中文乱码解决方案之过滤器

中文乱码解决方案之过滤器
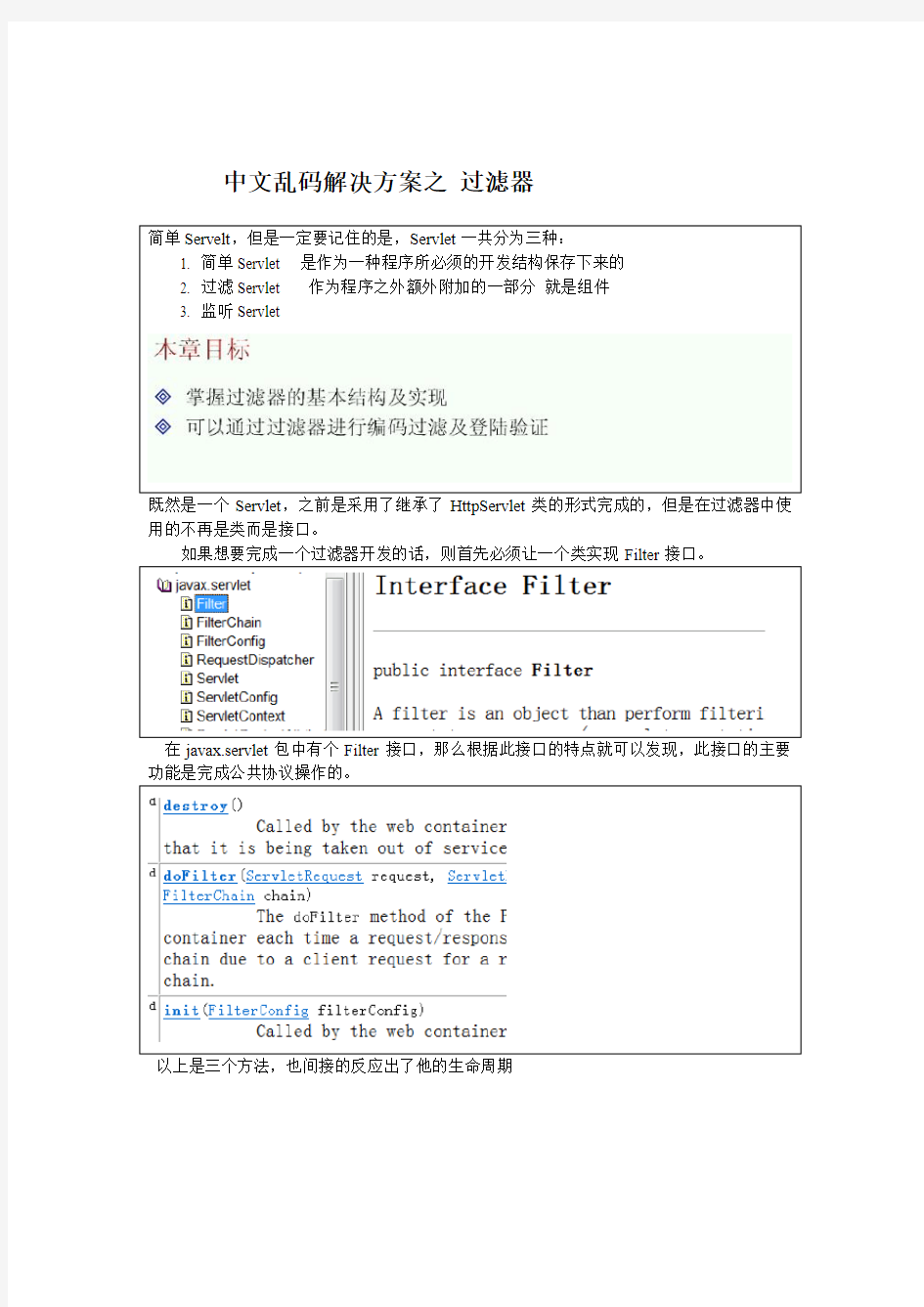
简单Servelt,但是一定要记住的是,Servlet一共分为三种:
1. 简单Servlet 是作为一种程序所必须的开发结构保存下来的
2. 过滤Servlet 作为程序之外额外附加的一部分就是组件
3. 监听Servlet
既然是一个Servlet,之前是采用了继承了HttpServlet类的形式完成的,但是在过滤器中使用的不再是类而是接口。
如果想要完成一个过滤器开发的话,则首先必须让一个类实现Filter接口。
在javax.servlet包中有个Filter接口,那么根据此接口的特点就可以发现,此接口的主要功能是完成公共协议操作的。
以上是三个方法,也间接的反应出了他的生命周期
一个简单的过滤器
package Fileter;
import java.io.*;
import javax.servlet.*;
public class SimpleFilter implements Filter{
public void init(FilterConfig config)throws ServletException{
String initParam=config.getInitParameter("ref");//取得初始化参数
System.out.println("**过滤器初始化,初始化参数="+initParam);
}
public void doFilter(ServletRequest request,ServletResponse response,FilterChain chain) throws IOException,ServletException{//执行过滤
chain.doFilter(request, response);//将请求继续传递
}
public void destroy(){
System.out.println ("**过滤器销毁");
}
}
但是现在需要回顾一下,如果现在是一个普通的Servlet,则在使用的时候必须手工调用,例如在form表单中的action之中编写路径
但是过滤这种操作本身可是属于自动完成。就是说只要定义了这个过滤操作就会进行自动过滤。
过滤器完成之后肯定也要开始进行配置操作,需要注意的是,如果一个web.xml文件中既有普通的配置又有过滤器的配置的话,应该先写过滤器的配置
在此处配置的url-pattern表示的是一个过滤路径,现在既然是“/”则表示的是对一个目录中的全部内容进行过滤。
过滤器不需要任何的配置就可以在服务器启动的时候自动的完成初始化操作。如上图中红色的区域是在服务器启动的时候就执行了。
一个过滤器的基本生命周期与Servlet是非常相似的,但是现在为什么界面上什么都不显示了呢?
