应用回归分析课后习题参考答案 全部版 何晓群,刘文卿

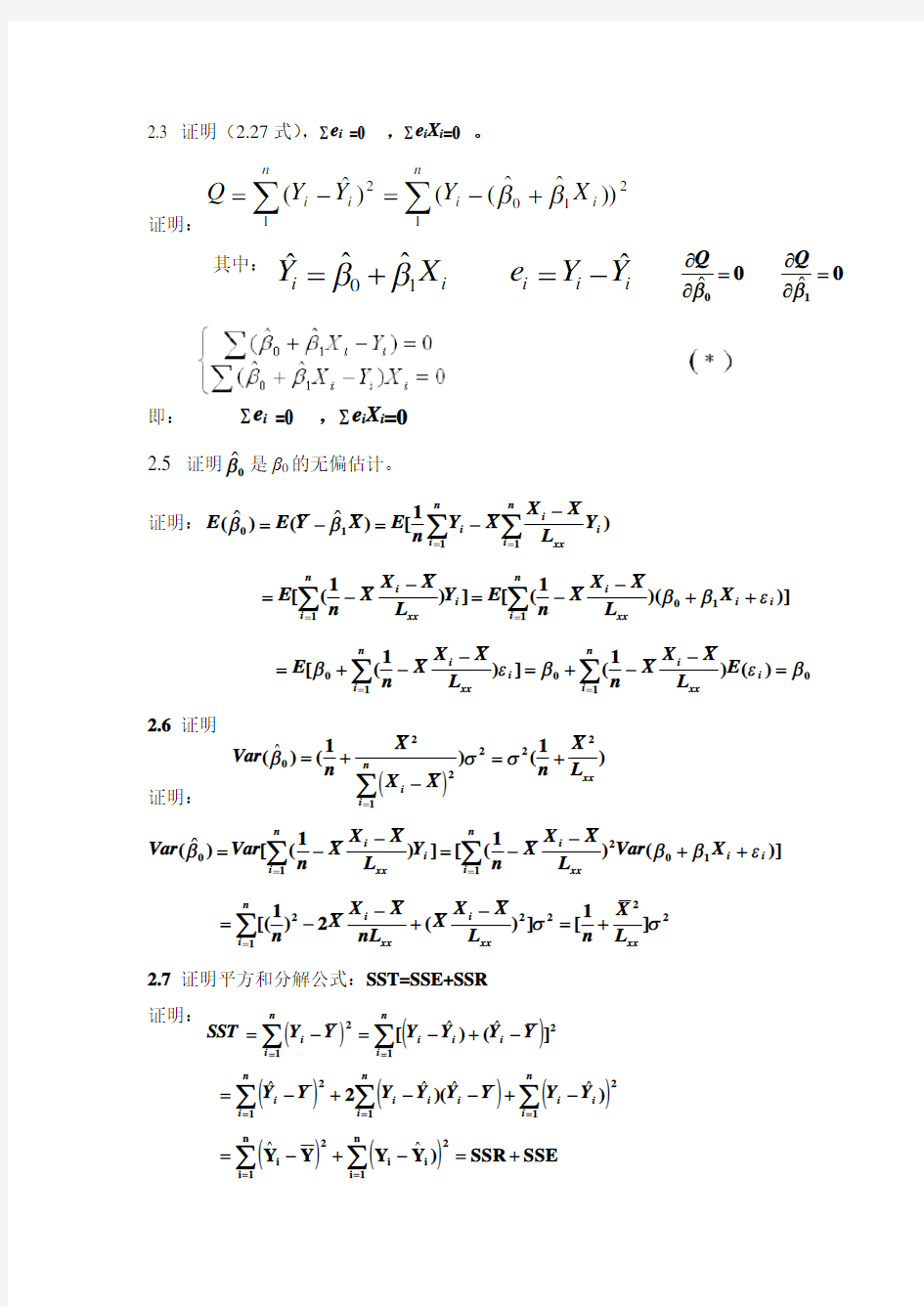
第一章回归分析概述
1.2 回归分析与相关分析的联系与区别是什么?
答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。区别有 a.
在回归分析中,变量y称为因变量,处在被解释的特殊地位。在相关分析中,变
量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x
与变量y的密切程度是一回事。b.相关分析中所涉及的变量y与变量x全是随机
变量。而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以
是非随机的确定变量。C.相关分析的研究主要是为了刻画两类变量间线性相关的
密切程度。而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归
方程进行预测和控制。
1.3回归模型中随机误差项ε的意义是什么?
答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为
一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,
由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,
随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑
的种种偶然因素。
1.4 线性回归模型的基本假设是什么?
答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值
xi1.xi2…..xip是常数。2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^2
3.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,
即n>p.
第二章一元线性回归分析
思考与练习参考答案
2.1一元线性回归有哪些基本假定?
