实战聚类

这篇文章与上一篇的回归分析是一次实习作业整理出来的。所以参考文献一并放在该文最后。CNBlOG网页排版太困难了,又不喜欢live writer……
聚类分析是将物理或者抽象对象的集合分成相似的对象类的过程。本次实验我将对同一批数据做两种不同的类型的聚类;它们分别是系统聚类和K-mean聚类。其中系统聚类的聚类方法也采用3种不同方法,来考察对比它们之间的优劣。由于没有样本数据,因此不能根据其数据做判别分析。评价标准主要是观察各聚类方法的所得到的类组间距离和组内聚类的大小。
分析数据依然采用线性回归所使用的标准化后的能源消费数据。
1.1 系统聚类
本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。1.1.1 最短距离聚类法
最短距离法聚类步骤如下:
1.规定样本间的距离,计算样本两两之
间的距离,得到对称矩阵。开始每个
样品自成一类。
2.选择对称矩阵中的最小非零元素。将
两个样品之间最小距离记为D1,将
这两个样品归并成为一类,记为G1。
3.计算G1与其他样品距离。重复以上
过程直到所有样品合并为一类。
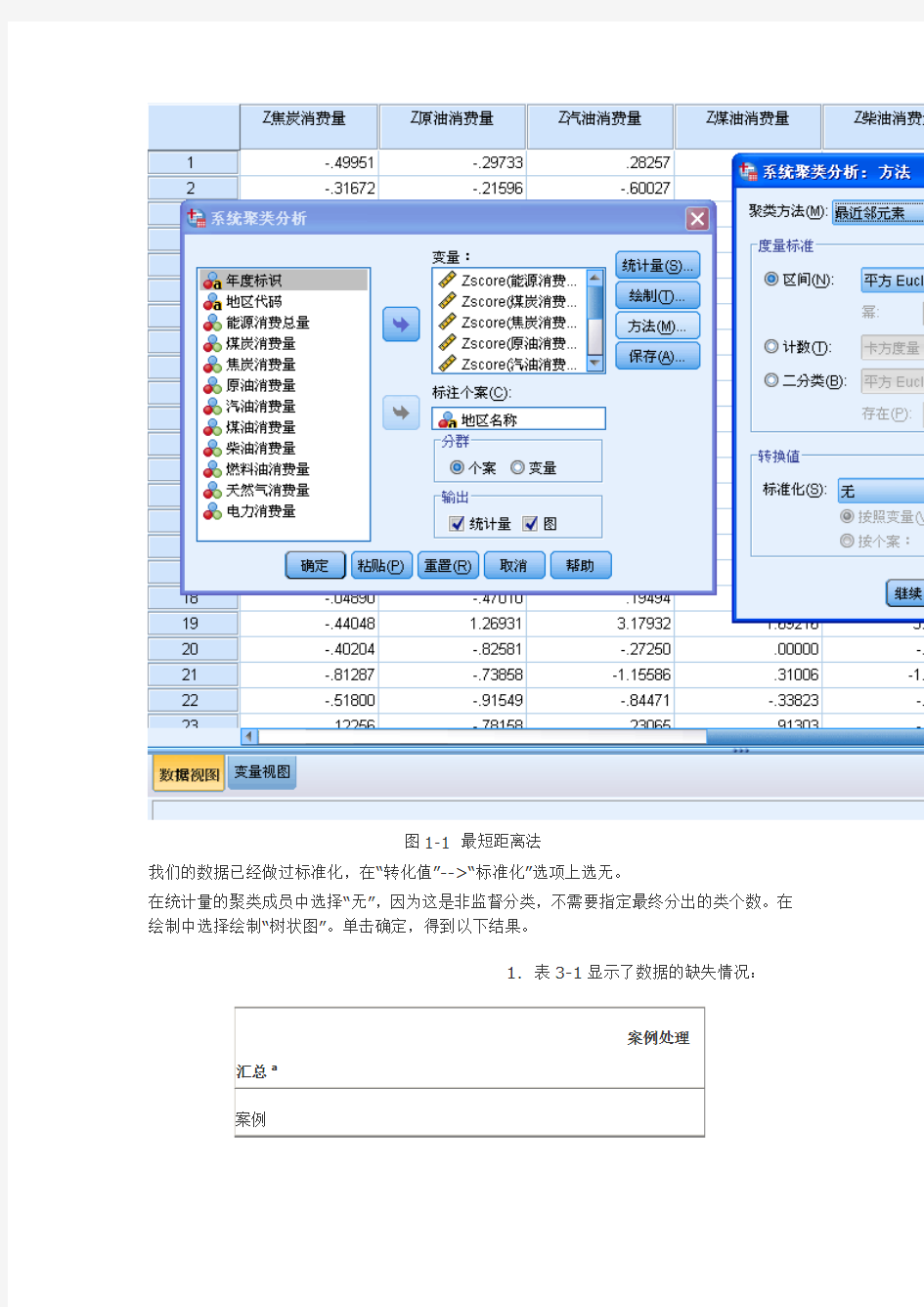
我们在SPSS中实现最短距离分析非常简单。单击“”-->“”
-->“”。将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法
我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。在绘制中选择绘制“树状图”。单击确定,得到以下结果。
1.表3-1显示了数据的缺失情况:
图1-2 最短距离法聚类图1.1.2 组间联接聚类
组间联接聚类法定义为两类之间的平均平方距离,即
。类C K 和C L 合并为下一步的C M 则C M 与C J 距离
的递推公式为:
。
我们依然贴出组间联接法的聚类表和树状图。
1. 聚类表如表1-3所示,相关解释类似
于表1-1所述。
表1-2 组间联接聚类法
2. 树状图如图1-3所示,可以看到聚类的组间距离较大,组内距离较小。聚类结果较为理想。可以看到海南与青海,宁夏自治区,重庆市的能源消耗特点近似,北京、上海两地能源消耗特点也近似。江浙两地亦然。
最后广东和各地能源消耗特点都不同。
1.1.3 Ward法聚类
Ward即离差平方和法。它的思想是,同类离差平方和较小,类间偏差平方和较大。Ward 方法并类时总是使得并类导致的类内离差平方和增量最小。公式:
递推公式:
我依然贴出ward法聚类表和树状图。
1.聚类表如表1-4所示,相关解释类似
于表1-1所述.
表1-4 Ward法聚类表
2. 树状图如图1-4所示,我们可以看到这个结果较以上两种方法都为理想,组内距离都很小,控制在五次迭代之内。然后组间距离非常大。各分类的样品也基本符合它们的能源消耗特点。最后在接近10次迭代,广东被归入山东、山西这两个分别是能源消耗大省和能源产量大省的一类,说明它们之间的相似度也不大。
图1-4 Ward法聚类树状图1.2 K-mean聚类
K-mean聚类是用户指定类别数的大样本资料的逐步聚类分析。所谓逐步聚类分析就是先把被聚对象进行初始分类,然后逐步调整,得到最终K个分类。 K-mean法对离群点敏感容易扭曲数据分布。
单击“”-->“” -->“”将弹出如图1-5所示的对话框,我们根据系统聚类法的经验将K选择为5。迭代次数和系统聚类一样选择25次。
图1-5 K-mean聚类设置
下面输出和解释K-mean聚类结果。
1.表1-5是K-mean的迭代历史记录,
非常明了。
表1-5 迭代历史记录
2. 表1-6是每个聚类样品数表。就是该次K-mean聚类所形成的类它们的样品数量。
表1-6 聚类样品数
3. 表1-7是K-mean聚类的各个类的具体成员。距离代表的是样品自身和种子点的距离。
表1-7 聚类成员
最后看到分类结果与ward法有所相似,但是组内距离较大。实际效果不如Ward法。而且该方法需要事先设定分类的个数,并不适合没有先验知识的条件下的数据聚类。
2.总结
本次实习主要通过一批国内的能源消耗和产量数据,来实现回归分析和聚类分析。回归分析得到一个拟合度良好多元线性回归方程:Y=0.008+1.061x1+0.087x2+0.157
x3-0.365x4-0.105 x5-0.017x6 。该方程的残差分析也通过了。聚类分析通过比较三种不同的系统聚类方法,同时还比较了K-mean方法与系统聚类法的不同。在处理该批数据的四种聚类方法中,以ward法最为理想。Ward法所做的聚类得到组间距离最大,组内距离最小。
应用多元统计分析习题解答_聚类分析..-共20页
第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p i j i k j k k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
应用多元统计分析习题解答_第五章
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