FilterChain表示把请求向下传递,如果后面还有过滤器,则继续过滤,如果没有则直接到目的地。
举一个形象的例子:
A和B是两个人,C和D是两个强盗,A到底B需要经过一座山,当A走到山顶的时候,强盗自动出来抢劫A,注意是自动的。这个时候A可能被杀,可能被抢劫后放了A,于是A继续走,如果后面还有强盗D,则A继续被D抢劫了一遍,然后才到达目的地B。
映射到程序中就是,A请求想要到底B请求,需要经过过滤器C和D,在A传递到B 的过程中,过滤器C首先自动出来对A进行过滤操作,FilterChain表示的是把请求向下传递,也就是强盗C抢劫A后将A向下放行,如果后面还有过滤器D,则继续进行过滤。
问题:这个时候大家会不会想,当A到底B后,A不能一直都住在B的家里啊,那么A从B家中返回又会怎么样呢?映射到我们的程序中就是A到B是一个请求的过程,之后B要响应A的请求。
实际上A回去的时候还得被抢劫一次,也就是说,过滤器实际上是执行4次的,来的时候几次,回去的时候也是几次。
与Servlet一样,过滤器本身也可以对多个路径执行过滤,例如;
这个表示对jsp文件夹下的login文件进行过滤,只要符合要求,是可以对任意指定的文件进行过滤的。
实际上过滤器的基本概念比较简单,而且也比较好理解,但是该怎么使用呢?从实际上来讲过滤器在开发中的使用最频繁的两种操作是:编码过滤和登录验证。
对于编码肯定是所有页面都要使用的,而且只要是页面都要写编码:requestSetCharacterEncoding()方法进行编码的设置
package Fileter;
import java.io.*;
import javax.servlet.*;
public class Encoding implements Filter{
private String charSet; //设置字符编码
public void init(FilterConfig config)throws ServletException{
this.charSet=config.getInitParameter("charset");//取得初始化参数
}
public void doFilter(ServletRequest request,ServletResponse response,FilterChain chain) throws IOException,ServletException{//执行过滤
request.setCharacterEncoding(this.charSet);//设置统一编码
}
public void destroy(){
}
}
在本程序中,在初始化操作时候,通过FilterConfig中的getInitParameter()取得了一个配置得的初始化参数,此参数的内容是一个指定的过滤编码,然后在doFilter()方法中执行request.setCharacterEncoding()操作
之后,只要是页面的提交,就会经过这个过滤器,而这个过滤器的功能就是统一字符编码。这样就避免了在每个页面中都写requestSetCharacterEncoding()这个方法了。
登录验证也是一个很重要的内容,因为在很多情况下都需要通过session完成登录验证的操作,但是如果每个页面都编写重复的session属性的判断,那么就变得相当的复杂,而且维护也不方便,所以可以对一些需要限制的地方采用登录的验证操作。
登录验证是所有web开发中不可缺少的部分,最早的做法是通过验证session的方式完成的,但是如果每个页面都这样做的话,则肯定会造成大量的代码重复,而通过过滤器的方式即可避免这种重复的操作。
这里需要主要的是,session本身是属于HTTP协议的范畴,但是doFilter()方法中定义的是ServletRequest类型的对象,那么要想取得session,则必须进行向下转型,将ServletRequest 变为HttpServletRequest接口对象,才能通过getSession()方法取得session 对象。
package Fileter;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
public class SimpleFilter implements Filter{
public void init(FilterConfig config)throws ServletException{
}
public void doFilter(ServletRequest request,ServletResponse response,FilterChain chain)
throws IOException,ServletException{//执行过滤
HttpServletRequest req=(HttpServletRequest)request;
HttpSession ses=req.getSession();
if(ses.getAttribute("userid")!=null){
chain.doFilter(request, response);
}else{
request.getRequestDispatcher("login.jsp").forward(request, response);
}
}
public void destroy(){
}
}
cmd窗口显示中文乱码及无法输入中文解决方法
cmd窗口显示中文乱码及无法输入中文解决方法 (2009-05-09 19:13:12) 分类:软件应用 标签: it 中文显示为乱码 临时解决方案: 在 CMD 中运行 chcp 936。 永久解决方案: 打开不正常的 CMD 或命令提示符窗口后,单击窗口左上角的图标,选择弹出的菜单中的“默认值”,打开如下图的对话框。单击第一个“选项”选项卡,将默认的代码页改为 936 后重启 CMD。 附:
如果改了以后无法生效,窗口的“默认值”和“属性”没变,进入注册表,在 HKEY_CURRENT_USER 下找到 console 项下的 Console 以及其下可能有 的 %SystemRoot%_system32_cmd.exe(这个 %SystemRoot%_system32_cmd.exe 下有的 codepage 话就改,如果没有就不管它),codepage值改为 936(十进制)或 3a8(十六进制)。 936(十进制)/3a8(十六进制) 是简体中文的,如是其它语言,要改为对应的代码。然后再执行第二段中所述的操作。 还可能和 CMD 的默认值的“字体”设置有关。 在 CMD 的“默认值”和“属性”的“字体”选项卡中中确认设定的字体是可以显示中文字符的字体,并且确定字体文件没有被破坏。字体最好设置为默认的点阵字体。 还是不行,干脆把%SystemRoot%_system32_cmd.exe内容备份下,然后清空它。或是把以下内容保存为REG文件导入试试。 Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] "QuickEdit"=dword:00000800 "CodePage"=dword:000003a8 "WindowSize"=dword:001e005a "FontSize"=dword:000c0008 "FontFamily"=dword:00000030 "FontWeight"=dword:00000190 "FaceName"="Terminal" ============================================================= 无法输入中文 确认以下事项: 1.CMD 里中文字符可以正常显示(上文). 2.注册表中 HKEY_CURRENT_USER\Console 及 HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] 下LoadConIme 的值为 1. 3.conime.exe 这个文件存在,没有受到破坏,并且正常运行.