答:假设1、解释变量X是确定性变量,Y是随机变量;
假设2、随机误差项ε具有零均值、同方差和不序列相关性:
E(εi)=0 i=1,2, …,n
Var (εi)=σ2i=1,2, …,n
Cov(εi,εj)=0 i≠j i,j= 1,2, …,n
假设3、随机误差项ε与解释变量X之间不相关:
Cov(X i, εi)=0 i=1,2, …,n
假设4、ε服从零均值、同方差、零协方差的正态分布
εi~N(0, σ2) i=1,2, …,n
2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
证明:
其中:
即: ∑e i =0 ,∑e i X i =0
2.5 证明0
?β是β0的无偏估计。 证明:)1[)?()?(1
110∑∑==--=-=n
i i xx i n i i
Y L X X X Y n E X Y E E ββ )] )(1
([])1([1011i i xx i n i i xx i n
i X L X X X n E Y L X X X n E εββ++--=--=∑∑==
1010)()1
(])1([βεβεβ=--+=--+=∑∑==i xx i n
i i xx i n
i E L X X X n
L X X X n E 2.6 证明 证明:
)] ()1([])1([)?(102110i i xx i n
i i xx i n
i X Var L X X X n
Y L X X X n Var Var εβββ++--=--=∑∑== 2
22212]1[])(2)1[(σσxx
xx i xx i n
i L X n L X X X nL X X X n +=-+--=∑=
2.7 证明平方和分解公式:SST=SSE+SSR
证明:
∑∑+-=-=n
i
i i n i X Y Y Y Q 1
2102
1))??(()?(ββ01????i i i i i
Y X e Y Y ββ=+=-()
)
1()1()?(2
2
2
1
2
2
xx n
i i
L X n X X
X n
Var +=-+=∑=σσβ()()
∑∑==-+-=-=n i i
i i n i i Y Y Y Y Y Y SST 1212
]?()?[()
()
()
∑∑∑===-+--+-=n
i i
i n
i i i i n
i i
Y Y Y Y Y Y Y Y 1
2
1
12
)??)(?2?(
)()
SSE
SSR )Y ?Y Y Y ?n
1
i 2
i
i n
1
i 2i +=-+-=∑∑
==0
1
00??Q
Q
β
β
??==?
?
2.8 验证三种检验的关系,即验证: (1)2
1)2(r r n t --=
;(2)22
21
??)2/(1/t L n SSE SSR F xx ==-=σ
β 证明:(1)
?t ======
(2)
2
2222011111
1
1
1
??????()()(())(())n
n
n
n
i i
i i xx i i i i SSR y y x y y x x y x x L βββββ=====-=+-=+--=-=∑∑∑∑2212?/1
?/(2)xx L SSR F t SSE n βσ
∴===-
2.9 验证(2.63)式:2
211σ)L )x x (n ()e (Var xx i i ---=
证明:
11
222
2
222
???var()var()var()var()2cov(,)???var()var()2cov(,())()()11[]2[]()1[1]i i i i i i i i
i
i
i
i i xx xx
i xx
e y y
y y y y y x y y x x x x x x n L n L x x n L β
ββσσσσ
=-=+-=++-+---=++-+-=--
其中:2
22221111))(1()(1)
)(,()()1,())(?,(),())(?,(σσσββxx
i xx i n
i i xx
i i i n
i i i i
i i i i L x x n L x x n y L x x y Cov x x y n y Cov x x y Cov y y Cov x x y y Cov -+=-+=--+=-+=-+∑∑==
2.10 用第9题证明是σ2的无偏估计量
证明:
2?22
-=
∑n e
i
σ
2
2
211
221122
11??()()()22()111var()[1]221
(2)2
n n i i i i n n i i i i xx E E y y E e n n x x e n n n L n n σσσσ=====-=---==----=-=-∑∑∑∑ 第三章
1.一个回归方程的复相关系数R=0.99,样本决定系数R 2=0.9801,我们能判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。因为:
1. 在样本容量较少,变量个数较大时,决定系数的值容易接近1,而此时可能F 检验或者关于回归系数的t 检验,所建立的回归方程都没能通过。
2. 样本决定系数和复相关系数接近于1只能说明Y 与自变量X1,X2,…,Xp 整体上的线性关系成立,而不能判断回归方程和每个自变量是显著的,还需进行F 检验和t 检验。
3. 在应用过程中发现,在样本容量一定的情况下,如果在模型中增加解释变量必定使得自由度减少,使得 R 2往往增大,因此增加解释变量(尤其是不显著的解释变量)个数引起的R 2的增大与拟合好坏无关。
2
1
??*,1,2,...,)n
jj j i j p
L X β
====-∑j
j
i j 其中: (X
2.被解释变量Y 的期望值与解释变量k X X X ,,,21 的线性方程为:
01122()k k E Y X X X ββββ=++++ (3-2)
称为多元总体线性回归方程,简称总体回归方程。
对于n 组观测值),,2,1(,,,,21n i X X X Y ki i i i =,其方程组形式为:
01122,(1,2,,)
i i i k ki i Y X X X i n ββββμ=+++++=
(3-3) 即
??????
?+++++=+++++=+++++=n
kn k n n n k k k k X X X Y X X X Y X X X Y μββββμββββμββββ 221102
2222121021121211101 其矩阵形式为
????????????n Y Y Y 21=?
?
?????
??
???kn n
n
k k X X X X X X
X X X
212221212111111???????
?
????????k ββββ 210+?
???????????n μμμ 21 即
=+Y X βμ
(3-4)
其中
=?1
n Y ?
???
?
?
??????n Y Y Y 2
1为被解释变量的观测值向量;=+?)1(k n X ?
?
???????
???kn n
n k k X X X X X X X X X
21222
1212111111为解释变量的观测值矩阵;(1)1k +?=β?????
??
?????????k ββββ 210为总体回归参数向量;1n ?=
μ????
?
?