模糊聚类分析报告例子
1. 模糊聚类分析模型 环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。设这5个环境区域的污染数据为1x =(80, 10, 6, 2), 2x =(50, 1, 6, 4), 3x =(90, 6, 4, 6), 4x =(40, 5, 7, 3), 5x =(10, 1, 2, 4). 试用模糊传递闭包法对X 进行分类。 解 : 由题设知特性指标矩阵为: * 80106250164906464057310124X ????????=???????? 数据规格化:最大规格化' ij ij j x x M = 其中: 12max(,,...,)j j j nj M x x x = 00.8910.860.330.560.1 0.860.671 0.60.5710.440.510.50.11 0.1 0.290.67X ????????=?? ?????? 构造模糊相似矩阵: 采用最大最小法来构造模糊相似矩阵55()ij R r ?=, 1 0.540.620.630.240.5410.550.700.530.62 0.5510.560.370.630.700.5610.380.240.530.370.381R ?? ??? ???=?? ?????? 利用平方自合成方法求传递闭包t (R ) 依次计算248,,R R R , 由于84R R =,所以4()t R R =
2 10.630.620.630.530.6310.560.700.530.62 0.5610.620.530.630.700.6210.530.530.530.530.531R ?? ??????=?? ??????, 4 10.630.620.630.530.6310.620.700.530.62 0.6210.620.530.630.700.6210.530.53 0.530.530.531R ????????=?? ?????? =8R 选取适当的置信水平值[0,1]λ∈, 按λ截矩阵进行动态聚类。把()t R 中的元素从大到小的顺序编排如下: 1>0.70>0.63>062>053. 依次取λ=1, 0.70, 0.63, 062, 053,得 11 000001000()0 010******* 0001t R ????? ? ??=?? ??????,此时X 被分为5类:{1x },{2x },{3x },{4x },{5x } 0.7 1000001010()001000101000001t R ?????? ??=?? ??????,此时X 被分为4类:{1x },{2x ,4x },{3x },{5x } 0.63 1101011010()001001101000001t R ?????? ??=?? ??????,此时X 被分为3类:{1x ,2x ,4x },{3x },{5x } 0.62 1111011110()11110111100 0001t R ?????? ??=?? ?????? ,此时X 被分为2类:{1x ,2x ,4x ,3x },{5x }
聚类分析实例分析题(推荐文档)
5.2酿酒葡萄的等级划分 5.2.1葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[61.6,81.5]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。 通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7):
考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。 5.2.2建立模型 在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward 最小方差法,又叫做离差平方和法。 聚类分析是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。为了将样品进行分类,就需要研究样品之间关系。这里的最小方差法的基本思想就是将一个样品看作P 维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。面对现在的问题,我们不知道元素的分类,连要分成几类都不知道。现在我们将用SAS 系统里面的stepdisc 和cluster 过程完成判别分析和聚类分析,最终确定元素对象的分类问题。 建立数据阵,具体数学表示为: 1111...............m n nm X X X X X ????=?????? (5.2.1) 式中,行向量1(,...,)i i im X x x =表示第i 个样品; 列向量1(,...,)'j j nj X x x =’,表示第j 项指标。(i=1,2,…,n;j=1,2,…m) 接下来我们将要对数据进行变化,以便于我们比较和消除纲量。在此我们用了使用最广范的方法,ward 最小方差法。其中用到了类间距离来进行比较,定义为: 2||||/(1/1/)kl k l k l D X X n n =-+ (5.2.2) Ward 方法并类时总是使得并类导致的类内离差平方和增量最小。 系统聚类数的确定。在聚类分析中,系统聚类最终得到的一个聚类树,如何确定类的个数,这是一个十分困难但又必须解决的问题;因为分类本身就没有一定标准,人们可以从不同的角度给出不同的分类。在实际应用中常使用下面几种