中文乱码解决大全
SSH开发过程中的中文问题汇总 作者:Rainisic来源:博客园发布时间:2012-01-11 14:26 阅读:50 次原文链接[收藏] 在使用SSH开发的过程中,我们经常会因为各种各样的中文乱码问题而苦恼。之前开发的过程中遇到过一些,但是都没有记录下来,这次,我就遇到的中文问题进行一个汇总,希望能够对大家有所帮助。 1. 平台环境参数 操作系统:Windows 7 旗舰版64位 JDK版本:JDK 1.6 / JDK 1.7 (此处由于JDK 7 发布不久,所以对两个版本进行测试) 开发环境:Eclipse Java EE Indigo 网站容器:Tomcat 7.0 开发框架: Struts 2.3.1.1-GA Spring 3.1.0-release Hibernate 4.0.0-Final / Hibernate 3.6.9-Final (此处由于Hibernate 4 final 刚刚发布不久,所以对两个版本进行测试) 2. 中文问题汇总 (1)HTML中未指定文件编码 问题描述:在HTML中未指定文件编码,在部分浏览器中将会出现中文乱码。 解决方案:在HTML的head标签中指定文档编码,代码如下(请根据DOCTYPE选择): // HTML 4.01 Transitional
// HTML 5 (2)表单提交使用GET方法 问题描述:在HTML form 中提交表单的时候使用method="get"导致中文乱码。 解决方案:form表单的method设置为post,代码如下:
(3)JSP文件中未指定文档编码类型 问题描述:在JSP文件中未指定JSP文档编码,在浏览器中会出现中文乱码。 解决方案:在JSP文件首部增加指定文档编码的代码,代码如下: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> (4)文件编码不正确 问题描述:由于Java文件、JSP文件等文件编码不正确,导致中文乱码。 解决方案:设置文件的默认编码为UTF-8(如果需要使用其他编码,请确保上述两个编码格式与文件编码相同) 设置方法: 当前文件编码修改:该文件右键→Properties→Resource,右侧Text file encoding→Other →UTF-8 默认文件编码修改: 0. Windows→Preferences 打开Eclipse配置选项窗口。 1. General→Content Type,右侧Text 下面所需要的文件类型Default encoding设置为UTF-8中文Y型过滤器说明书
Y型过滤器 使用说明书 中国·乐山市热工仪表有限公司
一、用途及特点 Y型过滤器是输送介质的管道系统不可缺少的一种过滤装置,Y型过滤器通常安装在减压阀、泄压阀、定水位阀或其它设备的进口端,用来清除介质中的杂质,以保护阀门及设备的正常使用。Y型过滤器具有结构先进,阻力小,排污方便等特点。 二、主要技术参数 公称压力:PN1.6MPa~4.0Mpa 公称通径:DN15~200㎜适用介质:水、油、气体等 过滤精度:通水网为18~30目,通气网为40~100目,通油网为100~480目。 工作温度:≤200℃ 法兰标准:JB、GB、HG 壳体材质:WCB 滤筐、滤网材质:304 密封材质:耐油石棉橡胶、聚四氟乙烯、丁腈橡胶等 执行标准:Q/20696377-7.4-2011 三、安装与维护 1、根据过滤器的使用范围合理地使用。 2、安装前应将管道内的焊渣、杂物清除干净,以免损坏过滤器。 3、安装时应按过滤器的箭头方向进行。 4、过滤器的运行及维护系统最初工作一段时间后(一般不超过一周),应进行清洗, 以清除系统初始运行时积聚在滤网上的杂质污物。在此后,须定期清洗。清洗次数依据工况条件而定。若过滤器不带排污丝堵,则清洗过滤器时要将滤网限位器以及滤网拆下。 警告:每次维护、清洗前,应将过滤器与带压系统隔离。清洗后,重新安装时要使用新的密封垫。 5、过滤器使用中,应定期检查是否工作正常,发现异常情况,应立即消除,以免 造成事故。 6、长期存放时,应置于通风干燥处,并定期检查和保养。 四、定货须知 为了保证提供的产品能满足贵公司(厂)的使用要求,请按以下要求提供必要的参数: 1、产品型号 2、公称压力 3、公称通径 4、工作介质 5、工作温度 6、法兰标准 7、结构长度(有要求时)
JSP中文乱码的产生原因及解决方案
JSP中文乱码的产生原因及解决方案 在JSP的开发过程中,经常出现中文乱码的问题,可能一直困扰着大家,现在把JSP 开发中遇到的中文乱码的问题及解决办法写出来供大家参考。首先需要了解一下Java中文问题的由来: Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,Java和JSP文件本身编译时产生的乱码问题和Java程序于其他媒介交互产生的乱码问题。首先Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件的保存方式是基于字节流的,如果Java和JSP编译成class文件过程中,使用的编码方式与源文件的编码不一致,就会出现乱码。基于这种乱码,建议在Java文件中尽量不要写中文(注释部分不参与编译,写中文没关系),如果必须写的话,尽量手动带参数-ecoding GBK或-ecoding gb2312或-ecoding UTF-8编译;对于JSP,在文件头加上<%@ page contentType="text/html;charset=GBK"%>或 <%@ page contentType="text/html;charset=gb2312"%>基本上就能解决这类乱码问题。 下面是一些常见中文乱码问题的解决方法(下面例子中ecoding采用的是gb2312,也可设为ecoding GBK或ecoding UTF-8): 一、 JSP页面乱码 这种乱码问题比较简单,一般是页面编码不一致导致的乱码,一般新手容易出现这样的问题,具体分以下两种情况: 未指定使用字符集编码 下面的显示页面(display.jsp)就出现乱码:
