本,在通过SQL脚本在数据库中建立相应的数据存储结构,称为正向工程;反之,如果通过数据库中已存在的数据存储结构来导出对应的PDM,则称为逆向工程。 二、实验目的 1.了解和熟悉PowerDesignerPDM及其相关知识。 2.掌握运用PowerDesignerPDM工具建立PDM的方法。 3.掌握对PowerDesignerPDM进行管理的内容和方法。 三、实验内容与步骤 创建物理数据模型过程 用户可以通过四种方式新建PDM: 1.使用设计环境直接建立PDM 2.从现有数据库或数据库SQL脚本逆向工程建立PDM 3.从CMD采用内部模型生成的方法建立PDM 4.根据面向对象模型(OOM)中的类图,采用逆向的内部生成方法建立PDM 在前面的实验中,我们已经了解了利用CDM生成PDM地方法,这样的方法符合常规,即先进行概要设计然后进行详细设计。在本实验中,我们主要练习使用PowerDesigner设计环境直接建立PDM的方法。 1.创建 PDM
初中物理模型
一、电学模型(一) 模型口诀 先判串联和并联,电表测量然后判; 一路通底必是串,若有分支是并联; A 表相当于导线,并联短路会出现; 如果发现它并源,毁表毁源太凄惨; 若有电器与它并,电路发生局部短; V 表可并不可串,串时相当电路断; 如果发现它被串,电流为零应当然。 模型思考 你想知道常用、快捷、有效、正确识别电路连接方式的四种方法吗? 你会迅速、快捷、无误地判断出电路发生变化时电流表、电压表的示数如何变化吗? 你能根据实验现象或者题中给出的器材,准确、有效、方便的查找到电路中发生故障的原因吗? 模型归纳示图 去表法 串联电路 标电流法 并联电路 节点法 去元件法 正确识别电路办法
明晰电压表电流表测量电路部分 部分电阻变化 总电阻变化 总电流变化 部分电流、部分电压、电表示数 电功、电功率 故障已给出 假设法 判断电路故障 电路图分析 故障未给出短路 串、并连接 断路 电器连接方式 使用注意 电表用途 判断电流电压示数
串、并联电路的识别方法 电路连接有两种基本方法──串联与并联。对于初学者要能够很好识别它们有点难度,下面结合串并联电路特点和实例,学习区别这两种电路的基本方法,希望对初学者有所帮助。 一、串联电路 如果电路中所有的元件是逐个顺次首尾连接起来的,此电路就是串联。我们常见装饰用的“满天星”小彩灯,就是串联的。家用电路中的开关与它所控制的用电器之间也是串联的。串联电路有以下一些特点: (1)电路连接特点:串联的整个电路只有一条电流的路径,各用电器依次相连,没有“分支点”。 (2)用电器工作特点:各用电器相互影响,电路中若有一个用电器不工作,其余的用电器就无法工作。 (3)开关控制特点:串联电路中的开关控制整个电路,开关位置变了,对电路的控制作用没有影响。即串联电路中开关的控制作用与其在电路中的位置无关。 二、并联电路 如果电器中各元件并列连接在电路的两点间,此电路就是并联电路。教室里的电灯、马路上的路灯、家庭中的电灯、电风扇、电冰箱、电视机等用电器之间都是并联在电路中的。并联电路有以下特点: (1)电路连接特点:并联电路由干路和几条支路组成,有“分支点”。每条支路各自和干路形成回路,有几条支路,就有几个回路。 (2)用电器工作特点:在并联电路中各用电器之间相不影响。某一条支路中的用电器若不工作,其他支路的用电器仍能工作。比如教室里的电灯,有一只烧坏,其它的电灯仍然能亮。这就是互不影响。 (3)开关控制特点:并联电路中,干路开关的作用与支路开关的作用不同。干路开关起着总开关的作用,控制整个电路。而各条支路开关只控制它所在的那条支路。 三、识别电路方法 1.定义法:综合运用上面介绍串并联电路的连接特点及用电器工作特点,针对一些简单、规则的电路是行之有效的方法,也是其它方法的基础。 2.路径识别法:根据串并联电路连接特点,串联的整个电路只有一条电流的路径,如果有两条或两条以上的路径即为并联电路。 例题1如图1所示的电路,是判断连接方式是串联还是并联?