聚类分析的案例分析(推荐文档)
《应用多元统计分析》 ——报告 班级: 学号: 姓名:
聚类分析的案例分析 摘要 本文主要用SPSS软件对实验数据运用系统聚类法和K均值聚类法进行聚类分析,从而实现聚类分析及其运用。利用聚类分析研究某化工厂周围的几个地区的 气体浓度的情况,从而判断出这几个地区的污染程度。 经过聚类分析可以得到,样本6这一地区的气体浓度值最高,污染程度是最严重的,样本3和样本4气体浓度较高,污染程度也比较严重,因此要给予及时的控制和改善。 关键词:SPSS软件聚类分析学生成绩
一、数学模型 聚类分析的基本思想是认为各个样本与所选择的指标之间存在着不同程度的相 似性。可以根据这些相似性把相似程度较高的归为一类,从而对其总体进行分析和总结,判断其之间的差距。 系统聚类法的基本思想是在这几个样本之间定义其之间的距离,在多个变量之间定义其相似系数,距离或者相似系数代表着样本或者变量之间的相似程度。根据相似程度的不同大小,将样本进行归类,将关系较为密切的归为一类,关系较为疏远的后归为一类,用不同的方法将所有的样本都聚到合适的类中,这里我们用的是最近距离法,形成一个聚类树形图,可据此清楚的看出样本的分类情况。 K 均值法是将每个样品分配给最近中心的类中,只产生指定类数的聚类结果。 二、数据来源 《应用多元统计分析》第一版164 页第6 题 我国山区有一某大型化工厂,在该厂区的邻近地区中挑选其中最具有代表性的 8 个大气取样点,在固定的时间点每日 4 次抽取6 种大气样本,测定其中包含的8 个取样点中每种气体的平均浓度,数据如下表。试用聚类分析方法对取样点及 大气污染气体进行分类。 三、建立数学模型 一、运行过程
聚类分析实例
k-means聚类”——数据分析、数据挖掘 一、概要 分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但是很多时候上述条件得不到满足,尤其是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,这时候可以考虑使用聚类算法。聚类属于无监督学习,相比于分类,聚类不依赖预定义的类和类标号的训练实例。本文介绍一种常见的聚类算法——k 均值和k 中心点聚类,最后会举一个实例:应用聚类方法试图解决一个在体育界大家颇具争议的问题——中国男足近几年在亚洲到底处于几流水平。 二、聚类问题 所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n 个可观察属性,使用某种算法将D 划分成k 个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。 与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。本文仅介绍一种最简单的聚类算法——k 均值(k-means)算法。 三、概念介绍 区分两个概念: hard clustering:一个文档要么属于类w,要么不属于类w,即文档对确定的类w是二值的1或0。
soft clustering:一个文档可以属于类w1,同时也可以属于w2,而且文档属于一个类的值不是0或1,可以是这样的小数。 K-Means就是一种hard clustering,所谓K-means里的K就是我们要事先指定分类的个数,即K个。 k-means算法的流程如下: 1)从N个文档随机选取K个文档作为初始质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类 3)重新计算已经得到的各个类的质心 4)迭代2~3步直至满足既定的条件,算法结束 在K-means算法里所有的文档都必须向量化,n个文档的质心可以认为是这n 个向量的中心,计算方法如下: 这里加入一个方差RSS的概念: RSSk的值是类k中每个文档到质心的距离,RSS是所有k个类的RSS值的和。 算法结束条件: 1)给定一个迭代次数,达到这个次数就停止,这好像不是一个好建议。
一篇文章透彻解读聚类分析及案例实操
一篇文章透彻解读聚类分析及案例实操 【数盟致力于成为最卓越的数据科学社区,聚焦于大数据、分析挖掘、数据可视化领域,业务范围:线下活动、在线课程、猎头服务、项目对接】【限时优惠福利】数据定义 未来,2016年5月12日-14日DTCC2016中国数据库技术大会登陆北京!大会云集了国内外数据行业顶尖专家,设定2个主会场,24个分会场,将吸引共3000多名IT人士参会!马上领取数盟专属购票优惠88折上折,猛戳文末“阅读原文”抢先购票! 摘要:本文主要是介绍一下SAS的聚类案例,希望大家都 动手做一遍,很多问题只有在亲自动手的过程中才会有发现有收获有心得。这里重点拿常见的工具SAS+R语言+Python 介绍! 1 聚类分析介绍1.1 基本概念聚类就是一种寻找数据之间 一种内在结构的技术。聚类把全体数据实例组织成一些相似组,而这些相似组被称作聚类。处于相同聚类中的数据实例彼此相同,处于不同聚类中的实例彼此不同。聚类技术通常又被称为无监督学习,因为与监督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。通过上述表述,我们可以把聚类定义为将数据集中在某些方面具有相似性 的数据成员进行分类组织的过程。因此,聚类就是一些数据