??????n μμμ 21为随机误差项向量。 多元回归线性模型基本假定:课本P57
第四章
4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与
方法。
答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。
加权最小二乘法的方法:
4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。
答:运用加权最小二乘法消除多元线性回归中异方差性的思想与一元线性回归的类似。多元线性回归加权最小二乘法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为:
22011
1
???()()N N
w i i i i i i
i i Q w y y w y x ββ===-=--∑∑22
__
1
_
2
_
_
02
222
()()
?()?1
11
1
,i i N
w i
i
i w i w
i w
w
w w w kx i i
i i
m
i i i m
i
w x
x y y x x y x w kx x kx w x σβββσσ==---=-=
=
===∑∑1N i =1
1表示=或
∑=----=n
i ip p i i i p w x x y w Q 1
211010)( ),,,(ββββββ
(2)
加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差平方和w Q 达极小。所得加权最小二乘经验回归方程记做
p
pw w w w x x y βββ????110+++= (3) 多元回归模型加权最小二乘法的方法:
首先找到权数i w ,理论上最优的权数i w 为误差项方差2i σ的倒数,即
2
1
i
i w σ
=
(4)
误差项方差大的项接受小的权数,以降低其在式(2)平方和中的作用; 误差项方差小的项接受大的权数,以提高其在平方和中的作用。由(2)式求出的
加权最小二乘估计pw w w βββ?,,?,?10 就是参数p βββ,,,10 的最小方差线性无偏估计。
一个需要解决的问题是误差项的方差2i σ是未知的,因此无法真正按照式(4)选取权数。在实际问题中误差项方差2i σ通常与自变量的水平有关(如误差项方差
2i σ随着自变量的增大而增大),可以利用这种关系确定权数。例如2i σ与第j 个自
变量取值的平方成比例时, 即2i σ=k 2
ij x 时,这时取权数为
21
ij
i x w =
(5) 更一般的情况是误差项方差2i σ与某个自变量j x (与|e i |的等级相关系数最大
的自变量)取值的幂函数m ij x 成比例,即2i σ=k m
ij x ,其中m 是待定的未知参数。此
时权数为
m ij
i x w 1
=
(6) 这时确定权数i w 的问题转化为确定幂参数m 的问题,可以借助SPSS 软件解决。
第五章
5.3 如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣?答:如果所建模型主要用于预测,则应使用
C统计量达到最小的准则来衡量回
p
归方程的优劣。
5.4 试述前进法的思想方法。
答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm建立m个一元线性回归方程, 并计算F检验值,选择偏回归平方和显著的变量(F值最大且大于临界值)进入回归方程。每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的两变量变量(F值最大且大于临界值)进入回归方程。在确定引入的两个自变量以后,再引入一个变量,建立m-2个三元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的三个变量(F值最大)进入回归方程。不断重复这一过程,直到无法再引入新的自变量时,即所有未被引入的自变量的F检验值均小于F检验临界值Fα(1,n-p-1),回归过程结束。
5.5 试述后退法的思想方法。
答:后退法的基本思想是:首先因变量Y对全部的自变量x1,x2,...,xm建立一个m元线性回归方程, 并计算t检验值和F检验值,选择最不显著(P值最大且大于临界值)的偏回归系数的自变量剔除出回归方程。每一步只剔除一个变量,再建立m-1元线性回归方程,计算t检验值和F检验值,剔除偏回归系数的t检验值最小(P值最大)的自变量,再建立新的回归方程。不断重复这一过程,直到无法剔除自变量时,即所有剩余p个自变量的F检验值均大于F检验临界值F α(1,n-p-1),回归过程结束。
第六章
消除多重共线性的方法
7.2岭回归的定义及统计思想是什么?
答:岭回归法就是以引入偏误为代价减小参数估计量的方差的一种回归方法,其统计思想是对于(X’X)-1为奇异时,给X’X加上一个正常数矩阵D, 那么X’X+D 接近奇异的程度就会比X′X接近奇异的程度小得多,从而完成回归。但是这样
的回归必定丢失了信息,不满足blue 。但这样的代价有时是值得的,因为这样可以获得与专业知识相一致的结果。
7.3 选择岭参数k 有哪几种方法?
答:最优k 是依赖于未知参数β和2σ的,几种常见的选择方法是: ○
1岭迹法:选择0k 的点能使各岭估计基本稳定,岭估计符号合理,回归系数没有不合乎经济意义的绝对值,且残差平方和增大不太多; ○2方差扩大因子法:11()()()c k X X kI X X X X kI --'''=++,其对角线元
()jj c k 是岭估计的方差扩大因子。要让()10jj c k ≤; ○
3残差平方和:满足()SSE k cSSE <成立的最大的k 值。
7.4 用岭回归方法选择自变量应遵循哪些基本原则? 答:岭回归选择变量通常的原则是:
1. 在岭回归的计算中,我们通常假定涉及矩阵已经中心化和标准化了,这
样可以直接比较标准化岭回归系数的大小。我们可以剔除掉标准化岭回归系数比较稳定且绝对值很小的自变量;
2. 当k 值较小时,标准化岭回归系数的绝对值并不很小,但是不稳定,随
着k 的增加迅速趋近于零。像这样岭回归系数不稳定、震动趋于零的自变量,我们也可以予以剔除;
3. 去掉标准化岭回归系数很不稳定的自变量。如果有若干个岭回归系数不
稳定,究竟去掉几个,去掉那几个,要根据去掉某个变量后重新进行岭回归分析的效果来确定。
8章
主成分回归建模的思想与步骤 偏最小二乘建模的思想与步骤 两个论述,在课本上
应用回归分析课后习题