专题:物理模型的建立
物理模型法 目标:理解物理模型的建立在物理学习(特别是解题)中有十分广泛的应用,掌握平抛运动、圆周运动、碰撞、反冲、单摆等一系列物理模型的特点和研究方法,学会将研究对象简化成理想模型、将新的物理情景抽象成我们熟知的物理模型并加以解决,并且在解题中不断建立新的物理模型。 例题: 例题一 试估算金原子 Au 19779的大小,并从α粒子散射实验中估算金核的大小。设α粒子速度s m v /1060.1272-?=,质子质量kg m 271067.1-?=ρ,元电荷c e 191060.1-?=,静电引力恒量为229/100.9c m N k ??=,金的密度 33/103.19m kg ?=ρ,阿伏加德罗常数为1231002.6-?=mol N A ,已知试探电荷q 在距点电荷Q 为r 处时具有的电势能r kQq E /=ρ。(计算结果取一位有效数字) 解:金原子的摩尔体积为3533 1002.1103.1910197m M V --?=??==ρ 单个分子体积v=32910696.1m N V A -?= 设金原子直径为d ,则由36 1d v π=,代入数据后得m d 10101-?= 当α粒子最接近金核时,可以认为α粒子的速度几乎减小为零,此时有 r Qq k E v m ==ραα21 代入数据得14104-?=r m 点评:本题属于物质结构模型的建立。题中要估算金原子的直径,需建立原子的球体模型,用球体积最终求得分子的直径。而在研究金原子核半径时,应与α粒子与金原子核的最近距离作为金属原子核的半径。事实上,本题中粒子与金原子核在作用过程中,只有当两核速度相等时,距离最近。但考虑到金原子核的质量远大于粒质量,故近似的认为金原子核静止不动,这样的模型,虽简单但不影响本题的作答。 例题二 如图所示,小球的质量为m ,带电量为q ,整个区域加一个场强大小为E 的水平方向的匀强电场,小球系在长为L 的绳子的一端,且在与竖直方向成45°角的P 点处于平衡。则 (1)电场力多大? (2)如果小球被拉至与O 点在同一水平位置的C 点自由释放,则小球到达A 点的速度是多大?此时绳上的拉力又为多大? (3)在竖直平面内,如果小球以P 点为中心作微小的摆动,其振动周期如何求解? (4 )若使小球在此竖直平面内恰好做圆周运动时,最大速度和最小速度分别在哪点?大小例2图
物理模型的建构在初中生物教学中的应用
物理模型的建构在初中生物教学中的应用 物理模型的建构在初中生物教学中的应用 物理模型的建构在初中生物教学中的应用 2015-05-26 生物论文 物理模型的建构在初中生物教学中的应用 物理模型的建构在初中生物教学中的应用 吕国庆 (江苏省常州市新北区实验中学) 摘要:探讨在初中生物教学中常见的几种物理模型的建构。物理模型的设计非常有利于生物教学的有效开展,提高学生的学习效率,培养学生的各种技能和科学素养。 关键词:物理模型;创新;生物 人们认识客观世界的时候,直观化、形象化,更便于人们探索科学世界的客观规律。物理模型建构的研究旨在教学活动中建构学生的建模意识,物理模型建构的创新研究实质上是培养学生的创造性思维能力,因为建模活动本身就是一项创造性思维活动。能够培养学生的想象力,思维能力,假想、变换、构造等能力,这些能力正是创造性思维所具有的最基本的特征。“创新是一个民族的灵魂,是一个国家兴旺发达的不竭动力,创新的关键是人才,人才的成长靠教育。”要真
正培养学生的’创新能力,自觉地在学习过程中构建物理模型,只有这样,才能使学生分析和解决问题的能力得到有效提高,也只有这样才能真正提高学生的创新能力。 那什么是物理模型呢?物理模型就是以实物或图画形式直接表达认识事物的特征。根据相似原理,把真实事物制成相关模型,其状态变量和原事物基本相同,可以模拟客观事物的某些功能和性质。物理模型包括:实物模型、模拟模型、图画。通过下面以三个具体实例来阐述本人对物理模型的理解与探索。 一、模拟模型建构能将抽象化的知识活化为具体直观 主题举例:植物细胞的模型模拟建构。 材料的选择:一次性方型塑料盒,透明塑料袋,带壳核桃或熟鸡蛋,清水和有颜色的水,气球,不能水溶的绿色胶囊若干,长粒香大米若干粒。 设计方案:学生根据自己对植物细胞的结构和功能的理解,小组成员利用教师所提供的材料制作模型,小组成员展示模型并介绍,同时接受其他小组成员点评,并答疑。 具体实施过程:一次性塑料盒充当细胞壁,透明塑料袋可充当细胞膜,带壳核桃或熟鸡蛋可充当细胞核,清水可充当细胞质,气球可充当液泡,有颜色的水可充当细胞液。 评价:在班级内部交流小组制作模型,从科学性、技术性、正确性等方面进行评价。小组成员根据班内成员的评价完善自己的设计。 解释:模拟模型,就是根据系统或过程的特性,按一定规律,用实物材料模拟系统原型的方法。形象大于思维,七年级学生对细胞的认识较浅显,由于细胞很