实例的集合,这个集合中的元素彼此相似,但是它们都与其他聚类中的元素不同。在聚类的相关文献中,一个数据实例有时又被称为对象,因为现实世界中的一个对象可以用数据实例来描述。同时,它有时也被称作数据点(Data Point),因为我们可以用r 维空间的一个点来表示数据实例,其中r 表示数据的属性个数。下图显示了一个二维数据集聚类过程,从该图中可以清楚地看到数据聚类过程。虽然通过目测可以十分清晰地发现隐藏在二维或者三维的数据集中的聚类,但是随着数据集维数的不断增加,就很难通过目测来观察甚至是不可能。 1.2 算法概述 目前在存在大量的聚类算法,算法的选择取决于数据的类型、聚类的目的和具体应用。大体上,主要的聚类算法分为几大类。 聚类算法的目的是将数据对象自动的归入到相应的有意义 的聚类中。追求较高的类内相似度和较低的类间相似度是聚类算法的指导原则。一个聚类算法的优劣可以从以下几个方面来衡量: (1)可伸缩性:好的聚类算法可以处理包含大到几百万个对象的数据集;(2)处理不同类型属性的能力:许多算法是针对基 于区间的数值属性而设计的,但是有些应用需要针对其它数据类型(如符号类型、二值类型等)进行处理;(3)发现任意形状
聚类分析例题及解答
聚类分析作业 例题: country populatn density urban religion lifeexpf lifeexpm literacy pop_incr Afghanistan 20,500 25、0 18 Muslim 44 45 29 2、8 Bangladesh 125,000 800、0 16 Muslim 53 53 35 2、4 Cambodia 10,000 55、0 12 Buddhist 52 50 35 2、9 China 1,205,200 124、0 26 Taoist 69 67 78 1、1 HongKong 5,800 5,494、0 94 Buddhist 80 75 77 -0、1 India 911,600 283、0 26 Hindu 59 58 52 1、9 Indonesia 199,700 102、0 29 Muslim 65 61 77 1、6 Japan 125,500 330、0 77 Buddhist 82 76 99 0、3 Malaysia 19,500 58、0 43 Muslim 72 66 78 2、3 N、Korea 23,100 189、0 60 Buddhist 73 67 99 1、8 Pakistan 128,100 143、0 32 Muslim 58 57 35 2、8 Philippines 69,800 221、0 43 Catholic 68 63 90 1、9 S、Korea 45,000 447、0 72 Protstnt 74 68 96 1、0 Singapore 2,900 4,456、0 100 Taoist 79 73 88 1、2 Taiwan 20,944 582、0 71 Buddhist 78 72 91 0、9 Thailand 59,400 115、0 22 Buddhist 72 65 93 1、4 Vietnam 73,100 218、0 20 Buddhist 68 63 88 1、8 进行聚类分析,步骤如下: 1、标准化的欧式距离聚类 各类所属 得出以上结果,以欧氏距离为计算距离方法,把以上17个亚洲国家地区按6个变量欧氏距离划分为三类。 第一类为:Bangladesh 第二类为:China 第三类为:Malaysia 2、尝试其她类间距离方法
SPSS教程-聚类分析-附实例操作
各地区各行业工资水平的分析(2009年数据) 小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍 1.研究背景及意义 1.1 研究背景 工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。 1.2 研究意义 1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。 2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。 2.数据来源与描述 2.1 数据来源——《中国劳动统计年鉴─2010》 (URL:https://www.sodocs.net/doc/054949924.html,/Navi/YearBook.aspx?id=N2011010069&floor=1###) 主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司 出版社:中国统计出版社 简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。 