Springboot SpringMVC thymeleaf页面提交Validation实现实例
Springboot+SpringMVC+thymeleaf页面提交Validation实现实例
本例所使用的框架:
1.Spring boot
2.Spring MVC
3.thymeleaf
说明:
1.本文针对采用Spring boot微框架之用户,完全采用Java config,不讨论xml
配置。
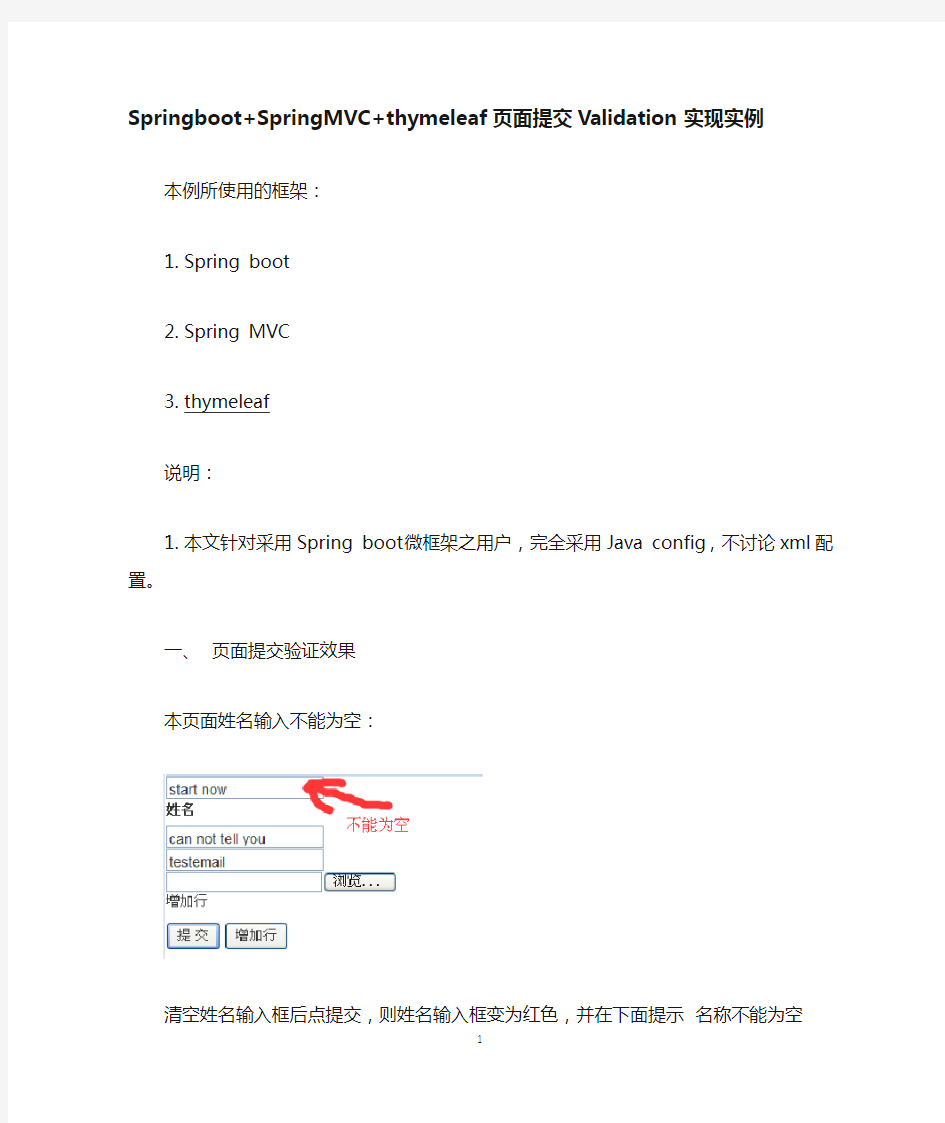
一、页面提交验证效果
本页面姓名输入不能为空:
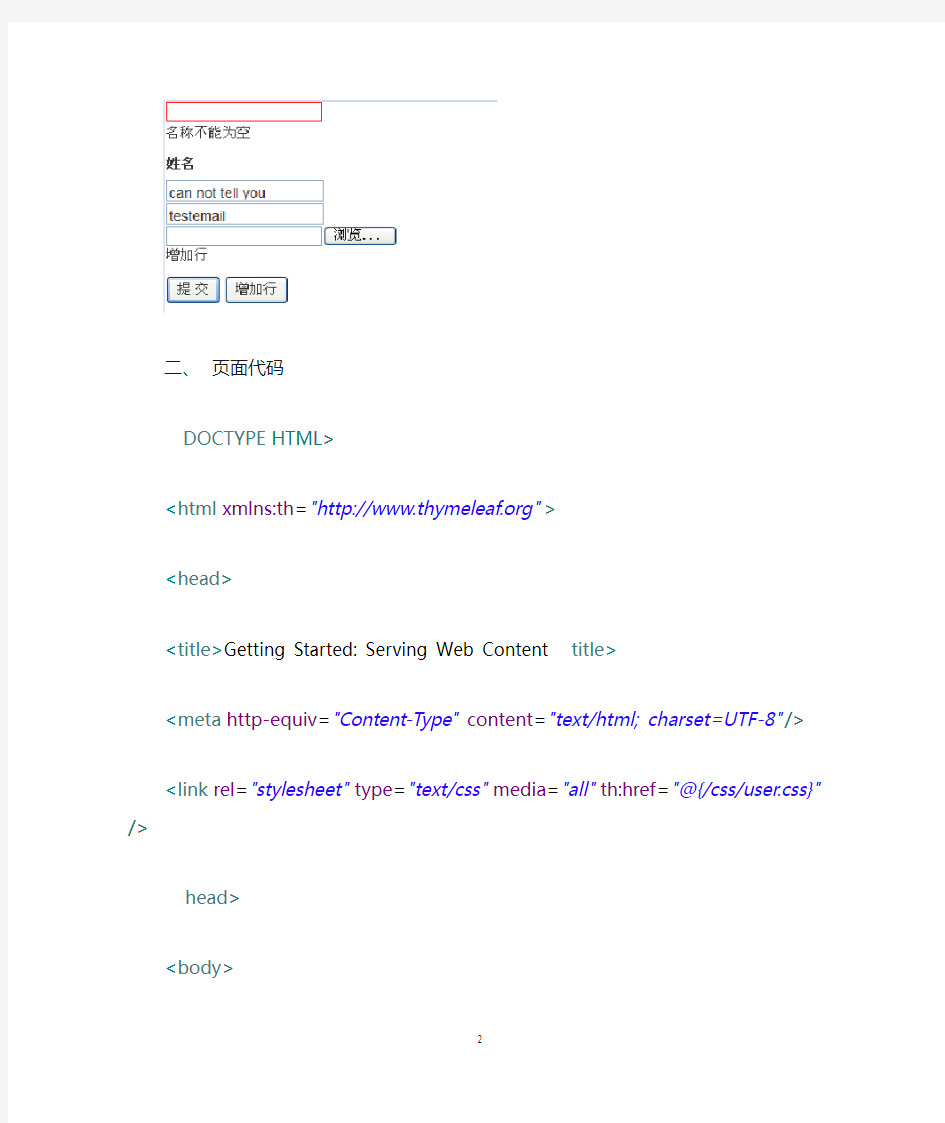
清空姓名输入框后点提交,则姓名输入框变为红色,并在下面提示名称不能为空
二、页面代码
th:href="@{/css/user.css}"/>
上文中,
绑定了user实例的fname属性,并指定发生错误时,该输入框使用名为fieldError的CSS样式。
th:errors="*{fname}">Incorrect data
这里是一个错误信息提示区域,当fname属性的输入值不符合校验规则时,在这里输出错误提示。当输入正确时,该区域不现实。
三、CSS代码(user.css)
.fieldError{
border:1px solid red;
}
出现错误時,输入框变为红色。
四、Controller代码
// 页面中使用的user
@RequestMapping(value = "/user", method = RequestMethod.GET)
public String getuser(Model model) {
if(!model.containsAttribute("user")){
SUser user=new SUser();
model.addAttribute("user", user);
user.setFname("start now");
user.setPassword("can not tell you");
user.setEmail("testemail");
}
return"user";
}
//@Valid @ModelAttribute("user") SUser user 将user绑定到model中的user属性后就进行验证。
//如果不绑定,则return getuser(model)后,model中将没有user
属性。
@RequestMapping(value = "/user", method = RequestMethod.POST, params = "save")
public String submitparam(Model model,@Valid
@ModelAttribute("user") SUser user,BindingResult result) {
return getuser(model);
}
五、User代码
public class SUser implements java.io.Serializable {
private Integer did;
private int orgDid;
private int humDid;
//在这里指定了fname属性出现错误时的提示信息。
//这个信息定义在ValidationMessages.properties中定义
@NotBlank(message="{name.not.empty}")
private String fname;
private String password;
private String email;
private Integer mobile;
private String qq;
private Date dob;
private String bref;
private Set
public SUser() {
}
public SUser(int orgDid, int humDid) {
https://www.sodocs.net/doc/b715268699.html,Did = orgDid;
this.humDid = humDid;
}
public SUser(int orgDid, int humDid, String fname, String password, String email, Integer mobile, String qq,
Date dob, String bref, Set