高效过滤器操作使用维护说明书
高效过滤器操作使用维护说明书 1. 基本参数 1.1 运行滤速:8m/h 1.2 进水浊度: <5mg/L 1.3 出水浊度: <1mg/L 1.4 反洗强度:8L/㎡·S 1.5 气洗强度:12L/㎡·S 1.6 反洗时间:4-6min 1.7 工作温度:5-40℃ 1.8 工作压力:≤0.6MPa 1.9 滤料高度:1200mm 1.10 填料成分:石英砂、无烟煤、鹅卵石 2. 结构及工作原理 原水在管道内加入絮凝剂,絮凝剂在水中发生离子水解和聚合过程,水中胶体粒子对水解及聚集的各种产物进行强烈的吸附,使粒子表面电荷和扩散厚度同时降低,因而粒子间相互排斥能降低,相互接近而凝聚,水解产生的聚合物被两个以上的胶体吸附后,在粒子间产生架桥联接,逐步形成较大的絮凝体,经过高效过滤器时,为滤料载留。 高效过滤器是以成层状的石英砂、无烟煤作为床层.床的顶层由最轻和最粗品级的材料组成,而最重和最细品级的材料放在床的低部。其原理为
按深度过滤--水中较大的颗粒在顶层被去除,较小的颗粒在过滤器介质的较深处被去除。从而使水质达到粗过滤后的标准。多介质过滤器可去除水中水中的悬浮物、有机物、胶质颗粒、微生物、氯、嗅味及部分重金属离子等,并降低水的SDI值,满足深层净化的水质要求。该设备具有造价低廉,运行费用低,操作简单;滤料有石英砂、无烟煤、鹅卵石,经过反洗,可多次使用,滤料使用寿命长等特点。 高效过滤器的吸附是一种物理吸附,按滤料的填装方式大体可分为松散区(粗砂)、紧密区(细砂),悬浮物质在松散区主工通过流动接触产生接触凝聚作用,所以该区域截留较大颗粒的悬浮物质,在紧密区主要是惯性碰撞及悬浮颗粒间的吸附作用,所以该区域是截留较小颗粒的悬浮物质。 当高效过滤器因截留过量的机械杂质而影响其正常工作,则可用反冲洗的方法来进行清洗。利用逆向进水,同时通入压缩空气,进行气水混合擦洗,使过高效过滤器内滤层松动,可使粘附于石英砂表面的截留物剥离并被反冲水流带走,有利于排除滤层中的沉渣、悬浮物等,并防止滤料板结,使其充分恢复截污能力,从而达到清洗的目的。反洗以进出口压差参数设置来控制反冲洗周期,经验得知一般为一天,具体须视原水浊度而定。 高效过滤器采用蝶阀操作阀组,高效过滤器的启运、正洗、反洗、停机等工序均是自动控制进行操作。 当高效过滤器运行至进出口压差为0.07MPa时,必须进行反洗。 3.反洗的必要性 高效过滤器在过滤过程中,原水中的悬浮物等被滤料层截留吸附并不断地在滤料层中积累,于是滤层孔隙逐渐被污物堵塞,在滤层表面形成滤
乱码形成原因及消除方法大全 八
乱码形成原因及消除方法大全八 乱码形成原因及消除方法大全.txt生活,是用来经营的,而不是用来计较的。感情,是用来维系的,而不是用来考验的。爱人,是用来疼爱的,而不是用来伤害的。金钱,是用来享受的,而不是用来衡量的。谎言,是用来击破的,而不是用来装饰的。信任,是用来沉淀的,而不是用来挑战的。乱码形成原因及消除方法大全 2008-01-18 14:08乱码形成原因及消除方法大全当我们浏览网页、打开文档或邮件,运行软件时,经常会看到乱码,通常是由于源文件编码,Windows 不 能正确识别造成的的,也可能是其他原因。乱码给我们带来了太多的烦恼,为了帮助大家彻底摆脱乱码 ,下面我们就来探讨一下乱码的形成原因及其消除方法。 一、乱码有五种类型 常见的乱码,一般可以分成五种类型:第一类是文本/文档文件乱码,这一般是由于源文件编码,与
Windows使用的编码不通用造成的;第二类是网页乱码,形成原因与第一类乱码类似;第三类是Windows 系统界面乱码,即中文Windows的菜单、桌面、提示框等显示乱码,主要是Windows注册表中有关字体的 部分设置不当引起的;第四类是应用程序的界面乱码,即各种应用程序(包括游戏)本来显示中文的地 方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文链接库,被英文链接 库覆盖造成的;第五类是邮件乱码,形成原因也极其复杂。 二、如何消除应用程序的界面乱码? 目前有些软件发行了Unicode版本,这是一种通用的字符编码标准,涵盖了全球多种语言及古文和专 业符号,这种版本的软件运行在任何系统和语言上都不会乱码,如果是非Unicode编码的程序,就会有乱
Python2.x 中文乱码问题解决方法
Python2.x中文乱码问题解决方法 Python中乱码问题是一个很头痛的问题。 在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文。否则会出现乱码 【问题原因】 在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码。Python默认采取的ASCII编码,字母、标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求。 代码如下: >>> import sys >>> sys.getdefaultencoding() 'ascii' 为了能在计算机中表示所有的中文字符,中文编码采用两个字节表示。如果中文编码和ASCII混合使用的话,就会导致解码错误,从而才生乱码。而CMD下默认的编码方式为:GBK,所以就造成了上面的乱码!