2.2 数据描述 本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-0 3.分析方法及原理 3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高 描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。 在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。 3.2 通过聚类分析方法,判断哪些地区平均工资水平较高 聚类分析是依据研究对象的个体特征,对其进行分类的方法,分类在经济、管理、社会学、医学等领域,都有广泛的应用。聚类分析能够将一批样本(或变量)数据根据其诸多特征,按照在性质上的亲疏程度在没有先验知识的情况下进行自动分类,产生多个分类结果。类内部个体特征之间具有相似性,不同类间个体特征的差异性较大。 在本案例中,我们将采用两种方法进行聚类分析:一种是系统聚类法,另一种是K-均值法(快速聚类法)。 3.2.1系统聚类法 系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。重复这一过程,直到将所有的样本(或指标)合并为一类。 系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。 在本例中进行的是Q型聚类。 类与类之间距离的计算方法主要有以下几种: (1)最短距离法(Nearest Neighbor),是指两类之间每个个体距离的最小值; (2)最长距离法(Farthest Neighbor),是指两类之间每个个体距离的最大值; (3)组间联接法(Between-groups Linkage),是指两类之间个体之间距离的平均值;
聚类分析方法应用举例
刘向民物流工程 S11085240007 聚类分析方法应用举例 多元统计,就是研究多个随机变量之间相互依赖关系以及内在统计规律性的一门统计学科。多元统计所包括的内容很多、但在实际统计分析中,聚类分析就是应用最广泛的方法之一。聚类分析(cluste:Analysis),就是研究分类问题的一种多元统计分析方法社会经济统计的分类问题,过去在传统方法上,主要就是结合一定的专业知识进行定性分类处理。由于定性分类主要就是靠经验完成,因而其结论难免带有较多的主观性与随意性,故不能很好地揭示客观事物内在的本质差别与联系。而聚类分析能带来定量上的分析可以解决这个问题,下面通过一些实例来描述聚类分析方法在应用上的体现; 1 基于聚类分析的安徽省物流需求研究 选取了分行业统计的年产值类指标构建物流需求指标体系(X组),具体指标包括:农业总产值(万元)(X1)、工业总产值(亿元)(X2)、建筑业总产值(万元)(X3)、社会消费零售总额(万元)(X4)、亿元商品市场成交额(万元)(X5)、进出口总额(万美元)(X6)。该指标体系通过农业、工业、建筑业、批发业、零售业及国际贸易的发生额较全面地反映了地区的物流需求情况。 2 研究方法 分类问题一般的解决法就是聚类分析或者因子分析基础上的聚类分析。由于本文最终期望得安徽省地级市物流需求分类情况,无需了解各个指标体系的内在系统结构,故选择聚类分析方法更简明。进行聚类分析时,本文采用的就是基于样本聚类的Q型系统聚类方法。 3研究过程与结果 3、1地区物流需求指标的聚类分析 由分析软件输出的聚类过程统计量如表1所示。可以瞧出,伪F统计量在归为4类及7类时较大,说明归为4类及7类时较好;伪T2统计量在1类、2类、3类时较大,由于伪T2大说明
聚类分析课堂例题
聚类分析课堂例题 为了研究世界各国森林、草原资源的分布规律,共抽取了21个国家的数据,每个国家4项指标,原始数据见下表1。使用该原始数据对国别进行聚类分析。 表1 抽样数据表
Matlab 解答 Matlab提供了两种方法进行聚类分析。 一种是利用clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用linkage函数定义变量之间的连接;(3)用cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。1.Matlab中相关函数介绍 1.1 pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算X 数据矩阵中对象之间的距离。’X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2 squareform函数 调用格式:Z=squareform(Y,..) 说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3 linkage函数
聚类分析案例