this.humDid = humDid;
this.fname = fname;
this.password = password;
this.email = email;
this.mobile = mobile;
this.qq = qq;
this.dob = dob;
this.bref = bref;
this.SRoles = SRoles;
}
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "did", unique = true, nullable = false) public Integer getDid() {
return this.did;
}
public void setDid(Integer did) {
this.did = did;
}
@Column(name = "org_did", nullable = false)
public int getOrgDid() {
return https://www.sodocs.net/doc/b715268699.html,Did;
}
public void setOrgDid(int orgDid) {
https://www.sodocs.net/doc/b715268699.html,Did = orgDid;
}
@Column(name = "hum_did", nullable = false)
public int getHumDid() {
return this.humDid;
}
public void setHumDid(int humDid) { this.humDid = humDid;
}
@Column(name = "fname", length = 40)
public String getFname() {
return this.fname;
}
public void setFname(String fname) { this.fname = fname;
}
@Column(name = "password", length = 100) public String getPassword() {
return this.password;
}
public void setPassword(String password) { this.password = password;
}
@Column(name = "email", length = 32)
public String getEmail() {
return this.email;
}
public void setEmail(String email) {
this.email = email;
}
@Column(name = "mobile")
public Integer getMobile() {
return this.mobile;
}
public void setMobile(Integer mobile) { this.mobile = mobile;
}
@Column(name = "qq", length = 20)
public String getQq() {
return this.qq;
}
public void setQq(String qq) {
this.qq = qq;
}
@Temporal(TemporalType.DATE)
@Column(name = "dob", length = 10) public Date getDob() {
return this.dob;
}
public void setDob(Date dob) {
this.dob = dob;
}
@Column(name = "bref", length = 10)
public String getBref() {
return this.bref;
}
public void setBref(String bref) {
this.bref = bref;
}
@OneToMany(fetch = FetchType.EAGER, mappedBy = "SUser") public Set
return this.SRoles;
}
public void setSRoles(Set
this.SRoles = SRoles;
}
}
六、ValidationMessages.properties
