materials studio建模实例

数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.sodocs.net/doc/793219788.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.sodocs.net/doc/793219788.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
2003全国大学生数学建模竞赛b题参考答案
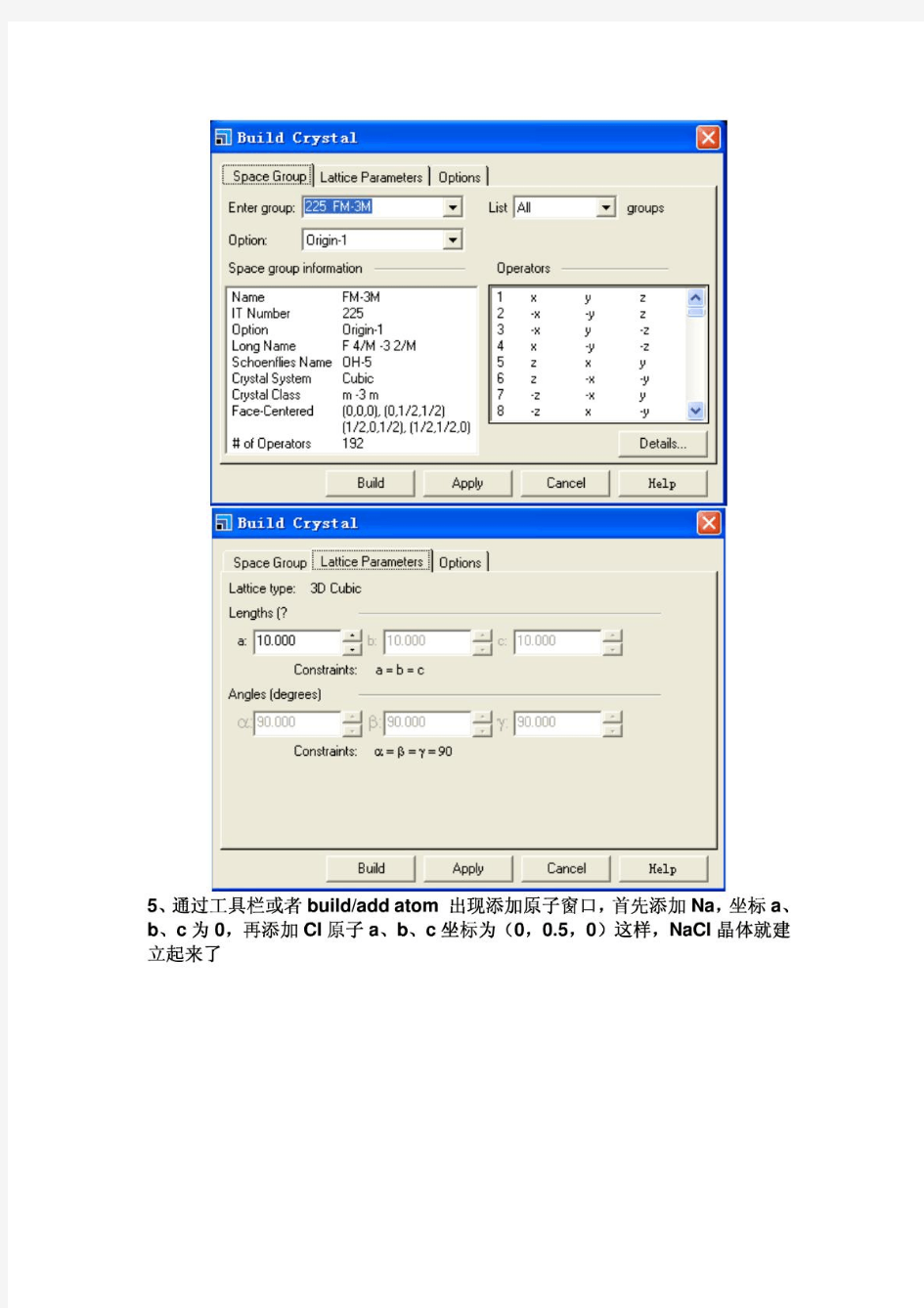
2003大学生数学建模竞赛 B 题参考答案 注意:以下答案是命题人给出的,仅供参考。各评阅组应根据对题目的理解及学生的解答,自主地进行评阅。 问题分析: 本题目与典型的运输问题明显有以下不同: 1. 运输矿石与岩石两种物资; 2. 产量大于销量的不平衡运输; 3. 在品位约束下矿石要搭配运输; 4. 产地、销地均有单位时间的流量限制; 5. 运输车辆每次都是满载,154吨/车次; 6. 铲位数多于铲车数意味着最优的选择不多于7个产地; 7. 最后求出各条路线上的派出车辆数及安排。 运输问题对应着线性规划,以上第1、2、3、4条可通过变量设计、调整约束条件实现; 第5条使其变为整数线性规划;第6条用线性模型实现的一种办法,是从1207 10 C 个整数规划中取最优的即得到最佳物流;对第7条由最佳物流算出各条路线上的最少派出车辆数(整数),再给出具体安排即完成全部计算。 对于这个实际问题,要求快速算法,计算含50个变量的整数规划比较困难。另外,这是一个二层规划,第二层是组合优化,如果求最优解计算量较大,现成的各种算法都无能为力。于是问题变为找一个寻求近优解的近似解法,例如可用启发式方法求解。 调用120次整数规划可用三种方法避免:(1)先不考虑电铲数量约束运行整数线性规划,再对解中运量最少的几个铲位进行筛选;(2)在整数线性规划的铲车约束中调用sign 函数来实现;(3)增加10个0-1变量来标志各个铲位是否有产量。 这是一个多目标规划,第一问的目标有两层:第一层是总运量(吨公里)最小,第二层是出动卡车数最少,从而实现运输成本最小。第二问的目标有:岩石产量最大;矿石产量最大;运量最小,三者的重要性应按此序。 合理的假设主要有: 1. 卡车在一个班次中不应发生等待或熄火后再启动的情况; 2. 在铲位或卸点处因两条路线(及以上)造成的冲突时,只要平均时间能完成任务即 可,不进行排时讨论; 3. 空载与重载的速度都是28km/h ,耗油相差却很大,因此总运量只考虑重载运量; 4. 卡车可提前退出系统。 