y1 1 x11 x12 x1p 0 1 3.1 y2 1 x21 x22 x2p 1 + 2 即y=x + yn 1 xn1 xn2 xnp p n 基本假定 (1)解释变量x1,x2…,xp 是确定性变量,不是随机变量,且要求 rank(X)=p+1 n 注 tr(H) h 1 3.4不能断定这个方程一定很理想,因为样本决定系数与回归方程中 自变量的数目以及样本量n 有关,当样本量个数n 太小,而自变量又较 多,使样本量与自变量的个数接近时, R 2易接近1,其中隐藏一些虚 假成分。 3.5当接受H o 时,认定在给定的显着性水平 下,自变量x1,x2, xp 对因变量y 无显着影响,于是通过x1,x2, xp 去推断y 也就无多大意 义,在这种情况下,一方面可能这个问题本来应该用非线性模型去描 述,而误用了线性模型,使得自变量对因变量无显着影响;另一方面 可能是在考虑自变量时,把影响因变量y 的自变量漏掉了,可以重新 考虑建模问题。 当拒绝H o 时,我们也不能过于相信这个检验,认为这个回归模型 已经完美了,当拒绝H o 时,我们只能认为这个模型在一定程度上说明 了自变量x1,x2, xp 与自变量y 的线性关系,这时仍不能排除排除我 们漏掉了一些重要的自变量。 3.6中心化经验回归方程的常数项为0,回归方程只包含p 个参数估计 值1, 2, p 比一般的经验回归方程减少了一个未知参数,在变量较 SSE (y y)2 e12 e22 1 2 1 E( ) E( - SSE* n p 1 n p n 2 [D(e) (E(e))2] 1 n (1 1 n 2 en n E( e 1 1 n p 1 1 n p 1 1 "1 1 n p 1 J (n D(e) 1 (p 1)) 1_ p 1 1 1 n p 1 2 2 n E(e 2) (1 h ) 2 1 《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院 一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++ 上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见 中级经济师基础知识 第 1题:单选题(本题1分) 某公司产品当产量为1000单位时,其总成本为4000元;当产量为2000单位时,其总成本为5000,则设产量为x,总成本为y,正确的一元回归方程表达式应该是( )。 A、y = 3000 + x B、y = 4000 + 4x C、y = 4000 + x D、y = 3000 + 4x 【正确答案】:A 【答案解析】: 本题可列方程组:设该方程为y = a + bx,则由题意可得:4000 = a + 1000b5000 = a + 2000b 解该方程,得b=1,a=3000,所以方程为y = 3000 + x 第 2题:单选题(本题1分) 在回归分析中,估计回归系数的最小二乘法的原理是( )。 A、使得因变量观测值与均值之间的离差平方和最小 B、使得因变量估计值与均值之间的离差平方和最小 C、使得观测值与估计值之间的乘积和最小 D、使得因变量观测值与估计值之间的离差平方和最小 【正确答案】:D 【答案解析】: 较偏较难的一道题目。最小二乘法就是使得因变量的观测值与估计值之间的离差平方和最小来估计参数的一种方法 第 3题:多选题(本题2分) 关于相关分析和回归分析的说法,正确的的有() A、相关分析可以从一个变量的变化来推测另一个变量的变化 B、相关分析研究变量间相关的方向和相关的程度 C、相关分析中需要明确自变量和因变量 D、回归分析研究变量间相互关系的具体形式 E、相关分析和回归分析在研究方法和研究目的有明显区别 【正确答案】:BDE 【答案解析】: 相关分析与回归分析在研究目的和方法上具有明显的区别。 (1)、相关分析研究变量之间相关的方向和相关的程度,无法从一个变量的变化来推测另一变量的变化情况。 (2)、回归分析是研究变量之间相关关系的具体形式 第8章 非线性回归 思考与练习参考答案 8.1 在非线性回归线性化时,对因变量作变换应注意什么问题? 答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。如: (1) 乘性误差项,模型形式为 e y AK L αβε =, (2) 加性误差项,模型形式为y AK L αβ ε = + 对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。 一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。 8.2为了研究生产率与废料率之间的关系,记录了如表8.15所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。 表8.15 生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%) 5.2 6.5 6.8 8.1 10.2 10.3 13.0 解:先画出散点图如下图: 5000.00 4000.003000.002000.001000.00x 12.00 10.00 8.006.00 y 从散点图大致可以判断出x 和y 之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。 (1)二次曲线 SPSS 输出结果如下: Model Summ ary .981 .962 .942 .651 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x. ANOVA 42.571221.28650.160.001 1.6974.424 44.269 6 Regression Residual Total Sum of Squares df Mean Square F Sig.The independent variable is x. Coe fficients -.001.001-.449-.891.4234.47E -007.000 1.417 2.812.0485.843 1.324 4.414.012 x x ** 2 (Constant) B Std. E rror Unstandardized Coefficients Beta Standardized Coefficients t Sig. 从上表可以得到回归方程为:72? 5.8430.087 4.4710y x x -=-+? 由x 的系数检验P 值大于0.05,得到x 的系数未通过显著性检验。 由x 2的系数检验P 值小于0.05,得到x 2的系数通过了显著性检验。 (2)指数曲线 Model Summ ary .970 .941 .929 .085 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x. 应用回归分析课后答案 第二章一元线性回归 解答:EXCEL结果: SUMMARY OUTPUT 回归统计 Multiple R R Square Adjusted R Square 标准误差 观测值5 方差分析 df SS MS F Significance F 回归分析125 残差3 总计410 Coefficients标准误差t Stat P-value Lower 95%Upper 95%下限%上限% Intercept X Variable 15 RESIDUAL OUTPUT 观测值预测Y残差 1 2 3 4 5 SPSS结果:(1)散点图为: (2)x 与y 之间大致呈线性关系。 (3)设回归方程为01y x ββ∧ ∧ ∧ =+ 1β∧ = 12 2 1 7()n i i i n i i x y n x y x n x -- =- =-=-∑∑ 0120731y x ββ-∧- =-=-?