name.not.empty=名称不能为空
请注意,必须是ValidationMessages.properties这个名字,大小写不能错。
该文件需要放在src目录下,如图:
以上是全部代码和配置。
网页数据采集器如何使用
https://www.sodocs.net/doc/b715268699.html, 网页数据采集器如何使用 新浪微博是目前国内比较火的一个社交互动平台,明星、各大品牌都有注册官方微博,有什么活动也都会在微博上宣传造势,和粉丝评论互动。普通人平常也喜欢将生活中的点滴分享到微博,所以微博聚集了大批的用户。本文就以使用八爪鱼采集器的简易模式采集新浪微博数据为例子,为大家介绍网页数据采集器的使用方法。 需要采集微博内容的,在网页简易采集界面里点击微博网页进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据采集器的使用步骤1 采集微博主页面或主页中不同版块的信息(下图所示)即打开微博主页后采集该页面的内容。 1、找到微博主页面信息采集规则然后点击立即使用
https://www.sodocs.net/doc/b715268699.html, 新浪微博数据采集器的使用步骤2 2、下图显示的即为简易模式里面微博主页面信息采集的规则 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博主页面信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 网址:设置要采集的网址,如果有多个网址用回车(Enter)分隔开,一行一个。支持输入微博首页网址和首页各个子版本的网址,如 https://www.sodocs.net/doc/b715268699.html,/?category=1760 示例数据:这个规则采集的所有字段信息
https://www.sodocs.net/doc/b715268699.html, 新浪微博数据采集器的使用步骤3 3、规则制作示例 例如采集微博主页面和社会版块的信息。设置如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 网址:从浏览器中将要采集网址复制黏贴到输入框中,本示例为https://www.sodocs.net/doc/b715268699.html,/ https://www.sodocs.net/doc/b715268699.html,/?category=7 设置好之后点击保存
大数据采集工具如何使用
https://www.sodocs.net/doc/b715268699.html, 大数据采集工具如何使用 在商业活动,大数据已然成为必不可少的参考依据,通过对大数据的挖掘分析处理能为商业决策、战略部署、企业发展提供准确的指导。特别是电子商务,即时采集商品的价格、销量、评价等大量信息进行处理分析,形成反馈结果应用到实际中,能为商业活动带来巨大的经济价值。因而,掌握大数据采集工具如何使用是必须的。 对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,网页简易模式下存放了国内一些主流网站爬虫采集规则,在你需要采集相关网站时可以直接调用,节省了制作规则的时间以及精力。 天猫商品数据采集下来有很多作用,比如可以分析天猫商品价格变化趋势情况,评价数量,竞品销量和价格,竞争店铺分析等,快速掌握市场行情,帮助企业决策。 所以本次介绍八爪鱼简易采集模式下“天猫数据抓取”的使用教程以及注意要点。步骤一、下载八爪鱼软件并登陆 1、打开https://www.sodocs.net/doc/b715268699.html,/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.sodocs.net/doc/b715268699.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆。
https://www.sodocs.net/doc/b715268699.html, 步骤二、设置天猫商品列表抓取规则 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.sodocs.net/doc/b715268699.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集京东内容的,这里选择天猫即可。