符号:x ij ~ 从i 号铲位到j 号卸点的石料运量 单位 吨; c ij ~ 从i 号铲位到j 号卸点的距离 公里; T ij ~ 从i 号铲位到j 号卸点路线上运行一个周期平均所需时间 分; A ij ~ 从i 号铲位到j 号卸点最多能同时运行的卡车数 辆; B ij ~ 从i 号铲位到j 号卸点路线上一辆车最多可以运行的次数 次; p i ~ i 号铲位的矿石铁含量。 % p =(30,28,29,32,31,33,32,31,33,31)
通信系统建模与仿真课程设计
通信系统建模与仿真课程设计2011 级通信工程专业1113071 班级 题目基于SIMULINK的基带传输系统的仿真姓名学号 指导教师胡娟 2014年6月27日
1任务书 试建立一个基带传输模型,采用曼彻斯特码作为基带信号,发送滤波器为平方根升余弦滤波器,滚降系数为0.5,信道为加性高斯信道,接收滤波器与发送滤波器相匹配。发送数据率为1000bps,要求观察接收信号眼图,并设计接收机采样判决部分,对比发送数据与恢复数据波形,并统计误码率。另外,对发送信号和接收信号的功率谱进行估计。假设接收定时恢复是理想的。 2基带系统的理论分析 1.基带系统传输模型和工作原理 数字基带传输系统的基本组成框图如图1 所示,它通常由脉冲形成器、发送滤波器、信道、接收滤波器、抽样判决器与码元再生器组成。系统工作过程及各部分作用如下。 g T(t) n 定时信号 图 1 :数字基带传输系统方框图 发送滤波器进一步将输入的矩形脉冲序列变换成适合信道传输的波形g T(t)。这是因为矩形波含有丰富的高频成分,若直接送入信道传输,容易产生失真。 基带传输系统的信道通常采用电缆、架空明线等。信道既传送信号,同时又因存在噪声n(t)和频率特性不理想而对数字信号造成损害,使得接收端得到的波形g R(t)与发送的波形g T(t)具有较大差异。 接收滤波器是收端为了减小信道特性不理想和噪声对信号传输的影响而设置的。其主要作用是滤除带外噪声并对已接收的波形均衡,以便抽样判决器正确判决。 抽样判决器首先对接收滤波器输出的信号y(t)在规定的时刻(由定时脉冲cp控制)进行抽样,获得抽样信号{r n},然后对抽样值进行判决,以确定各码元是“1”码还是“0”码。 2.基带系统设计中的码间干扰和噪声干扰以及解决方案
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
系统建模与仿真
一、基本概念 1、数字正弦载波调制 在通信中不少信道不能直接传送基带信号,必须用基带信号对载波波形的某些参量进行控制,使得载波的这些参量随基带信号的变化而变化,即所谓数字正弦载波调制。 2、数字正弦载波调制的分类。 在二进制时, 数字正弦载波调制可以分为振幅键控(ASK)、移频键控(FSK)和移相键控(PSK)三种基本信号形式。如黑板所示。 2、高斯白噪声信道 二、实验原理 1、实验系统组成 2、实验系统结构框图