=- 17y x ∧ ∴=-+可得回归方程为 (4)22 n i=1 1()n-2i i y y σ∧∧=-∑ 2 n 01i=1 1(())n-2i y x ββ∧∧=-+∑ =222 22 13???+?+???+?+??? (10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1 169049363 110/3= ++++= 1 330 6.13 σ∧=≈ (5)由于2 11(, )xx N L σββ∧ : t σ ∧ == 服从自由度为n-2的t分布。因而 /2 |(2)1 P t n α α σ ?? ?? <-=- ?? ?? 也即: 1/211/2 (p t t αα βββ ∧∧ ∧∧ -<<+=1α - 可得 1 95% β∧的置信度为的置信区间为(7-2.3537+2.353即为:(,) 2 2 00 1() (,()) xx x N n L ββσ - ∧ + : t ∧∧ == 服从自由度为n-2的t分布。因而 /2 (2)1 P t n α α ∧ ?? ?? ?? <-=- ?? ?? ?? ?? ?? 即 0/200/2 ()1 pβσββσα ∧∧∧∧ -<<+=- 可得 1 95%7.77,5.77 β∧- 的置信度为的置信区间为() (6)x与y的决定系数 2 21 2 1 () 490/6000.817 () n i i n i i y y r y y ∧- = - = - ==≈ - ∑ ∑ (7) 回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验: 第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。 第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量 2.1 一元线性回归模型有哪些基本假定? 答:1. 解释变量 1x , ,2x ,p x 是非随机变量,观测值,1i x ,,2 i x ip x 是常数。 2. 等方差及不相关的假定条件为 ? ? ? ? ? ? ??????≠=====j i n j i j i n i E j i i ,0),,2,1,(,),cov(,,2,1, 0)(2 σεεε 这个条件称为高斯-马尔柯夫(Gauss-Markov)条件,简称G-M 条件。在此条件下,便可以得到关于回归系数的最小二乘估计及误差项方差2σ估计的一些重要性质,如回归系数的最小二乘估计是回归系数的最小方差线性无偏估计等。 3. 正态分布的假定条件为 ???=相互独立 n i n i N εεεσε,,,,,2,1),,0(~212 在此条件下便可得到关于回归系数的最小二乘估计及2σ估计的进一步结果,如它们分别是回归系数的最及2σ的最小方差无偏估计等,并且可以作回归的显著性检验及区间估计。 4. 通常为了便于数学上的处理,还要求,p n >及样本容量的个数要多于解释变量的个数。 在整个回归分析中,线性回归的统计模型最为重要。一方面是因为线性回归的应用最广泛;另一方面是只有在回归模型为线性的假设下,才能的到比较深入和一般的结果;再就是有许多非线性的回归模型可以通过适当的转化变为线性回归问题进行处理。因此,线性回归模型的理论和应用是本书研究的重点。 1. 如何根据样本),,2,1)(;,,,(21n i y x x x i ip i i =求出p ββββ,,,,210 及方差2σ的估计; 2. 对回归方程及回归系数的种种假设进行检验; 3. 如何根据回归方程进行预测和控制,以及如何进行实际问题的结构分析。 2.2 考虑过原点的线性回归模型 n i x y i i i ,,2,1,1 =+=εβ误差n εεε,,,21 仍满足基本假定。求1β的最小二 乘估计。 答:∑∑==-=-=n i n i i i i x y y E y Q 1 1 2112 1)())(()(ββ 实验五:残差分析 【实验目的】 (1)通过残差检验,掌握残差分析的方法 (2)异常值检验 【仪器设备】 计算机、spss软件、何晓群《实用回归分析》表和表的数据 【实验内容、步骤和结果】 对何晓群《实用回归分析》表的数据进行残差分析 原始数据如表1,其中y表示货运总量(亿吨)x1表示工业总产值(亿元)x2表示农业总产值(亿元)x3表示居民非商业支出(亿元) 表1. 对表1数据用spss软件进行分析得以下各表 由上表可知复相关系数R=,决定系数R方=,由决定系数看出回归方程的显著性不高,接下来看方差分析表3 由表3知F值为较小,说明x1、x2、x3整体上对y的影响不太显著。 表4系数 模型非标准化系数标准系数 t Sig. B标准误差试用版 1(常量).096 x1.385.100 x2.535.049 x3.277.284 表4系数 模型 非标准化系数 标准系数 t Sig. B 标准 误差 试用版 1 (常量) .096 x1 .385 .100 x2 .535 .049 x3 .277 .284 回归方程为 123348.280 3.7547.10112.447y x x x =-+++ 图1.学生化残差 差 残差: 对数据用spss进行分析得 表6异常值的诊断分析 数据不存在异常值.绝对值最大的删除学生化残差为SDR=,因而根据学生化删除残差诊断认为第6个数据为异常值.其中中心化杠杆值,cook距离为位于第一大.因此第6个数据为异常值. 对何晓群《实用回归分析》表的数据进行残差分析 原始数据为 : 表个啤酒品牌的广告费用和销售量 1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据: 求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。 α=)。 (5)检验回归方程线性关系的显著性(0.05 (6)如果某地区的人均GDP为5000元,预测其人均消费水平。 (7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 解:(1) 可能存在线性关系。 (2)相关系数: 系数a 模型非标准化系数标准系数 t Sig. 相关性 B标准误差试用版零阶偏部分 1(常量).003 人均GDP.309.008.998.000.998.998.998 a. 因变量: 人均消费水平 有很强的线性关系。 (3)回归方程:734.6930.309 y x =+ 系数a 模型非标准化系数标准系数t Sig.相关性 回归系数的含义:人均GDP没增加1元,人均消费增加元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 系数(a) 模型非标准化系数标准化系数 t显著性B标准误Beta 1(常量) 人均GDP(元) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4) 模型汇总 模型R R 方调整 R 方标准估计的误 差 1.998a.996.996 a. 预测变量: (常量), 人均GDP。 