https://www.sodocs.net/doc/b715268699.html, 3、找到天猫商品列表采集这条爬虫规则,点击即可使用。
WEB数据采集系统
WEB数据采集系统 一.概述 面对互联网海量的信息,政府机关、企事业单位和研究机构都迫切希望获取与自身工作相关的有价值信息,如何方便快捷地获取这些信息就变得至关重要了。如果采用原始的手工收集方式,费时费力且毫无效率,面对越来越多的信息资源,劳动强度和难度可想而知。因此,现代的政府和企业都迫切需要一种能够提供高质量和高效运作的信息采集解决方案。 本系统针对不同行业用户的应用需求,以抓取互联网为目的,实现在用户自定义规则下,从互联网中抓取指定信息。抓取的信息可存入数据库或直接入库发送至指定栏目,实现网站信息及时更新和数据量提升,从而使得搜索引擎收录量提升,扩大企业信息宣传推广力度。 二.典型应用 1. 政府机关 ●实时跟踪、采集与业务工作相关的信息来源。 ●全面满足内部工作人员对互联网信息的全局观测需求。 ●及时解决政务外网、政务内网的信息源问题,实现动态发布。 ●快速解决政府主网站对各地级子网站的信息获取需求。 ●全面整合信息,实现政府内部跨地区、跨部门的信息资源共享与有效 沟通。 ●节约信息采集的人力、物力、时间,提高办公效率。
2. 企业 ●实时准确地监控、追踪竞争对手动态,是企业获取竞争情报的利器。 ●及时获取竞争对手的公开信息以便研究同行业的发展与市场需求。 ●为企业决策部门和管理层提供便捷、多途径的企业战略决策工具。 ●大幅度地提高企业获取、利用情报的效率,节省情报信息收集、存 储、挖掘的相关费用,是提高企业核心竞争力的关键。 ●提高企业整体分析研究能力、市场快速反应能力,建立起以知识管 ,是提高企业核心竞争力的神经中枢。 理为核心的“竞争情报数据仓库” 3. 新闻媒体 ●快速准确地自动采集数信息。 ●支持每天对数万条新闻进行有效抓取。 ●支持对所需内容的智能提取、审核。 ●实现互联网信息内容采集、浏览、编辑、管理、发布的一体化。三. 系统构架 工作过程描述 采集的目的就是把对方网站上网页中的某块文字或者图片等资源下载到自己的站网上,这个过程需要做如下配置工作:下载网页配置,解析网页配置,修正结果配置,数据输出配置。如果数据符合自己要求,修正结果这步可省略。配置完毕后,把配置形成任务(任务以XML格式描述),采集系统
国内主要信息抓取软件盘点
国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序
网页抓取工具如何进行http模拟请求
网页抓取工具如何进行http模拟请求 在使用网页抓取工具采集网页是,进行http模拟请求可以通过浏览器自动获取登录cookie、返回头信息,查看源码等。具体如何操作呢?这里分享给大家网页抓取工具火车采集器V9中的http模拟请求。许多请求工具都是仿照火车采集器中的请求工具所写,因此大家可以此为例学习一下。 http模拟请求可以设置如何发起一个http请求,包括设置请求信息,返回头信息等。并具有自动提交的功能。工具主要包含两大部分:一个MDI父窗体和请求配置窗体。 1.1请求地址:正确填写请求的链接。 1.2请求信息:常规设置和更高级设置两部分。 (1)常规设置: ①来源页:正确填写请求页来源页地址。 ②发送方式:get和post,当选择post时,请在发送数据文本框正确填写发布数据。 ③客户端:选择或粘贴浏览器类型至此处。 ④cookie值:读取本地登录信息和自定义两种选择。 高级设置:包含如图所示系列设置,当不需要以上高级设置时,点击关闭按钮即可。 ①网页压缩:选择压缩方式,可全选,对应请求头信息的Accept-Encoding。 ②网页编码:自动识别和自定义两种选择,若选中自定义,自定义后面会出现编
码选择框,在选择框选择请求的编码。 ③Keep-Alive:决定当前请求是否与internet资源建立持久性链接。 ④自动跳转:决定当前请求是否应跟随重定向响应。 ⑤基于Windows身份验证类型的表单:正确填写用户名,密码,域即可,无身份认证时不必填写。 ⑥更多发送头信息:显示发送的头信息,以列表形式显示更清晰直观的了解到请求的头信息。此处的头信息供用户选填的,若要将某一名称的头信息进行请求,勾选Header名对应的复选框即可,Header名和Header值都是可以进行编辑的。 1.3返回头信息:将详细罗列请求成功之后返回的头信息,如下图。 