概念数据模型,逻辑数据模型,物理数据模型
概念数据模型,逻辑数据模型,物理数据模型 概念数据模型设计与逻辑数据模型设计、物理数据模型设计是数据库及数据仓库模型设计的三个主要步骤。 在数据仓库领域有一个概念叫conceptual data model,中文一般翻译为“概念数据模型”。 概念数据模型是最终用户对数据存储的看法,反映了最终用户综合性的信息需求,它以数据类的方式描述企业级的数据需求,数据类代表了在业务环境中自然聚集成的几个主要类别数据。 概念数据模型的内容包括重要的实体及实体之间的关系。在概念数据模型中不包括实体的属性,也不用定义实体的主键。这是概念数据模型和逻辑数据模型的主要区别。 概念数据模型的目标是统一业务概念,作为业务人员和技术人员之间沟通的桥梁,确定不同实体之间的最高层次的关系。 在有些数据模型的设计过程中,概念数据模型是和逻辑数据模型合在一起进行设计的。 在数据仓库领域有一个概念叫logical data model,中文一般翻译为“逻辑数据模型”。 逻辑数据模型反映的是系统分析设计人员对数据存储的观点,是对概念数据模型进一步的分解和细化。逻辑数据模型是根据业务规则确定的,关于业务对象、业务对象的数据项及业务对象之间关系的基本蓝图。 逻辑数据模型的内容包括所有的实体和关系,确定每个实体的属性,定义每个实体的主键,指定实体的外键,需要进行范式化处理。 逻辑数据模型的目标是尽可能详细的描述数据,但并不考虑数据在物理上如何来实现。 逻辑数据建模不仅会影响数据库设计的方向,还间接影响最终数据库的性能和管理。如果在实现逻辑数据模型时投入得足够多,那么在物理数据模型设计时就可以有许多可供选择的方法。 在数据仓库领域有一个概念叫physical data model,中文一般翻译为“物理数据模型”。 物理数据模型是在逻辑数据模型的基础上,考虑各种具体的技术实现因素,进行数据库体系结构设计,真正实现数据在数据库中的存放。
数据库设计示例文档(完整)物理数据库设计
数据库设计示例文档(完整)物理数据库设计D2小组网上培训系统物理数据库设计 陈俊华、董磊、陈俊娜、董昊、海霞、郭云龙 1(针对选定的DBMS,生成基表 由于本系统主要架构在windows操作系统之上,加之本小组成员对SQLServer 比较熟悉,且系统有并发操作的要求,因此决定采用SQLServer2000 DBMS系统。 2(选择合适的文件组织(Heap, Hash, ISAM, B+ Tree, Clustered) 基于在System’s Specification中对系统性能的要求: 1)非峰值时,数据查找、更新、存储的平均时间低于1秒 2)在峰值时,数据查找、更新、存储的平均时间低于5秒 采用SQL Server 2000默认的文件组织结构 3(选择建立适当的索引 基于在System’s Specification中对事务处理的分析: 1)学生情况检索每天50次 2)教师情况检索每天10次 3)课程检索每天100次 4)常见问题检索每天200次 5)资料查询每天200次 6)试题检索每天50次 7)成绩查询每天50次 在SQL Server 2000里,在数据库关系图中为表定义一个主键将自动创建主键索引;由于要频繁查询学生姓名、教师姓名、课程名称、题目、成绩,因此在各表的对应列上创建第二索引。