图 1 2FSK信号在高斯白噪声信道中传输模拟框图 各个模块介绍p12 3、仿真程序 x=0:15;% x表示信噪比 y=x;% y表示信号的误比特率,它的长度与x相同FrequencySeparation=24000;% BFSK调制的频率间隔等于24KHz BitRate=10000;% 信源产生信号的bit率等于10kbit/s SimulationTime=10;% 仿真时间设置为10秒SamplesPerSymbol=2;% BFSK调制信号每个符号的抽样数等于2 for i=1:length(x)% 循环执行仿真程序 SNR=x(i);% 信道的信噪比依次取中的元素 sim('project_1');% 运行仿真程序得到的误比特率保存在工作区变量BitErrorRate中 y(i)=mean(BitErrorRate); end hold off% 准备一个空白的图 semilogy(x,y);%绘制的关系曲线图,纵坐标采用对数坐标 三、实验结论
图 4 2FSK信号误比特率与信噪比的关系曲线图 系统建模与仿真(二) ——BFSK在多径瑞利衰落信道中的传输性能 一、基本概念 多径瑞利衰落信道 二、实验原理 1、实验系统组成
Material studio软件介绍
单击此处编辑母版标题样式
单击此处编辑母版文本样式 第二级 第三级 第四级 第五级
Materials Studio分子模拟软件
Version 2011
Copyright ?2010, Neotrident Technology Ltd. All rights reserved.
虚拟 “实验”(分子模拟技术)
C R E A T V I T Y
决定依据
单击此处编辑母版标题样式
单击此处编辑母版副标题样式
虚拟设计
表征材料结构,以及与结构相关的性质 —— 解释 设计材料结构,以及与结构相关的性质 —— 预测
Materials Studio是整合的计算模拟平台
? 可兼顾科研和教学需求 ? 可在大规模机群上进行并行计算 ? 客户端-服务器 计算方式 – Windows Linux Windows, – 最大限度的使用已有IT资源 – – – – – – – – DFT及半经验量子力学 线形标度量子力学 分子力学 QM/MM方法 介观模拟 统计方法 分析仪器模拟 …… ? 全面的应用领域 - 固体物理与表面化学 - 催化、分离与化学反应 - 半导体功能材料 - 金属与合金材料 - 特种陶瓷材料 - 高分子与软材料 - 纳米材料 - 材料表征与仪器分析 - 晶体与结晶 - 构效关系研究与配方设计 - ……
单击此处编辑母版标题样式 ? 包含多种计算方法
单击此处编辑母版副标题样式
Materials Studio?