1.4源码:待请求完毕后,工具会自动跳转到源码选项,在此可查看请求成功之后所返回的页面源码信息。 1.5预览:可在此预览请求成功之后返回的页面。 1.6自动操作选项:可设置自动刷新/提交的时间间隔和运行次数,启用此操作后,工具会自动的按一定的时间间隔和运行次数向服务器自动请求,若想取消此操作,点击后面的停止按钮即可。 配置好上述信息后,点击“开始查看”按钮即可查看请求信息,返回头信息等,为避免填写请求信息,可以点击“粘贴外部监视HTTP请求数据”按钮粘贴请求的头信息,然后点击开始查看按钮即可。这种捷径是在粘贴的头信息格式正确的前提下,否则会弹出错误提示框。 更多有关网页抓取工具或网页采集的教程都可以从火车采集器的系列教程中学习借鉴。
网站爬虫如何爬取数据
https://www.sodocs.net/doc/b715268699.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.sodocs.net/doc/b715268699.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.sodocs.net/doc/b715268699.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.sodocs.net/doc/b715268699.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.sodocs.net/doc/b715268699.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.sodocs.net/doc/b715268699.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
国内主要数据采集和抓取工具
国内6大网络信息采集和页面数据抓取工具 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统(https://www.sodocs.net/doc/b715268699.html,) 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 该系统主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器(https://www.sodocs.net/doc/b715268699.html,) 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件(https://www.sodocs.net/doc/b715268699.html,) 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器(https://www.sodocs.net/doc/b715268699.html,) 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序的区别,狂人采集器分论坛采集器、CMS采集器和博客采集器三类,总计支持近40种主流建站程序的上百个版本的数据采集和发布任务,支持图片本地化,支持网站登陆采集,分页抓取,全面模拟人工登陆发布,软件运行快速安全稳定!论坛采集器还支持论坛会员无限注册,自动增加帖子查看人数,自动顶贴等。 TOP.5 网络神采(https://www.sodocs.net/doc/b715268699.html,) 网络神采是一款专业的网络信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富 [hide]
var $getreplytime=1; var $showimg=1; var $showcon=1; var $showauthor=1; var $showreplytime=1; var $showsn=0; var $showhr=0; var $replylista=array(); var $pat_reply="<\/a>(.+?)
<\/td>\r\n<\/tr><\/table>"; var $pat_pagecount="尾页<\/font><\/a>"; var $pat_title="(.+?)<\/font>"; var $pat_replycon="<\/td>\r\n \r\n