4(定义全局约束 根据需求分析,本网上培训系统不允许同一名学生在一个学期中选课超过6 门以上。 5(定义视图 用户视图主要是学生视图和教师视图。 6(定义用户访问控制规则 用户在进入系统之前必须提交相应的用户名和口令,系统将根据不同的用户而授予不同的权限。 以下是建表语句: 1)学生表 create table student( StudentID Int(15) not null identity(1,1), StudentName Varchar(20) not null, StudentPassword Varchar(10) not null, StudentStatus Char(1) not null, StudentSex Char(1) not null, EnrollingDate Datetime not null, E-mail Varchar(30), Constraint pk_student primary key clustered(StudentID) ) 索引: create index student_StudentName on student(StudentName) 2)教师表 create table teacher (
物理模型设计大赛策划书
应用物理协会 物理模型设计大赛 策 划 书 主办: 皖西学院应用物理协会 承办:应用物理协会实验部,学术部和兴趣小组 二0一二年三月二十二日
一、活动名称 应用物理协会物理模型设计大赛 二、活动主题: 我型我秀 三、活动背景 阳春三月,鸟语花香,春意朦胧,正是展现我们大学生风采的美好时光。为使同学们在紧张的学习生活之余能够愉悦身心,丰富课余生活,展现大学生们年轻的活力。进一步引导大学生了解普及物理知识,鼓励同学们由理论引向实践,培养大学生的动手能力,达到增进友谊、共同提高的目的。应用物理协会决定举办集心灵,手巧于一体的物理模型大赛。让我们携起手来,共同动手展现我们的创造力吧! 四、活动目的 1、丰富同学们的课余生活,增强同学们的友谊,提高我校大学的创新意识,培养大学生的创新能力、实践能力和团结协作精神,培养同学的动脑动手及团队协调能力,进一步带动全校学生对物理模型的兴趣,促使他们积极参加各类创新活动及比赛,提高自己的创新能力。 2、为同学们提供展示自我和发挥自我能力的平台,巩固和强化同学们的专业知识和专业技能,激发创新意识。 3、通过相互之间的交流和学习,积累更多的知识,共同发展和进步。
4、营造浓厚的校园文化氛围,提高大学生的综合素质,促进当代大学生对生活的热爱,促进学生了解校园文化,更多的融入大学生活,都体验到亲身创作的乐趣。 五、活动内容 本次活动是针对全校学生的物理模型设计活动,利用身边一切可以利用的材料,以及所学的相关物理化学原理,手工设计出具有一定科技含量的物理模型作品(其中可以包括:建筑模型、机械模型、模型器具等等),通过现场操作演示,展示自己的作品,评出相应奖项。我们主要是鼓励大学生自主创新,利用所学所知,把理论与实践相结合起来。 七、活动时间 2012年3月30日 八、活动地点 (待定) 九、活动负责人 应用物理协会会长及承办部门主要负责人 十、参赛对象 全校所有院系全日制本科生 十一、活动流程 (一)前期安排 (1)前期活动宣传 1)做好各项工作的分工,并向本院系相关部门下发比赛的通知
数据库模型的概念、作用和三要素
数据库模型的概念、作用和三要素 模型是对现实世界的抽象。在数据库技术中,表示实体类型及实习类型间联系的模型成为“数据模型”。数据模型是数据库管理的教学形式框架,是用来描述一组数据的概念和定义的,包括三个方面: 1. 概念数据模型(Conceptual Model):这是面向数据库用户的实现世界的数据模型,主要用来描述世界的概念化结构,它使数据库的设计人员在设计的初始阶段,摆脱计算机系统及DBMS的具体技术问题,集中精力分析数据以及数据之间的联系等,与具体的DBMS无关。概念数据模型必须换成逻辑数据模型,才能在DBMS中实现。 2. 逻辑数据模型(Logical Data Model):这是用户从数据库看到的数据模型,是具体的DBMS 所支持的数据模型,如网状数据模型、层次数据模型等等。此模型既要面向用户,又要面向系统。 3. 物理数据模型(Physical Data Model):这是描述数据在存储介质上的组织结构的数据模型它不但与具体的DBMS有关,而且还和操作系统以及硬件有关。每一种逻辑数据模型在实现时都有其对应的物理数据模型。DBMS为了保证其独立性与可移植性,大部分物理数据模型的实现工作由系统自动完成,而设计者只设计索引、聚集等特殊结构。 数据模型的三要素: 一般而言,数据模型是一组严格定义的概念的集合。这些概念精确地描述了系统的静态特征(数据结构)、动态特征(数据操作)和完整性约束条件,这就是数据模型的三要素。 1. 数据结构 数据结构是所研究的对象类型的集合。