人均GDP对人均消费的影响达到%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 模型摘要 模型R R 方调整的 R 方估计的标准差 第10章 简单线性回归分析 思考与练习参考答案 一、最佳选择题 1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。 A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错 2.如果相关系数r =1,则一定有( C )。 A .总SS =残差SS B .残差SS =回归 SS C .总SS =回归SS D .总SS >回归SS E. 回归MS =残差MS 3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。 A .ρ=0时,r =0 B .|r |>0时,b >0 C .r >0时,b <0 D .r <0时,b <0 E. |r |=1时,b =1 4.如果相关系数r =0,则一定有( D )。 A .简单线性回归的截距等于0 B .简单线性回归的截距等于Y 或X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总 E .简单线性回归的总SS 等于0 5.用最小二乘法确定直线回归方程的含义是( B )。 A .各观测点距直线的纵向距离相等 B .各观测点距直线的纵向距离平方和最小 C .各观测点距直线的垂直距离相等 D .各观测点距直线的垂直距离平方和最小 E .各观测点距直线的纵向距离等于零 二、思考题 1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。 实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日 一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1) 图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏 5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。 多元线性回归模型 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定 系数为,则调整后的多重决定系数为( D ) A. B. C. 下列样本模型中,哪一个模型通常是无效 的(B ) A. i C (消费)=500+i I (收入) B. d i Q (商品需求)=10+i I (收入)+i P (价格) C. s i Q (商品供给)=20+i P (价格) D. i Y (产出量)=0.6i L (劳动)0.4i K (资本) 3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在的显著性水平上对 1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C ) A. )30(05.0t B. )28(025.0t C. )27(025.0t D. )28,1(025.0F 4.模型 t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明 模型中存在( C ) A.异方差性 B.序列相关 C.多重共线性 D.高拟合优度 6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) (n-k+1) (n-k-2) (n-k-1) (n-k+2) 7. 调整的判定系数 与多重判定系数 之间有如下关系( D ) A.2 211n R R n k -=-- B. 22111 n R R n k -=--- C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=---- 8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。 A.只有随机因素 B.只有系统因素 C.既有随机因素,又有系统因素 、B 、C 都不对 9.在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):( C ) A n ≥k+1 B n 第4章违背基本假设的情况 思考与练习参考答案 4.1 试举例说明产生异方差的原因。 答:例4.1:截面资料下研究居民家庭的储蓄行为 Y i=β0+β1X i+εi 其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。 由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以εi的方差呈现单调递增型变化。 例4.2:以某一行业的企业为样本建立企业生产函数模型 Y i=A iβ1K iβ2L iβ3eεi 被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。 4.2 异方差带来的后果有哪些? 答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果: 1、参数估计量非有效 2、变量的显著性检验失去意义 3、回归方程的应用效果极不理想 总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。 4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。 答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差 的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。 加权最小二乘法的方法: 4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。 答:运用加权最小二乘法消除多元线性回归中异方差性的思想与一元线性回归的类似。多元线性回归加权最小二乘法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为: ∑=----=n i ip p i i i p w x x y w Q 1211010)( ),,,(ββββββ (2) 加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差平方和w Q 达极小。所得加权最小二乘经验回归方程记做 22011 1 ???()()N N w i i i i i i i i Q w y y w y x ββ===-=--∑∑22 __ 1 _ 2 _ _ 02 222 ()() ?()?1 11 1 ,i i N w i i i w i w i w w w w w kx i i i i m i i i m i w x x y y x x y x w kx x kx w x σβββσσ==---=-= = ===∑∑1N i =1 1表示=或 1.1回归分析的基本思想及其初步应用 一、选择题 1. 