采用两个字节的中文编码标准有:GB2312、GBK、BIG5等。 【处理办法】 为了将各种不同的语言包含在统一的字符集中,满足国际间的信息交流,国际上制订了UNICODE字符集,包含了世界上所有语言字符,这些字符具有唯一的编码,通过使用UNICODE字符集可以满足跨语言的文字处理,避免乱码的产生。 i) 交互式命令中:一般不会出现乱码,无需做处理 ii) py脚本文件中:跨字符集必须做设置,否则乱码。 首先在开头一句添加:
代码如下: # coding = utf-8 # 或 # coding = UTF-8 # 或 # -*- coding: utf-8 -*- 其次需将文件保存为UTF-8的格式! 上面那一句仅仅是告诉Python编译器:脚本中包含了非ASCII字符,并未进行转换。 如果要将字符编码从默认的ASCII改为UTF-8,需要在保存的时候选择保存为UTF-8格式。 如果是用NODEPAD打开,【另存为】-->UTF-8即可 如果是用IDLE打开,【Options】-> 【Configure IDLE】->【General】
高速过滤器操作说明书剖析
攀钢动力厂四水站净环水系统改造工程 TGSL-3高速过滤器 操 作 维 护 书 宜兴市华通环保设备有限公司
目录 1、设备概述 (2) 2、技术性能 (2) 3、工艺设计说明 (3) 4、单项设备参数 (4) 5、操作要求 (6) 6、示意图 (7) -1-
TGSL-3高速过滤器操作说明书 一、设备概述 GSL型快速过滤器在原水悬浮物较多的情况下能确保出水水质的高质量,具有过滤速度高、处理水量大、占地面积小等优点。其操作分为人工操作和单台(或多台)程序控制自动操作两种。GSL型快速过滤器不仅适用于过滤悬浮物较多的原水,而且在循环供水系统中使用可改善水质,提高水的循环利用率,节约用水,是当前工业水处理设施中必备的设备。 我公司生产的GSL型快速过滤器由冶金部北京钢铁研究总院设计,经我公司多年的制作经验及不断吸取用户的反馈意见,产品性能得到大大的改进。本产品广泛用于钢铁行业中的净化处理轧钢、连铸的浊水(含有氧化铁皮及油质),以及循环水系统中旁滤处理,取得了十分满意的效果。 二、TGSL-3高速过滤器技术性能 1、设备筒体最大直径:Φ3020 2、底座最大直径:Φ3280 3、设备高度:H7100㎜ 4、滤水面积:7.07㎡ 5、最高滤速:V40m/h -2-
6、最大滤水量:270m3/h 7、最大进水压力:≯3kgf/cm2 8、进水悬浮物含量:≤40mg/l 9、出水悬浮物含量:≤10mg/l 10、过滤器内平均压力损失:~0.5kgf/cm2 11、反洗水强度:40m3/㎡h 12、反洗水压力: 1.5kgf/cm2 13、反洗空气强度:15m3/㎡h 14、反洗空气压力:0.7kgf/cm2 15、设备运行重量:61.8吨 三、工艺设计说明 设备本体材质Q235A,内部用醇酸材料防腐,以卵石为承托,用无烟煤、石英砂作滤层。设备成型体为圆柱体,上部和中间用旋压式封头作耐压体,底部以平面方式和基础接 3.1、进水系统 由于高速过滤器滤速40m/h,如果高流速进水由上而下运行,将导致不能形成滤膜因而影响出水水质,目前高速过滤器设计的进水系统由缓冲带、中央进水管组成,进水方式为逆流进水,滤膜受冲击问题迎刃而解。 -3-
win7系统常见的乱码问题解决方法
win7系统常见的乱码问题解决方法 win7系统乱码的问题,经常会碰到一些软件是简体中文的,可是在win7系统中却出来乱码的问题?400pc小编教你破解是哪些原因造成win7系统乱码。 近期,居住香港的姐姐也安装了Windows 7,不过,令她烦恼的是使用一些简体中文的软件出现了乱码。而这些软件都无法找到繁体版本,比如:迅雷,即使勉强安装好也无法轻松使用。难道香港用户就无法使用这些简体软件了吗?其实,Windows 7自身已经提供了完善的解决方案了。 一、Windows 7乱码问题来龙去脉 旅居香港的姐姐安装的是我提供的简体中文版本的Windows 7旗舰版,按理是可以顺利兼容简体软件的,然而问题就出在姐姐对默认的安装设置进行了修改。因为姐姐经常使用繁体软件,她将系统的“区域和语言”的“格式”、“位置”、“默认输入语言”、“非Unicode程序的语言”都设置成了更加顺手的香港繁体。 我们知道Unicode也可称为统一码,为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换处理的要求,然而,还是有不少程序并不支持该编码,这时就有必要设置非Unicode程序使用的语言编码了。像迅雷这样的软件就支持简体中文编码,而不支持Unicode,当设置了香港繁体的非Unicode 就会出现乱码,同理,将非Unicode设置为简体后,很多不支持Unicode的繁体软件也会出现乱码。这个乱码问题难道是两难的吗?其实,我们使用Windows 7的语言包补丁安装功能就可以顺利解决。 二、巧妙解决Windows 7乱码 1.安装合适的语言包 首先,要能安装多种语言包的Windows 7只能是旗舰版或者企业版,接着我们就来解决这个问题吧。我们点击“开始-Windows Update”打开自动更新窗口。 在窗口中点击“34个可选更新”链接,在可以下载安装的语言包列表中选择“繁体中文语言包”,确定即可。 回到刚才的窗口点击“安装更新”按钮开始下载安装。 安装完语言包补丁需要重启。重启的过程需要配置补丁。
XPE终端常见问题及解决办法V10
产品型号:XPE终端 现象描述:开机普通用户自动登录,如何进管理员或者其它用户? 故障分析: 解决办法:点击“注销”后,按住Shift键一直不放,可看到用户登录界面。 (二) 产品型号:XPE终端 现象描述:忘记管理员密码,如何以管理员身份登录系统? 故障分析: 解决办法:在用户登录界面,连续两下快按Shift+Ctrl+Delete键,会出现另一种用户登录界面,用户名输入:administrator 密码输入:gwixpe登入超级管理员。然后通过本地监控程序(本地管理软件)修改用户名密码。 (三) 产品型号:XPE终端 现象描述:忘记本地监控程序登录密码 故障分析: 解决办法:本地监控程序忘记密码后,只能在注册表查看登录密码。在注册表HKEY_LOCAL_MA CHINE\SYSTEM\GWI下ChangePassword的值就是密码。 (四) 产品型号:XPE终端 现象描述:运行U盘或者D盘中.exe文件报错 故障分析:报错是因为在组策略中设置了软件限制策略。 解决办法:在“运行”输入gpedit.msc回车打开策略管理器中,计算机配置---windows设置---软件限制策略中可以看到相关设置(详细设置在可以在网上搜索得到)。 (五) 产品型号:XPE终端 现象描述:管理员用户下能运行的软件却在普通用户下不能运行 故障分析: 解决办法:在管理员下,把安装后的软件目录的USERS权限提升为完全控制。如不行把软件发回技术中心。设置方法,目录文件右键属性,安全标签,选择Users,把下面的“完全控制”的勾勾上。 (六) 产品型号:XPE终端 现象描述:系统登录界面,密码输入框没有光标不能输入登录密码 故障分析: 解决办法:连续两下快按Shift+Ctrl+Delete键,在另一种用户登录界面中输入用户名和密码。
Android读取中文文件乱码解决方法