Menu Toolbar
单击此处编辑母版标题样式 Property
View
单击此处编辑母版副标题样式
Job s us status
Project
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
Materials studio简介
Materials studio简介 1、诞生背景美国Accelrys公司的前身为四家世界领先的科学软件公司――美国Molecular Simulations Inc.(MSI)公司、Genetics Computer Group(GCG)公司、英国Synopsys Scient ific系统公司以及Oxford Molecular Group(OMG)公司,由这四家软件公司于2001年6月1日合并组建的Accelrys公司,是目前全球范围内唯一能够提供分子模拟、材料设计以及化学信息学和生物信息学全面解决方案和相关服务的软件供应商。 Accelrys材料科学软件产品提供了全面完善的模拟环境,可以帮助研究者构建、显示和分析分子、固体及表面的结构模型,并研究、预测材料的相关性质。Accelrys的软件是高度模块化的集成产品,用户可以自由定制、购买自己的软件系统,以满足研究工作的不同需要。Accelrys软件用于材料科学研究的主要产品包括运行于UNIX工作站系统上的Cerius2软件,以及全新开发的基于PC平台的Materials Studio软件。Accelrys材料科学软件被广泛应用于石化、化工、制药、食品、石油、电子、汽车和航空航天等工业及教育研究部门,在上述领域中具有较大影响的世界各主要跨国公司及著名研究机构几乎都是Accelrys产品的用户。 2、软件概况 Materials Studio是专门为材料科学领域研究者开发的一款可运行在PC上的模拟软件。它可以帮助你解决当今化学、材料工业中的一系列重要问题。支持Windows 98、2000、NT、Unix以及Linux等多种操作平台的Materials Studio使化学及材料科学的研究者们能更方便地建立三维结构模型,并对各种晶体、无定型以及高分子材料的性质及相关过程进行深入的研究。 多种先进算法的综合应用使Materials Studio成为一个强有力的模拟工具。无论构型优化、性质预测和X射线衍射分析,以及复杂的动力学模拟和量子力学计算,我们都可以通过一些简单易学的操作来得到切实可靠的数据。 Materials Studio软件采用灵活的Client-Server结构。其核心模块Visualizer运行于客户端PC,支持的操作系统包括Windows 98、2000、NT;计算模块(如Discover,Amorphous,Equilibria,DMol3,CASTEP等)运行于服务器端,支持的系统包括Windows2000、NT、SGIIRIX以及Red Hat Linux。浮动许可(Floating License)机制允许用户将计算作业提交到网络上的任何一台服务器上,并将结果返回到客户端进行分析,从而最大限度地利用了网络资源。 任何一个研究者,无论是否是计算机方面的专家,都能充分享用Materials Studio软件所带来的先进技术。Materials Studio生成的结构、图表及视频片断等数据可以及时地与其它PC软件共享,方便与其他同事交流,并能使你的讲演和报告更加引人入胜。 Materials Studio软件能使任何研究者达到与世界一流研究部门相一致的材料模拟的能力。模拟的内容包括了催化剂、聚合物、固体及表面、晶体与衍射、化学反应等材料和化学研究领域的主要课题。 3、模块简介 Materials Studio采用了大家非常熟悉的Microsoft标准用户界面,允许用户通过各种控制面板直接对计算参数和计算结果进行设置和分析。目前,Materials Studio软件包括如下功能模块: Materials Visualizer: 提供了搭建分子、晶体及高分子材料结构模型所需要的所有工具,可以操作、观察及分析结构模型,处理图表、表格或文本等形式的数据,并提供软件的基本环境和分析工具以及支持Materials Studio的其他产品。是Materials Studio产品系列的核心模块。
数据挖掘实验报告-关联规则挖掘
数据挖掘实验报告(二)关联规则挖掘 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1. 1.掌握关联规则挖掘的Apriori算法; 2.将Apriori算法用具体的编程语言实现。 二、实验设备 PC一台,dev-c++5.11 三、实验内容 根据下列的Apriori算法进行编程:
四、实验步骤 1.编制程序。 2.调试程序。可采用下面的数据库D作为原始数据调试程序,得到的候选1项集、2项集、3项集分别为C1、C2、C3,得到的频繁1项集、2项集、3项集分别为L1、L2、L3。
代码 #include 2012年北京师范大学珠海分校数学建模竞赛 题目:对中国大学生数学建模竞赛历年成绩的分析与预测 摘要 本文研究的是对自数学建模竞赛开展以来各高校建模水平的评价比较和预测问题。我们将针对题目要求,建立适当的评价模型和预测模型,主要解决对中国大学生数学建模竞赛历年成绩的评价、排序和预测问题。 首先我们用层次分析法来评价广东赛区各校2008年至2011年及全国各大高校1994至2011年数学建模成绩,从而给出广东赛区各校及全国各大高校建模成绩的科学、合理的评价及排序;其次运用灰色预测模型解决广东赛区各院校2012年建模成绩的预测。 针对问题一,首先我们对比了2008到2011年参加建模比赛的学校,通过分析我们选择了四年都参加了比赛的学校进行合理的排序(具体分析过程见表13),同时对本科甲组和专科乙组我们分别进行排序比较。在具体解决问题的过程中,我们先分析得出影响评价结果的主要因素:获奖情况和获奖比例,其中获奖情况主要考虑国家一等奖、国家二等奖、省一等奖、省二等奖、省三等奖,我们采用层次分析法,并依据判断尺度构造出各个层次的判断矩阵,对它们逐个做出一致性检验,在一致性符合要求的情况下,通过公式与matlab求得各大学的权重,总结得分并进行排序(结果见表11);在对广东赛区各高校2012建模成绩预测问题中,我们采用灰色预测模型,我们以华南农业大学为例,得到该校2012年建模比赛获奖情况为:省一等奖、省二等奖、省三等奖及成功参赛奖分别为5、9、8、8(其它各高校预测结果见表10)。 针对问题二,我们对全国各院校的自建模竞赛活动开展以来建模成绩排序采用与问题一相同的数学模型,在获奖情况考虑的是全国一等奖、全国二等奖。运用matlab求解,结果见表12。 针对问题三,我们通过对一、二问排序的解答及数据的分析,得出在对院校进评价和预测时还应考虑到各院的师资力量、学校受重视程度、学生情况、参赛经验等因素,考虑到这些因素,为以后评价高校建模水平提供更可靠的依据。 关键词:层次分析法权向量灰色预测模型模型检验 matlab 系统建模与仿真项目驱动设计报告 学院:电气工程与自动化学院 专业班级:自动化143班 学号:2420142928 学生姓名:李荣 指导老师:杨国亮 时间:2016年6月10号 仿真技术是一门利用物理模型或数学模型模拟实际环境进行科学实验的技术,具有经济、可靠、实用、安全、灵活和可多次重复使用的优点。 本文中将使用Matlab软件实现一个简单的控制系统仿真演示,可实现对一些连续系统的数字仿真、连续系统按环节离散化的数字仿真、采样控制系统的数字仿真以及系统的根轨迹、伯德图、尼克尔斯图和奈氏图绘制。 本设计完成基本功能的实现,基于Matlab的虚拟实验仿真的建立和应用,培养了我们的兴趣,提高了我们的实践能力。 关键字:Matlab;系统数字仿真;根轨迹;伯德图。 第一章概述 (4) 1.1 设计目的 (4) 1.2 设计要求 (4) 1.3设计内容 (4) 第二章 Matlab简介 (6) 2.1 Matlab的功能特点 (6) 2.2 Matlab的基本操作 (6) 第三章控制系统仿真设计 (8) 3.1 控制系统的界面设计 (8) 3.2 控制系统的输入模型设计 (9) 3.3 欧拉法的Matlab实现 (12) 3.4 梯形法的Matlab实现 (14) 3.5 龙格-库塔法的Matlab实现 (15) 3.6 双线性变换法的Matlab实现 (16) 3.7 零阶保持器法的Matlab实现 (17) 3.8 一阶保持器法的Matlab实现 (18) 3.9 系统PID控制的Matlab实现 (19) 3.10 系统根轨迹的绘制 (21) 3.11系统伯德图的绘制 (22) 3.12系统尼克尔斯图的绘制 (23) 一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff) 对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮: 全国大学生数学建模竞赛论文格式规范 (全国大学生数学建模竞赛组委会,2018年修订稿) 为了保证竞赛的公平、公正性,便于竞赛活动的标准化管理,根据评阅工作的实际需要,竞赛要求参赛队分别提交纸质版和电子版论文,特制定本规范。 一、纸质版论文格式规范 第一条,论文用白色A4纸打印(单面、双面均可);上下左右各留出至少2.5厘米的页边距;从左侧装订。 