这些对象是数据库的组成部分,数据结构指对象和对象间联系的表达和实现,是系统静态特征的描述,包括两个方面: (1)数据本身:类型、内容、性质。例如关系模型中的域、属性、关系等。 (2)数据之间的联系:数据之间是如何相互联系的,例如关系模型中的主码、外码等联系。 2. 数据操作 对数据库中对象的实例允许执行的操作集合,主要指检索和更新(插入、删除、修改)两类操作。数据模型必须定义这些操作的确切含义、操作符号、操作规则(如优先级)以及实现操作的语言。数据操作是对系统动态特征的描述。 3. 完整性约束条件 数据完整性约束是一组完整性规则的集合,规定数据库状态及状态变化所应满足的条件,以保证数据的正确性、有效性和相容性。
数据库物理设计
数据库物理设计 数据库环境 对于制造企业,一般可选用linux,Windows或Unix等操作系统。具体选择哪个操作系统可根据现有的服务器情况做调整。成熟的企业级数据仓库一般选择常见的关系型数据库,同时根据特殊要求,可增加集群数据库、内存关系数据库或本地文件型数据库等。数据存储可采用RAID5、RAID1、RAID5+RAID1的方式。内存配置通常在8G以上,来减少磁盘读取时间。 数据库参数设计 数据库类型:由于数据库目标位企业级数据仓库,数据库类型通常选择data warehouse类型。 连接方式:同时连接类型选择专用方式连接,来满足数据装载时的大量批处理服务。 内存配置:根据服务器实际物理内存的大小,选择70%-80%的内存作为数据库内存大小。 字符集:为了使数据库能够正确支持多国语言,需要将数据库字符集配置为UTF字符集。 其他参数:聚合内存使用,连接数、数据块大小、缓冲区设置等都需要根据实际数据量,使用方式来进行设置。 数据库存储设计 控制文件:控制文件中包含数据库重要信息,需要将控制文件存放在多个磁盘中,来保证数据库可恢复性。控制文
件中参数设置,最大的数据文件数量不能小于数据库参数db_files。 日志文件:数据仓库通常为批处理装载,在装载时会产生大量日志。可选择关闭某些事实表日志,对通常的维表及高频率装载的数据表,可以选择打开日志功能。日志文件的大小由数据库事务处理量决定,在设计过程中,确保每20分钟切换一个日志文件。对于数据仓库系统,日志文件大小通常为几百兆到几千兆。为了确保日志能够镜象作用,每日志组的成员为2个,日志文件组为5—10组。 回滚段配置:Undospace = UR * UPS * db_block_size + 冗余量。UR:表示在undo中保持的最长时间数(秒),由数据库参数UNDO_RETENTION值决定。UPS:表示在undo中,每秒产生的数据库块数量。 临时段表空间配置:数据库临时段表空间根据实际生产环境情况调整其大小,表空间属性为自动扩展。 系统表空间配置:系统表空间大小1G左右,除了存放数据库数据字典的数据外,其他数据不得存储在系统表空间。 表空间大小定义:当表空间大小小于操作系统对最大文件限制时,表空间由一个文件组成。如果表空间大小大于操作系统对最大文件限制时,该表空间由多个数据文件组成,表空间的总大小为估算为:Tablespace + sum (数据段+索引段)*150%。 表空间扩展性设计原则:表空间数据文件采用自动扩展的方式,扩展容量快大小按2的整数倍(1M、2M、4M、8M、16M、32M、64M)进行扩展,创建表空间时尽量采用nologing选项。表空间的最大限制一般采用unlimited,除非确切知道表空间数据文件的最大使用范围。(一般32
相关文档
- power designer物理数据模型
- 空间数据模型
- 概念模型逻辑模型物理模型区别hzq精编WORD版
- 初中物理模型--最新版
- 数据库系统第5章数据库物理模型
- 概念数据模型,逻辑数据模型,物理数据模型
- 物理数据模型
- 高中物理常见十种模型
- 初中物理模型解题法
- 概念模型、逻辑模型、物理模型区别(HZQ)
- 数据模型设计要点
- 数据仓库物理模型设计
- 管理信息系统--第八章-系统物理模型设计
- 概念数据模型设计与逻辑数据模型设计
- powerdesign建立物理数据模型
- 数据库 第5章数据库物理模型
- 物理数据模型(PDM)
- 概念模型 逻辑模型 物理模型区别 HZQ
- 数据库 第5章数据库物理模型
- 概念数据模型,逻辑数据模型,物理数据模型 (原创)