最近在做个MP3播放器,出现中文乱码问题,在网上找了很多解决办法,我整理了出现乱码的点和解决方案,拿出来和大家共享一下 1.读取中文文件乱码解决方法 package com.apj.conv; import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import android.app.Activity; import android.os.Bundle; import android.os.Environment; import android.widget.TextView; public class ConverActivity extends Activity { private TextV iew textview ; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(https://www.sodocs.net/doc/8211569557.html,yout.main); textview = (TextView) findView ById(R.id.lrctext); System.out.println("==============convertCodeAndGetText begin============== ") ; ///获得SDCard中文件的路径 String path = Environment.getExternalStorageDirectory().getAbsolutePath()+ File.separator ; String tochinese = convertCodeAndGetText(path+"a.txt"); System.out.println(tochinese); System.out.println("==============cconvertCodeAndGetText end=============="); textview.setText(tochinese); }
过滤器说明书-英文
SLAF Series Compressed-air Secondary Filter Operation Manual HANGZHOU SHANLI PURIFY EQUIPMENT CORPORATION
Contents I. Product Profile ...................................................................................................................... 错误!未定义书签。 1. Product Overview ........................................................................................................... 错误!未定义书签。 2. Structure and Working Principle..................................................................................... 错误!未定义书签。II. Configuration and Installation ........................................................................................... 错误!未定义书签。 1. Standard Pipeline for the Filters ..................................................................................... 错误!未定义书签。 2. Basic Configuration/Installation Pattern of the Filter..................................................... 错误!未定义书签。 3. Other Configuration/Installation Patterns of the Filters.................................................. 错误!未定义书签。III. Selection and Maintenance Requirements....................................................................... 错误!未定义书签。IV. Troubleshooting................................................................................................................... 错误!未定义书签。Appendix: Chemical Corrosion Resistance Performance of the Filter Series..................... 错误!未定义书签。 Prior to startup, please read this manual carefully
U盘乱码修复
U盘文件夹名称变为类似如下情形:佞愳亠?仠或者@?等等不一,还不能删除,删除时提示:无法删除文件,无法读源文件或磁盘。注意看乱码文件大都特别大,甚至几十G都有。 出现这种问题的原因通常是因为不正常的插拔等情况造成的,导致U盘的文件分配表错乱了 建议:此时运行chkdsk 盘符: /f 可以检查出一些错误。当有提示修改文件夹为文件名时,输入Y选择是。此时一般问题就会解决了。 如果还有问题,将一些重要的文件能保存下来就尽量保存下来,然后对U 盘进行格式化,或者进行低级格式化,再把重要文件COPY回去~ 其他解决方案: 1.在问题U盘图标上点右键选择"属性"——"工具"——点“差错"下的"开始检查"结束后问题即解决.如果不行,请继续往下尝试。 2. 尝试为文件重命名,如果可以重命名的话。运行cmd 打开任务管理器,结束explorer进程,切换到cmd命令提示符状态下输入“Del 文件名”后就可以删除文件了,这种方法只适用于可以重命名的文件。在进行操作时先关闭其他一切不相关的程序。 3. 如果重命名文件时系统提示“拒绝访问”,那么在cmd运行模式下运行“chkdsk 盘符: /f”命令检查磁盘错误并修复。 如果出现找到磁盘错误,一般的错误都是可以修复的,在修复完成后就可以删除乱码文件了。 注意:有时,由于乱码文件所在分区为系统区,系统会提示“另一个进程正在调用该卷,是否希望下次开机时检查该卷?”我建议用这样的方法运行chkdsk 命令,使用Windows安装盘引导系统,在选择新安装windows界面时,按“R”修复已有系统,进入命令提示符状态,在这里运行“chkdsk /f”命令。我测试过,这样运行的效果要比在Windows下的cmd模式中好很多。再运行“fixmbr”命令修复分区表。也可以修复系统其他的问题。 4.如果进行完上一步仍然无法删除乱码文件,可以使用我们最常用的WinRAR压缩工具来删除,具体的方法是压缩乱码文件并选中“压缩后删除源文件”选项。这样,一般的乱码文件就可以删除了。