第二条,论文第一页为承诺书,第二页为编号专用页,具体内容见本规范第3、4页。 第三条,论文第三页为摘要专用页(含标题和关键词,但不需要翻译成英文),从此页开始编写页码;页码必须位于每页页脚中部,用阿拉伯数字从“1”开始连续编号。摘要专用页必须单独一页,且篇幅不能超过一页。 第四条,从第四页开始是论文正文(不要目录,尽量控制在20页以内);正文之后是论文附录(页数不限)。 第五条,论文附录至少应包括参赛论文的所有源程序代码,如实际使用的软件名称、命令和编写的全部可运行的源程序(含EXCEL、SPSS等软件的交互命令);通常还应包括自主查阅使用的数据等资料。赛题中提供的数据不要放在附录。如果缺少必要的源程序或程序不能运行(或者运行结果与正文不符),可能会被取消评奖资格。论文附录必须打印装订在论文纸质版中。如果确实没有源程序,也应在论文附录中明确说明“本论文没有源程序”。 第六条,论文正文和附录不能有任何可能显示答题人身份和所在学校及赛区的信息。 第七条,引用别人的成果或其他公开的资料(包括网上资料)必须按照科技论文写作的规范格式列出参考文献,并在正文引用处予以标注。 第八条,本规范中未作规定的,如排版格式(字号、字体、行距、颜色等)不做统一要求,可由赛区自行决定。在不违反本规范的前提下,各赛区可以对论文增加其他要求。 二、电子版论文格式规范 第九条,参赛队应按照《全国大学生数学建模竞赛报名和参赛须知》的要求命名和 2007年全国大学生数学建模竞赛题目 [日期:2009-11-05] 阅读:307 次 A 题:中国人口增长预测 中国是一个人口大国,人口问题始终是制约我国发展的关键因素之一。根据已有数据,运用数学建模的方法,对中国人口做出分析和预测是一个重要问题。近年来中国的人口发展出现了一些新的特点,例如,老龄化进程加速、出生人口性别比持续升高,以及乡村人口城镇化等因素,这些都影响着中国人口的增长。2007 年初发布的《国家人口发展战略研究报告》(附录1) 还做出了进一步的分析。关于中国人口问题已有多方面的研究,并积累了大量数据资料。附录2就是从《中国人口统计年鉴》上收集到的部分数据。试从中国的实际情况和人口增长的上述特点出发,参考附录2中的相关数据(也可以搜索相关文献和补充新的数据),建立中国人口增长的数学模型,并由此对中国人口增长的中短期和长期趋势做出预测;别要指出你们模型中的优点与不足之处。 B题:乘公交,看奥运 我国人民翘首企盼的第29届奥运会明年8月将在北京举行,届时有大量观众到现场观看奥运比赛,其中大部分人将会乘坐公共交通工具(简称公交,包括公汽、地铁等)出行。这些年来,城市的公交系统有了很大发展,北京市的公交线路已达800条以上,使得公众的出行更加通畅、便利,但同时也面临多条线路的选择问题。针对市场需求,某公司准备研制开发一个解决公交线路选择问题的自主查询计算机系统。 为了设计这样一个系统,其核心是线路选择的模型与算法,应该从实际情况出发考虑,满足查询者的各种不同需求。请你们解决如下问题:1、仅考虑公汽线路,给出任意两公汽站点之间线路选择问题的一般数学模型与算法。并根据附录数据,利用你们的模型与算法,求出以下6对起始站→终到站之间的最佳路线(要有清晰的评价说明)。 (1)、S3359→S1828 (2)、S1557→S0481 (3)、S0971→S0485 (4)、S0008→S0073 (5)、S0148→S0485 (6)、S0087→S3676 2、同时考虑公汽与地铁线路,解决以上问题。 3、假设又知道所有站点之间的步行时间,请你给出任意两站点之间线路选择问题的数学模型。 某某大学 《电力系统建模及仿真课程设计》总结报告 题目:基于MATLAB的电力系统短路故障仿真于分析 姓名 学号 院系 班级 指导教师 摘要:本次课程设计是结合《电力系统分析》的理论教学进行的一个实践课程。 电力系统短路故障,故障电流中必定有零序分量存在,零序分量可以用来判断故障的类型,故障的地点等,零序分量作为电力系统继电保护的一个重要分析量。运用Matlab电力系统仿真程序SimPowerSystems工具箱构建设计要求所给的电力系统模型,并在此基础上对电力系统多中故障进行仿真,仿真波形与理论分析结果相符,说明用Matlab对电力系统故障分析的有效性。实际中无法对故障进行实验,所以进行仿真实验可达到效果。 