SPSS软件操作实例——某移动公司客户细分模型 数据准备:数据来源于telco.sav,如图1所示,Customer_ID表示客户编号,Peak_mins表示工作日上班时期电话时长,OffPeak_mins表示工作日下班时期电话时长等。 图1 telco.sav数据 分析目的:对移动手机用户进行细分,了解不同用户群体的消费习惯,以更好的对其进行定制性的业务推销,所以需要运用聚类分析。 操作步骤: 1,从菜单中选择【文件】——【打开】——【数据】,在打开数据窗口中选择数据位置以及文件类型,将数据telco.sav导入SPSS软件中,如图2所示。 图2 打开数据菜单选项 2,从菜单中选择【分析】——【描述统计】——【描述】,然后在描述性窗口中,将需要标准化的变量选到右边的“变量列表”,勾选“将标准化得分另存为变量”,点确定,如图3所示。
图3 数据标准化 3,从菜单中选择【分析】——【分类】——【K-均值聚类】,在K-均值聚类分析窗口中将标准化之后的结果选入右边“变量列表”,客户编号选入“个案标记依据”,聚类数改为5。点击迭代按钮,在迭代窗口将最大迭代次数改为100,点击继续。点击保存按钮,在保存窗口勾选“聚类成员”、“与聚类中心的距离”,点击继续。点击选项按钮,在选项窗口勾选“ANOV A表”、“每个个案的聚类信息”,点击继续。点击确定按钮,运行聚类分析,如图4所示。 图4 聚类分析操作
由最终聚类中心表可得最终分成的5个类它们各自的均值。 第一类:依据总通话时间长,上班通话时间长,国际通话时间长等特征,将第一类命名为高端商用客户。 第二类:依据其在各项指标中均较低,将第二类命名为不常使用客户。 第三类:依据总通话和上班通话时间居中等特征,将第三类命名为中端商用客户。第四类:依据下班通话时间最长等特征,将第四类命名为日常客户。 第五类:依据平均每次通话时间最长等特征,将第五类命名为长聊客户。 由ANOVA表可根据F值大小近似得到哪些变量对聚类有贡献,本例题中重要程度排序为:总通话时长>工作日上班时期电话时长>工作日下班时期电话时
聚类分析实例分析题
聚类分析实例分析题 WTD standardization office【WTD 5AB- WTDK 08- WTD 2C】
酿酒葡萄的等级划分葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 表5:葡萄酒等级表 在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[,]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。 表6:细化后的葡萄酒等级表 通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7): 表7:各支葡萄酒的等级
经过整理,我们初步得到了对于葡萄酒的质量的分类的表格。 考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。 在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward最小方差法,又叫做离差平方和法。 聚类分析是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。为了将样品进行分类,就需要研究样品之间关系。这里的最小方差法的基本思想就是将一个样品看作P维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。面对现在的问题,我们不知道元素的分
应用多元统计分析习题解答聚类分析
应用多元统计分析习题 解答聚类分析 TPMK standardization office【 TPMK5AB- TPMK08- TPMK2C- TPMK18】
第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()( )p q q ij ik jk k d q X X ==-∑ q 取不同值,分为
(1)绝对距离(1q =) (2)欧氏距离(2q =) (3)切比雪夫距离(q =∞) (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 (一)夹角余弦 (二)相关系数 5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则? 答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。 (1). 最短距离法 (2)最长距离法 (3)中间距离法 2 2222 121pq kq kp kr D D D D β++=
聚类分析例题及解答