关于Linux下中文乱码的完整解决方案
关于Linux下中文显示为乱码的完整解决方案Linux,作为一款免费的操作系统,相对于高额费用的Windows系列操作系统,有着更强的优势,所以,许多人也都开始学习Linux操作系统的知识。但是,由于Windows 系列操作系统还是当今社会的主流,所以,人们少不了在Windows和Linux系统之间进行文件的传输。 但是一个新问题出现了,那就是中文乱码问题,这个问题困扰着无数的Linux用户,尤其是Linux的初学者,对于这个问题相当的头疼。 主要问题如下: 1、ssh中,中文显示为乱码:在Wind ows 系统下,用ssh远程连接Linux系统,对于在Linux下显示正常的中文,在ssh中却显示为完全无法识别的乱码字符。 2、中文传输乱码:把Wind ows中的中文文件传输到Linux操作系统中,原本在Wind ows下显示正常的文件,到了Linux系统下,成了无法识别的乱码。 分析其原因,是因为Linux和Wind ows系统下,所用户的字符集不同,Linux系统使用的是Unicod e字符集,而Wind ows使用的是GB字符集。所以,在网上出现了两种解决方案: 方法一:使用Putty代替secure shell client(ssh):在Putty终端设置中,修改wind ow-〉Translation中的Received data assumed to be in which character set值为Linux 中的字符集UTF-8,再连接Linux,
发现这时,Linux中的中文可以正常显示了。 但是一个新问题出现了,把Wind ows中的文件上传了Linux 中,原本在Wind ows下显示正常的中文文件,现在却成了乱码。 所以,这个方法无法彻底解决乱码问题。 方法二:修改Linux默认字符集,把Linux的默认字符集修改为和Wind ows中的字符集一致的GB18030或GB2312,重启Linux系统后,再用ssh终端连接,这时,修改字符集后的中文文件都已经能正常显示,而且,从Wind ows中新上传的中文文件也能正常显示了。这个方法不错。 但是,Linux系统在安装时,产生的中文字符(中文文件夹名、中文文件名、中文文件)在新的字符集下,却又全都显示成了乱码。 有什么方法可以彻底解决乱码问题,使在Linux系统下,所有的中文字符都可以正常显示呢? 本人综合了网上的各种解决方案,经过多次实验,终于找到了一个比较完整的解决方案,步骤如下: 第一步:用英文安装Linux系统:在安装Linux系统时,采用默认的英文安装,而不要使用中文。 第二步:修改字符集:在Linux系统安装成功以后,修改系统的默认字符集,操作如下: 在Fedora Linux系统中,编辑/etc/sysconfig/i18n文件,修改LANG 值为zh_CN.GB2312或zh_CN.GB18030,保存退出。 在OpenSuSE Linux系统中,编辑/etc/sysconfig/language文件,
MYSQL数据中文的乱码问题
最近一台服务器环境升级,mysql从4.0升级到了5.0,乱码问题让人崩溃了…… 下面搜集了一堆方法,其实最简单的还是推荐使用帝国备份王,很好,很强大! 第一种方法,很精辟的总结: 经常更换虚拟主机,而各个服务商的MYSQL版本不同,当导入数据后,总会出现乱码等无法正常显示的问题,查了好多资料,总结出自己的一点技巧: WINDOWS 下导入应该这样 使用MYSQL的命令 在DOS命令下进入mysql的bin目录下,输入mysql -uroot -p密码数据库名称<要恢复的数据库, 例如我们要把D盘的一个名称为test.sql的数据库恢复到本地的test2这个数据库,那么就这样: mysql -uroot -p密码test2以前的国外主机用的Mysql是4.x系列的,感觉还比较好,都无论GBK和UTF-8都没有乱码,没想到新的主机的Mysql是5.0版本的,导入数据后,用Php 读出来全是问号,乱码一片,记得我以前也曾经有过一次切换出现乱码的经验,原因肯定是Mysql版本之间的差异问题。 只好查资料,发现了一个解决方法,就是在mysql_connect后面加一句SET NAMES UTF8,即可使得UTF8的数据库消除乱码,对于GBK的数据库则使用SET NAMES GBK,代码如下:
$mysql_mylink = mysql_connect($mysql_host, $mysql_user, $mysql_pass); mysql_query("SET NAMES 'GBK'"); 数据库字符集为utf-8 连接语句用这个 mysql_query("SET NAMES 'UTF8'"); mysql_query("SET CHARACTER SET UTF8"); mysql_query("SET CHARACTER_SET_RESULTS=UTF8'"); 还有个方法就是,如果你自己的机器的话,可以更改MYSQL字符集,一般在MYSQ4和MYSQL5这两个版本中有效 第二个方法:很不错的解说,可以试一下 mysql乱码处理总结: (1)java中处理中文字符正常,在cmd client中显示乱码是字符集的问题. (2)字段长度设置够长,但插入中文字符时提示 com.mysql.jdbc.MysqlDataTruncation: Data truncation: Data too long for column错误是字符集的问题. (3)乱码问题归根到底是字符集的问题,那就从字符集设置方面考虑,不外乎下面几个方面:server,client,database,connection,results.
过滤器使用说明
自力式调压阀组(蒸汽减压阀组) 产品介绍: 自力式调压阀(蒸汽减压阀)不是孤零零安装在管道上,而是配合其他阀门或管道联合安装在系统中,通常有单路自力式调压阀组(蒸汽减压阀组)和双路自力式调压阀组(蒸汽减压阀组)两种,用户可以根据需要订购 自力式调压阀组(蒸汽减压阀组): 一、用于各种气体及低粘度液体的减压 1、阀前手动球阀 2、阀前压力表 3、过滤器(介质确认无颗粒可省略) 4、自力式减压阀 5、阀后压力表 6、阀后手动球阀 7、旁通球阀 备注:1、根据需要,阀组后还可安装止回阀、安全阀(是否允许而定) 2、旁通管可根据现场空间布置在与自力式阀同一水平面上或同一垂直面上 二、用于各种高粘度液体的介质减压
相对于气体减压而言,只是自力式倒装而已 用于蒸汽减压的自力式减压稳压阀组 冷凝器使用前请灌满冷水 □双路自力式调压阀组(蒸汽减压阀组) 自力式调压阀组(蒸汽减压阀组)装置中双路减压只用在工况特别重要,系统不允许出故障的系统中,平常一路工作,一路关闭备用,只要流量足够,不需要同时开启两路减压,以免出现阀开度过小产生震荡和噪声,影响阀使用寿命。 一、用于各种气体及低粘度液体的减压