关键词:电力系统;仿真;短路故障;Matlab;SimPowerSystems Abstract: The course design is a combination of power system analysis of the theoretical teaching, practical courses. Power system short-circuit fault, the fault current must be zero sequence component exists, and zero-sequence component can be used to determine the fault type, fault location, the zero-sequence component as a critical analysis of power system protection. SimPowerSystems Toolbox building design requirements to the power system model using Matlab power system simulation program, and on this basis, the power system fault simulation, the simulation waveforms with the theoretical analysis results match, indicating that the power system fault analysis using Matlab effectiveness. Practice can not fault the experiment, the simulation can achieve the desired effect. Keywords: power system; simulation; failure; Matlab; SimPowerSystems - 1 - 目录 一、引言 ............................................ - 3 - 目录 第0章绪论 (1) 0.1 计算机材料设计的概念 (1) 0.2 计算机材料设计的发展 (1) 0.3 计算机材料设计的途径 (2) 第1章快速启动教程 (1) 1.1 创建项目(Creating a project) (1) 1.2 打开、浏览3D文档 (2) 1.3 绘制苯甲酰胺(benzamide)分子 (4) 1.4 用学习表文档进行浏览和工作 (8) 1.5 研究分子晶体:尿素 (11) 1.6 建立α-quartz晶体 (12) 1.7 建立聚甲基丙烯酸甲酯(methyl methacrylate) (14) 1.8 保存项目、结束本教程 (15) 第2章VISUALIZER 教程 (16) 2.1 项目管理 (16) 2.2 绘制简单的分子 (21) 2.3 绘制卟啉(porphyrin) (30) 2.4 绘制有机金属结构 (36) 2.5 覆盖和对齐分子 (43) 2.6 精确定位和移动原子 (46) 2.7 在表面对接分子 (49) 2.8 使用polymer builder (54) 2.9 使用layer builder (65) 2.10 使用crystal builder (72) 2.11 建立中尺度分子 (81) 2.12 用Analog Builder枚举库 (84) 2.13 用等位面(isosurfaces)和切片工作(slices) (88) 2.14 域隔离和分析 (94) 第3章ADSORPTION LOCATOR、BLENDS教程 (98) 3.1 用Adsorption Locator决定SO2在Ni(111)晶面上的位置 (98) 3.2 共混聚合物相容性筛选 (101) 第4章AMORPHOUS CELL教程 (108) Materials Studio是Accelrys专为材料科学领域开发的可运行于PC机上的新一代材料计算软件,可帮助研究人员解决当今化学及材料工业中的许多重要问题。Materials Studio 软件采用Client/Server结构,客户端可以是Windows 98、2000或NT系统,计算服务器可以是本机的Windows 2000或NT,也可以是网络上的Windows 2000、Windows NT、Linux或UNIX系统。使得任何的材料研究人员可以轻易获得与世界一流研究机构相一致的材料模拟能力。 Materials Studio 由分子模拟软件界的领先者--美国ACCELRYS公司在2000年初推出的新一代的模拟软件Materials Studio,将高质量的材料模拟带入了个人电脑(PC)的时代。 Materials Studio是ACCELRYS 公司专门为材料科学领域研究者所涉及的一款可运行在PC上的模拟软件。