聚类分析作业 例题: country populatn density urban religion lifeexpf lifeexpm literacy pop_incr Afghanistan 20,500 25.0 18 Muslim 44 45 29 2.8 Bangladesh 125,000 800.0 16 Muslim 53 53 35 2.4 Cambodia 10,000 55.0 12 Buddhist 52 50 35 2.9 China 1,205,200 124.0 26 Taoist 69 67 78 1.1 HongKong 5,800 5,494.0 94 Buddhist 80 75 77 -0.1 India 911,600 283.0 26 Hindu 59 58 52 1.9 Indonesia 199,700 102.0 29 Muslim 65 61 77 1.6 Japan 125,500 330.0 77 Buddhist 82 76 99 0.3 Malaysia 19,500 58.0 43 Muslim 72 66 78 2.3 N.Korea 23,100 189.0 60 Buddhist 73 67 99 1.8 Pakistan 128,100 143.0 32 Muslim 58 57 35 2.8 Philippines 69,800 221.0 43 Catholic 68 63 90 1.9 S.Korea 45,000 447.0 72 Protstnt 74 68 96 1.0 Singapore 2,900 4,456.0 100 Taoist 79 73 88 1.2 Taiwan 20,944 582.0 71 Buddhist 78 72 91 0.9 Thailand 59,400 115.0 22 Buddhist 72 65 93 1.4 Vietnam 73,100 218.0 20 Buddhist 68 63 88 1.8 进行聚类分析,步骤如下: 1、标准化的欧式距离聚类 各类所属 得出以上结果,以欧氏距离为计算距离方法,把以上17个亚洲国家地区按6个变量欧氏距离划分为三类。 第一类为:Bangladesh 第二类为:China
聚类分析实例讲解
Lab 6 聚类分析 一、分析背景 Chrysler公司为了赢得市场竞争地位,决定推出新产品Viper,该种产品的目标客户是雅皮士阶层。为了进一步了解这种人群的心理特征,定位自己的产品,吸引目标客户,Chrysler公司进行了一次市场调研。研究者使用九点量表测量400名被试者对30项陈述的态度,从而了解这些目标客户的心理特征。调研还询问被试者对Dodge Viper型汽车的态度来测量标准变量,标准变量的测量通过九点量表来测试消费者对“我愿意购买Chrysler公司生产的Dodge Viper型汽车”的态度。 本次分析的目的是:通过聚类分析,将原始变量分别聚成三类和四类,比较两种方法的效果。同时,比较使用原始变量得到的聚类结果和使用因子得分得到的聚类结果,看哪一种方法能更好地解释数据。 二、分析结果 1、根据原始变量进行的聚类分析 首先根据原始变量进行聚类分析,由于样本数较大,采用迭代聚类法,分别将样本聚为三类和四类,下面是聚类分析的结果比较。 表 1 聚为三类后的组重心表 2 聚为四类后的组重心 表 3 聚为三类的每组样本数表 聚为四类的每组样本数
表5 聚为三类后组重心之间的距离 表 6 聚为四类后组重心之间的距离 由方差分析的结果(结果略)可知,在聚为三类和四类的分析中,V8,V9,V18,V19,V20和V27的组间差异均大于0.05,结果不显著。 2、 根据因子得分进行的聚类分析 以下是根据因子得分,采用迭代法将样本聚为三类和四类的结果: 表7 聚为三类后的组重心 -.45298 .16364 .29950 .36038 -.22794 -.15239 .28739 -.32881 .00765 .25444 .70915 -.87203 .52946 -.29355 -.26021 .18363 .11953 -.28471 .00228 .20936 -.18616 .56772 -.64844 .01414 消费因子 时尚因子 社会因子 爱国因子 期望因子 偏好因子 个性因子 家庭因子 1 2 3 Cluster 表 8 聚为三类时的样本数 137.000 123.000 140.000 400.000 .000 1 2 3 Cluster Valid Missing
聚类分析实例分析题
聚类分析实例分析题 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
酿酒葡萄的等级划分 葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 表5:葡萄酒等级表 动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。