1、过滤器 2、手动球阀 3、压力表 4、自力式压力调节阀 5、压力表 6、手动球阀(安装时件1前用户自配手动球阀) 二、用于各种高粘度液体介质的减压 同气体减压,只是自力式阀门倒装便可 三、用于自力式调压阀组(蒸汽减压阀组) 安装时件1前用户自配手动截止阀 □设计、安装减压阀组注意事项 安装时,应注意以下几点:
(1)阀在气体或低粘度液体介质中使用时,通常ZZY型自力式压力调节阀为直立安装在水平管上,当位置空间不允许时才倒装或斜装。 (2)阀在蒸汽或高粘度液体介质中使用时,通常ZZY型自力式压力调节阀为倒立安装在水平管上,冷凝器(蒸汽用自力式)应高于调压阀的执行机构而低于阀前后接管。使用前冷凝器应灌满冷水,以后约3个月灌水一次。 (3)自力式调压阀(蒸汽减压阀)在取压点应取在调压阀适当位置,阀前调压应大于2倍管道直径,阀后调压应大于6倍管道直径。 (4)为便于现场维修及操作,调压阀四周应留有适当空间。 (5)当介质为洁净气体或液体时,阀前过滤器可不安装。 (6)调压阀通径过大(DN≥100时),应有固定支架。 (7)当确认介质很洁净时,件3可不安装。 (8)位置实在不允许时,傍通阀(手动)可以省略(我们不推荐). (9)阀组后根据需要用户可选配止回阀、安全阀等 (10)蒸汽自力式减压稳压阀门根据计算通径可以小于管道直径,而截止阀、切断球阀、傍通阀、过滤器则不能小于管道直径。 □外形尺寸 自力式调压阀组(蒸汽减压阀组)关键是总长L的确定,至于自力式阀门的尺寸见ZZYP(M、N)篇 以控制蒸汽为例,控制其它介质总长类同,当然,尺寸L用户也可根据需要定 采用自力式蒸汽减压阀,因简单方便,维护量小,特别是能适用在无电无气及防爆的场合,因此在蒸汽减压稳压的系统中得到了广泛的应用,见以下特点: 1、蒸汽减压阀压力设定点可在压力调节范围内现场调节; 2、蒸汽减压阀阀体部分与执行机构采用模块化设计,可根据现场要求变化更改执行机构或弹簧,实 现压力调节范围在一定范围内快速更换; 3、ZZYP自力式压力调节阀一般采用波纹管作为压力平衡元件,阀前、后压力变化不影响阀芯的受力 情况,大大加快阀门的响应速度,从而提高阀门的调节精度; 减压阀
网页中文乱码完美解决方案
网页中文乱码 既然后面charset设置为gb2312,那么你打开这个网页,然后另存,保存的时候记得把编码改成gb2312,不然的话charset就会误导浏览器,这样就会乱码了。 2.php编网页出现乱码,我把编码改成utf-8 前台显示正常了,但是有东西输入到数据库再提取出来还是不正常 3.apache+php+mysql 为何会出现乱码 我们在做PHP项目的时候,经常会遇到中文乱码的问题,有时候编码问题还导致MYSQL的报错。中文乱码总共有三个原因 1:APACHE服务器设置导致乱码 2:PHP,或者HTML页面编码导致中文乱码 3:MYSQL数据库的表以及字段编码导致中文乱码 我们分别从这三个部分来探究PHP程序设计中的编码问题 在这之前我们要了解一些基本理论: 1、文件编码 每个文件在保存的时候都可以选择以什么编码保存,例如用WINDOWS的记事本创建一个文件可以选择ANSI 以及UTF8等等编码。我们选择了什么编码该文件就以这种编码方式保存在硬盘上。读取该文件数据的时候也会指定一种编码来打开,如果指定的编码与文件保存的时候的编码不一样的话就会出现乱码 2、HTML的编码 在网页头部一般有这样一个 区域 这个的意思是让客户端知道,接下来输出的是html代码(text/html),并且以下输出的内容都将是utf-8编码的。如果我们用记事本创建一个HTML文件该文件包含 但是在保存的时候却以ANSI编码格式保存,那么我们用浏览器打开这个文件时,浏览器看见META 行的UTF8编码设置后就将文件以UTF8格式输出,而文件本来是ANSI编码,这样便出现了中文乱码。 一:APACHE服务器编码 在APACHE配置文件中有一行是编码的设置默认的是AddDefaultCharset ISO-8859-1,大部分人认为应该将这句改为AddDefaultCharset UTF-8 。而蜗牛认为这是误人子弟。这项配置是告诉APACHE服务器选用什么样的编码来输出WEB页面(这样做会忽略,HTML页面中的页面编码的设置EG:),如果我们建立一个GB2312的页面就会出现中文乱码。所以最好的方法是将AddDefaultCharset ISO-8859-1这一项注释掉#AddDefaultCharset 二:PHP编码问题 php最终生成的是文本文件,而他要从数据库中取出文本数据,还要把文本数据写到数据库中。由于MYSQL并不知道PHP发送给他的是什么编码的数据,所以需要客户端PHP告诉他存取的是什么编码的数据。然后MYSQL会自动将PHP传送来的数据转换成目标编码格式的
mysql中文乱码解决
转载:Mysql中文乱码的解决方法 第一种方法,很精辟的总结: 经常更换虚拟主机,而各个服务商的MYSQL版本不同,当导入数据后,总会出现乱码等无法正常显示的问题,查了好多资料,总结出自己的一点技巧: WINDOWS 下导入应该这样 使用MYSQL的命令 在DOS 命令下进入mysql的bin目录下,输入mysql -uroot -p密码数据库名称<要恢复的数据库, 例如我们要把D盘的一个名称为test.sql的数据库恢复到本地的test2这个数据库,那么就这样: mysql -uroot -p密码test2以前的国外主机用的Mysql是4.x系列的,感觉还比较好,都无论GBK和UTF-8都没有乱码,没想到新的主机的Mysql是5.0版本的,导入数据后,用Php读出来全是问号,乱码一片,记得我以前也曾经有过一次切换出现乱码的经验,原因肯定是Mysql版本之间的差异问题。 只好查资料,发现了一个解决方法,就是在mysql_connect后面加一句SET NAMES UTF8,即可使得UTF8的数据库消除乱码,对于GBK的数据库则使用SET NAMES GBK,代码如下: $mysql_mylink = mysql_connect($mysql_host, $mysql_user, $mysql_pass); mysql_query("SET NAMES 'GBK'"); 数据库字符集为utf-8 连接语句用这个 mysql_query("SET NAMES 'UTF8'"); mysql_query("SET CHARACTER SET UTF8"); mysql_query("SET CHARACTER_SET_RESULTS=UTF8'");
相关文档
- Android读取中文文件乱码解决方法
- 有关JSP和数据库乱码问题的处理方式
- MYSQL使用UTF8中文乱码解决办法
- JSP中文乱码问题完全解决方案
- 中文乱码解决大全
- DOS 中文乱码解决办法
- 关于Linux下中文乱码的完整解决方案
- 中文乱码解决方案
- struts中中文乱码处理解决方案
- java中文乱码问题解决方案
- win7系统常见的乱码问题解决方法
- Flash中出现中文乱码的解决办法
- 中文乱码解决汇总
- matlab中文显示乱码解决办法
- java中文乱码终极解决方案
- 中文乱码解决方法
- 命令提示符 中文显示乱码的解决方法
- MyEclipse中导入项目时出现乱码的解决方案
- 表单提交(GET或POST)中文乱码解决方案
- cmd窗口显示中文乱码及无法输入中文解决方法