他可以帮助你解决当今化学、材料工业中的一系列重要问题。支持Windows98、NT、Unix以及Linux等多种操作平台的Materials Studio使化学及材料科学的研究者们能更方便的建立三维分子模型,深入的分析有机、无机晶体、无定形材料以及聚合物。 任何一个研究者,无论他是否是计算机方面的专家,都能充分享用该软件所使用的高新技术,他所生成的高质量的图片能使你的讲演和报告更引人入胜。同时他还能处理各种不同来源的图形、文本以及数据表格。 多种先进算法的综合运用使Material Studio成为一个强有力的模拟工具。无论是性质预测、聚合物建模还是X射线衍射模拟,我们都可以通过一些简单易学的操作来得到切实可靠的数据。灵活方便的Client-Server结构还是的计算机可以在网络中任何一台装有NT、Linux或Unix操作系统的计算机上进行,从而最大限度的运用了网络资源。 ACCELRYS的软件使任何的研究者都能达到和世界一流工业研究部门相一致的材料模拟的能力。模拟的内容囊括了催化剂、聚合物、固体化学、结晶学、晶粉衍射以及材料特性等材料科学研究领域的主要课题。 Materials Studio采用了大家非常熟悉Microsoft标准用户界面,它允许你通过各种控制面板直接对计算参数和计算结构进行设置和分析。 模块简介: 基本环境 MS.Materials Visualizer 分子力学与分子动力学 MS.DISCOVER https://www.sodocs.net/doc/793219788.html,PASS 实验一 ID3算法实现 一、实验目的 通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。加深对相关算法的理解过程。 实验类型:验证 计划课间:4学时 二、实验内容 1、分析决策树算法的实现流程; 2、分析信息增益的计算、数据子集划分、决策树的构建过程; 3、根据算法描述编程实现算法,调试运行; 4、对所给数据集进行验算,得到分析结果。 三、实验方法 算法描述: 以代表训练样本的单个结点开始建树; 若样本都在同一个类,则该结点成为树叶,并用该类标记; 否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性; 对测试属性的每个已知值,创建一个分支,并据此划分样本; 算法使用同样的过程,递归形成每个划分上的样本决策树 递归划分步骤,当下列条件之一成立时停止: 给定结点的所有样本属于同一类; 没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行 四、实验步骤 1、算法实现过程中需要使用的数据结构描述: Struct {int Attrib_Col; // 当前节点对应属性 int Value; // 对应边值 Tree_Node* Left_Node; // 子树 Tree_Node* Right_Node // 同层其他节点 Boolean IsLeaf; // 是否叶子节点 int ClassNo; // 对应分类标号 }Tree_Node; 2、整体算法流程 主程序: InputData(); T=Build_ID3(Data,Record_No, Num_Attrib); OutputRule(T); 释放内存; 3、相关子函数: 3.1、 InputData() { 输入属性集大小Num_Attrib; 输入样本数Num_Record; 分配内存Data[Num_Record][Num_Attrib]; 输入样本数据Data[Num_Record][Num_Attrib]; 获取类别数C(从最后一列中得到); } 3.2、Build_ID3(Data,Record_No, Num_Attrib) { Int Class_Distribute[C]; If (Record_No==0) { return Null } N=new tree_node(); 计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0; For (i=0;i对中国大学生数学建模竞赛历年成绩的分析与预测
系统建模与仿真项目驱动设计报告
大数据挖掘weka大数据分类实验报告材料
2018全国大学生数学建模大赛模板
2007年全国大学生数学建模竞赛题目
电力系统建模及仿真课程设计
MaterialsStudio教程
Materials Studio是Accelrys专为材料科学领域开发的可运行于PC机上的新一代材料计算软件
数据挖掘实验报告1