某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为y bx a =+,已知:数据x 的平 均值为2,数据 y 的平均值为3,则 ( ) A .回归直线必过点(2,3) B .回归直线一定不过点(2,3) C .点(2,3)在回归直线上方 D .点(2,3)在回归直线下方 2. 在一次试验中,测得(x,y)的四组值分别是A(1,2),B(2,3),C(3,4),D(4,5),则Y 与X 之间的回归直线方程为( )A . y x 1=+ B . y x 2=+ C . y 2x 1=+ D. y x 1=-3. 在对两个变量x ,y 进行线性回归分析时,有下列步骤: ①对所求出的回归直线方程作出解释; ②收集数据(i x 、i y ) ,1,2i =,…,n ; ③求线性回归方程; ④求未知参数; ⑤根据所搜集的数据绘制散点图 如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( ) A .①②⑤③④ B .③②④⑤① C .②④③①⑤ D .②⑤④③① 4. 下列说法中正确的是( ) A .任何两个变量都具有相关关系 B .人的知识与其年龄具有相关关系 C .散点图中的各点是分散的没有规律 D .根据散点图求得的回归直线方程都是有意义的 5. 给出下列结论: (1)在回归分析中,可用指数系数2 R 的值判断模型的拟合效果,2 R 越大,模型的拟合效果越好; (2)在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好; (3)在回归分析中,可用相关系数r 的值判断模型的拟合效果,r 越小,模型的拟合效果越好; (4)在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明这样的模型比较合适.带状区域的宽度越窄,说明模型的拟合精度越高. 以上结论中,正确的有( )个. A .1 B .2 C .3 D .4 6. 已知直线回归方程为2 1.5y x =-,则变量x 增加一个单位时( ) A.y 平均增加1.5个单位 B.y 平均增加2个单位 C.y 平均减少1.5个单位 D. y 平均减少2个单位 7. 下面的各图中,散点图与相关系数r 不符合的是( ) 第7章岭回归 思考与练习参考答案 7.1 岭回归估计是在什么情况下提出的? 答:当自变量间存在复共线性时,|X’X|≈0,回归系数估计的方差就很大,估计值就很不稳定,为解决多重共线性,并使回归得到合理的结果,70年代提出了岭回归(Ridge Regression,简记为RR)。 7.2岭回归的定义及统计思想是什么? 答:岭回归法就是以引入偏误为代价减小参数估计量的方差的一种回归方法,其统计思想是对于(X’X)-1为奇异时,给X’X加上一个正常数矩阵 D, 那么X’X+D接近奇异的程度就会比X′X接近奇异的程度小得多,从而完成回归。但是这样的回归必定丢失了信息,不满足blue。但这样的代价有时是值得的,因为这样可以获得与专业知识相一致的结果。 7.3 选择岭参数k有哪几种方法? 答:最优 是依赖于未知参数 和 的,几种常见的选择方法是: 岭迹法:选择 的点能使各岭估计基本稳定,岭估计符号合理,回归系数没有不合乎经济意义的绝对值,且残差平方和增大不太多; 方差扩大因子法: ,其对角线元 是岭估计的方差扩大因子。要让 ; 残差平方和:满足 成立的最大的 值。 7.4 用岭回归方法选择自变量应遵循哪些基本原则? 答:岭回归选择变量通常的原则是: 1. 在岭回归的计算中,我们通常假定涉及矩阵已经中心化和标准化了,这样可以直接比较标准化岭回归系数的大小。我们可以剔除掉标准化岭回归系数比较稳定且绝对值很小的自变量; 2. 当k值较小时,标准化岭回归系数的绝对值并不很小,但是不稳定,随着k的增加迅速趋近于零。像这样岭回归系数不稳定、震动趋于零的自变量,我们也可以予以剔除; 3. 去掉标准化岭回归系数很不稳定的自变量。如果有若干个岭回归系数不稳定,究竟去掉几个,去掉那几个,要根据去掉某个变量后重新进行岭回归分析的效果来确定。 第9章 含定性变量的回归模型 思考与练习参考答案 9.1 一个学生使用含有季节定性自变量的回归模型,对春夏秋冬四个季节引入4个0-1型自变量,用SPSS 软件计算的结果中总是自动删除了其中的一个自变量,他为此感到困惑不解。出现这种情况的原因是什么? 答:假如这个含有季节定性自变量的回归模型为: t t t t kt k t t D D D X X Y μαααβββ++++++=332211110 其中含有k 个定量变量,记为x i 。对春夏秋冬四个季节引入4个0-1型自变量,记为D i ,只取了6个观测值,其中春季与夏季取了两次,秋、冬各取到一次观测值,则样本设计矩阵为: ????? ? ?? ?? ? ?=00011001011000101001 0010100011 )(6 165154143 132121 11k k k k k k X X X X X X X X X X X X D X, 显然,(X,D)中的第1列可表示成后4列的线性组合,从而(X,D)不满秩,参数无法唯一求出。这就是所谓的“虚拟变量陷井”,应避免。 当某自变量x j 对其余p-1个自变量的复判定系数2j R 超过一定界限时,SPSS 软件将拒绝这个自变量x j 进入回归模型。称Tol j =1-2 j R 为自变量x j 的容忍度(Tolerance ),SPSS 软件的默认容忍度为0.0001。也就是说,当2j R >0.9999时,自变量x j 将被自动拒绝在回归方程之外,除非我们修改容忍度的默认值。 ??? ??? ? ??=k βββ 10β??? ??? ? ??=4321ααααα 1 下面是7个地区2000年的人均国生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元 北京上海 22460 11226 34547 4851 5444 2662 4549 7326 4490 11546 2396 2208 1608 2035 求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。 (5)检验回归方程线性关系的显著性(0.05 α=)。 (6)如果某地区的人均GDP为5000元,预测其人均消费水平。 (7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 解:(1) 可能存在线性关系。 (2)相关系数: (3)回归方程:734.6930.309 y x =+ 回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规排版。 系数(a) 模型非标准化系数标准化系数 t 显著性B 标准误Beta 1 (常量)734.693 .540 5.265 0.003 人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% (4) 模型汇总 模型R R 方调整 R 方标准估计的误 差 1 .998a.996 .996 247.303 a. 