考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。 在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward 最小方差法,又叫做离差平方和法。 聚类分析是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。为了将样品进行分类,就需要研究样品之间关系。这里的最小方差法的基本思想就是将一个样品看作P 维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。面对现在的问题,我们不知道元素的分类,连要分成几类都不知道。现在我们将用SAS 系统里面的stepdisc 和cluster 过程完成判别分析和聚类分析,最终确定元素对象的分类问题。 建立数据阵,具体数学表示为: 式中,行向量1(,...,)i i im X x x =表示第i 个样品; 列向量1(,...,)'j j nj X x x =’,表示第j 项指标。(i=1,2,…,n;j=1,2,…m) 接下来我们将要对数据进行变化,以便于我们比较和消除纲量。在此我们用了使用最广范的方法,ward 最小方差法。其中用到了类间距离来进行比较,定义为: Ward 方法并类时总是使得并类导致的类内离差平方和增量最小。 系统聚类数的确定。在聚类分析中,系统聚类最终得到的一个聚类树,如何确定类的个数,这是一个十分困难但又必须解决的问题;因为分类本身就没有一定标准,人们可以从不同的角度给出不同的分类。在实际应用中常使用下面几种方法确定类的个数。由适当的阀值确定,此处阀值为kl D 。 根据样本的散点图直观的确定。当样本所含指标只有2个或3个时,可运用散点图直观观察。如果指标超过3个时,可用主成份法先综合指标。 根据统计量确定分类个数。在SAS 中,提供了一些来自方差分析思想的统计量近似检验类个数如何选择更合适。 1) 2R 统计量: 其中,2A S 为分类数为k 个数时的总类内离差平方和,2T S 为所有样品或变量的总 离差平方和。2R 越大,说明类内的离差平方和在总离差平方和中比例较小,也就是
spss 聚类分析例题
1.打开数据文件后,在数据编辑窗口中,从菜单栏中选择“分析”—“分类”—“k-均值 聚类”命令。 2.在该对话框中选择变量城市进入“个案标记依据”文本框,作为标签变量。把聚类数标 记为4次。 3.选择变量一至十二月份的日照时数进入“变量”列表框作为观测变量。 4.单击“迭代”按钮,迭代次数为10次,收敛性标准为0. 5.单击“保存”按钮,选择“聚类成员”。 6.单击“选项”按钮,选择“初始聚类中心”和“ANOVA表”,要求输出方差分析表,单 击“继续”。 7.单击“确定”按钮,执行快速聚类分析。 [数据集1] C:\Documents and Settings\Administrator\桌面\ch9\主要城市日照时数.sav 初始聚类中心 聚类 1 2 3 4 一月日照时数89.10 9.00 230.10 121.70 二月日照时数145.40 45.00 215.30 104.40 三月日照时数153.20 49.20 234.20 55.30 四月日照时数258.50 150.50 207.10 83.40 五月日照时数284.00 99.60 196.80 125.00 六月日照时数309.70 99.10 122.60 176.50 七月日照时数320.80 190.90 151.10 155.80 八月日照时数292.80 175.40 151.30 167.10 九月日照时数266.10 80.20 127.10 185.00 十月日照时数223.70 33.00 146.70 246.50 十一月日照时数95.00 38.50 148.70 165.10 十二月日照时数57.30 4.30 173.10 181.60
聚类分析例题
聚类分析例题
聚类分析例题
5.2酿酒葡萄的等级划分 5.2.1葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 等级特优优优良良及格不及格 分数95-100 90-94 80-89 70-79 60-69 0-59 在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[61.6,81.5]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。 等级偏优偏优良良中及格 分数80-84 75-79 70-74 65-69 60-64 数字等级 5 4 3 2 1 通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7): 编号红酒原等级细化等级白酒原等级细化等级1号68.1 2 2 77.9 3 4 2号74 3 3 75.8 3 4 3号74.6 3 4 75.6 3 4 4号71.2 3 3 76.9 3 4 5号72.1 3 3 81.5 4 5 6号66.3 2 2 75.5 3 4 7号65.3 2 2 74.2 3 3 8号66 2 2 72.3 3 3 9号78.2 3 4 80.4 4 5 10号68.8 2 2 79.8 3 4 11号61.6 2 1 71.4 3 3 12号68.3 2 2 72.4 3 3 13号68.8 2 2 73.9 3 3 14号72.6 3 3 77.1 3 4 15号65.7 2 2 78.4 3 4 16号69.9 2 3 67.3 2 2 17号74.5 3 3 80.3 4 5 18号65.4 2 2 76.7 3 4