预测变量: (常量), 人均GDP。 人均GDP对人均消费的影响达到99.6%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规排版。 模型摘要 模型R R 方调整的 R 方估计的标准差 1 .998(a) 0.996 0.996 247.303 a. 预测变量:(常量), 人均GDP(元)。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 应用回归分析课后习题 参考答案 Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】 第二章一元线性回归分析 思考与练习参考答案 一元线性回归有哪些基本假定 答:假设1、解释变量X是确定性变量,Y是随机变量; 假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(ε i )=0 i=1,2, …,n Var (ε i )=2i=1,2, …,n Cov(ε i, ε j )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X之间不相关: Cov(X i , ε i )=0 i=1,2, …,n 假设4、ε服从零均值、同方差、零协方差的正态分布 ε i ~N(0, 2) i=1,2, …,n 考虑过原点的线性回归模型 Y i =β 1 X i +ε i i=1,2, …,n 误差εi(i=1,2, …,n)仍满足基本假定。求β1的最小二乘估计解: 得: 证明(式),e i =0 ,e i X i=0 。 证明: ∑ ∑+ - = - = n i i i n i X Y Y Y Q 1 2 1 2 1 )) ? ?( ( )? (β β 其中: 即:e i =0 ,e i X i=0 2 1 1 1 2) ? ( )? ( i n i i n i i i e X Y Y Y Qβ ∑ ∑ = = - = - = ) ? ( 2 ?1 1 1 = - - = ? ?∑ = i i n i i e X X Y Q β β ) ( ) ( ? 1 2 1 1 ∑ ∑ = = = n i i n i i i X Y X β 01 ?? ?? i i i i i Y X e Y Y ββ =+=- 01 00 ?? Q Q ββ ?? == ?? 第二章 一元线性回归分析 思考与练习参考答案 一元线性回归有哪些基本假定? 答: 假设1、解释变量X 是确定性变量,Y 是随机变量; 假设2、随机误差项ε具有零均值、同方差和不序列相关性: E(εi )=0 i=1,2, …,n Var (εi )=?2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X 之间不相关: Cov(X i , εi )=0 i=1,2, …,n 假设4、ε服从零均值、同方差、零协方差的正态分布 εi ~N(0, ?2 ) i=1,2, …,n 考虑过原点的线性回归模型 Y i =β1X i +εi i=1,2, …,n 误差εi (i=1,2, …,n )仍满足基本假定。求 β1的最小二乘估计 解: 得: 证明(式),?e i =0 ,?e i X i =0 。 证明:∑∑+-=-=n i i i n i X Y Y Y Q 1 2102 1 ))??(()?(ββ 其中: 即: ?e i =0 ,?e i X i =0 211 1 2)?()?(i n i i n i i i e X Y Y Y Q β∑∑==-=-=0)?(2?11 1 =--=??∑=i i n i i e X X Y Q ββ) () (?1 2 1 1 ∑∑===n i i n i i i X Y X β01????i i i i i Y X e Y Y ββ=+=-0 1 00??Q Q β β ??==?? 回归方程E (Y )=β0+β1X 的参数β0,β1的最小二乘估计与最大似然估计在什么条件下等价?给出证明。 答:由于εi ~N(0, ?2 ) i=1,2, …,n 所以Y i =β0 + β1X i + εi ~N (β0+β1X i , ?2 ) 最大似然函数: 使得Ln (L )最大的0 ?β,1?β就是β0,β1的最大似然估计值。 同时发现使得Ln (L )最大就是使得下式最小, ∑∑+-=-=n i i i n i X Y Y Y Q 1 21021 ))??(()?(ββ 上式恰好就是最小二乘估计的目标函数相同。值得注意的是:最大似然估计是在εi ~N (0, ?2 )的假设下求得,最小二乘估计则不要求分布假设。 所以在εi ~N(0, ?2 ) 的条件下, 参数β0,β1的最小二乘估计与最大似然估计等价。 证明0 ?β是β0的无偏估计。 证明:)1[)?()?(1 110∑∑==--=-=n i i xx i n i i Y L X X X Y n E X Y E E ββ )] )(1 ([])1([1011i i xx i n i i xx i n i X L X X X n E Y L X X X n E εββ++--=--=∑∑== 1010)()1 (])1([βεβεβ=--+=--+=∑∑==i xx i n i i xx i n i E L X X X n L X X X n E 证明 证明: )] ()1([])1([)?(102110i i xx i n i i xx i n i X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑== () ) 1()1()?(2 2 2 1 2 2 xx n i i L X n X X X n Var +=-+=∑=σσβSPSS实验报告_线性回归_曲线估计
26、回归分析测试题及答案
应用回归分析,第8章课后习题参考答案
应用回归分析课后答案
多元线性回归SPSS实验报告
应用回归分析第2章课后习题参考答案
spss软件分析异常值检验实验报告
回归分析练习试题和参考答案解析
简单线性回归分析思考与练习参考答案
回归分析实验报告
多元线性回归模型习题及答案
应用回归分析,第4章课后习题参考答案
回归分析练习题(有答案)
应用回归分析,第7章课后习题参考答案
应用回归分析-第9章课后习题答案
回归分析练习题及参考答案
应用回归分析课后习题参考答案
应用回归分析 课后习题参考答案
相关文档
- 应用回归分析课后答案
- 应用回归分析_第2章课后习题参考答案
- 回归分析练习题有答案
- 应用回归分析课后答案
- 回归分析练习题与参考答案
- 应用回归分析第章课后习题参考答案Word版
- 应用回归分析_整理课后习题参考答案
- 回归分析练习题及参考答案
- 回归分析课后习题
- 应用回归分析,第4章课后习题参考答案
- 回归分析第一章课后答案
- 回归分析课后习题
- 应用回归分析课后习题参考答案 全部版 何晓群,刘文卿
- 回归分析习题答案
- 应用回归分析-课后习题答案-何晓群
- 应用回归分析课后习题
- 应用回归分析 课后习题参考答案
- 课后习题解答(应用回归分析)
- 回归分析课后习题.doc-实用回归分析
- 应用回归分析整理课后习题参考答案