数据的无量纲化处理及示例

数据的无量纲处理方法及示例
在对实际问题建模过程中,特别是在建立指标评价体系时,常常会面临不同类型的数据处理及融合。而各个指标之间由于计量单位和数量级的不尽相同,从而使得各指标间不具有可比性。在数据分析之前,通常需要先将数据规范化,利用规范化后的数据进行分析。数据规范化处理主要包括同趋化处理和无量纲化处理两个方面。数据的同趋化处理主要解决不同性质的数据问题,对不同性质指标直接累加不能正确反应不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对评价体系的作用力同趋化。数据无量纲化主要解决数据的不可比性,在此处主要介绍几种数据的无量纲化的处理方式。
(1)极值化方法
可以选择如下的三种方式:
(A )'
max min i i i x x
x R
=
=-
即每一个变量除以该变量取值的全距,规范化后的每个变量的取值范围限于[-1,1]。 (B)'
min min
max min i i
i x x x R
--=
=- 即每一个变量与变量最小值之差除以该变量取值的全距,规范化后各变量的取值范围限于[0,1]。
(C) '
max
i
i x x =,即每一个变量值除以该变量取值的最大值,规范化后使变量的最大取值为1。
采用极值化方法对变量数据无量纲化是通过变量取值的最大值和最小值将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级的影响。由于极值化方法对变量无量纲化过程中仅仅对该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。
(2)规范化方法 利用'i i x x
x s
-=
来计算,即每一个变量值与其平均值之差除以该变量的规范差,无量纲化后各变量的平均值为0,规范差为1,从而消除量纲和数量级的影响。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且规范差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异。
(3)均值化方法 计算公式为:'
i
i i
x x x =,该方法在消除量纲和数量级影响的同时,保留了各变量取值差异程度上的信息。
(4)规范差化方法 计算公式为:'i
i x x s
=
。该方法是规范化方法的基础上的一种变形,两者的差别仅在无量纲化后各变量的均值上,规范化方法处理后各变量的均值为0,而规范差化方法处理后各
变量均值为原始变量均值与规范差的比值。
综上所述,针对不同类型的数据,可以选择相应的无量纲化方法。如下的示例就是一个典型的评价体系中无量纲化的范例。
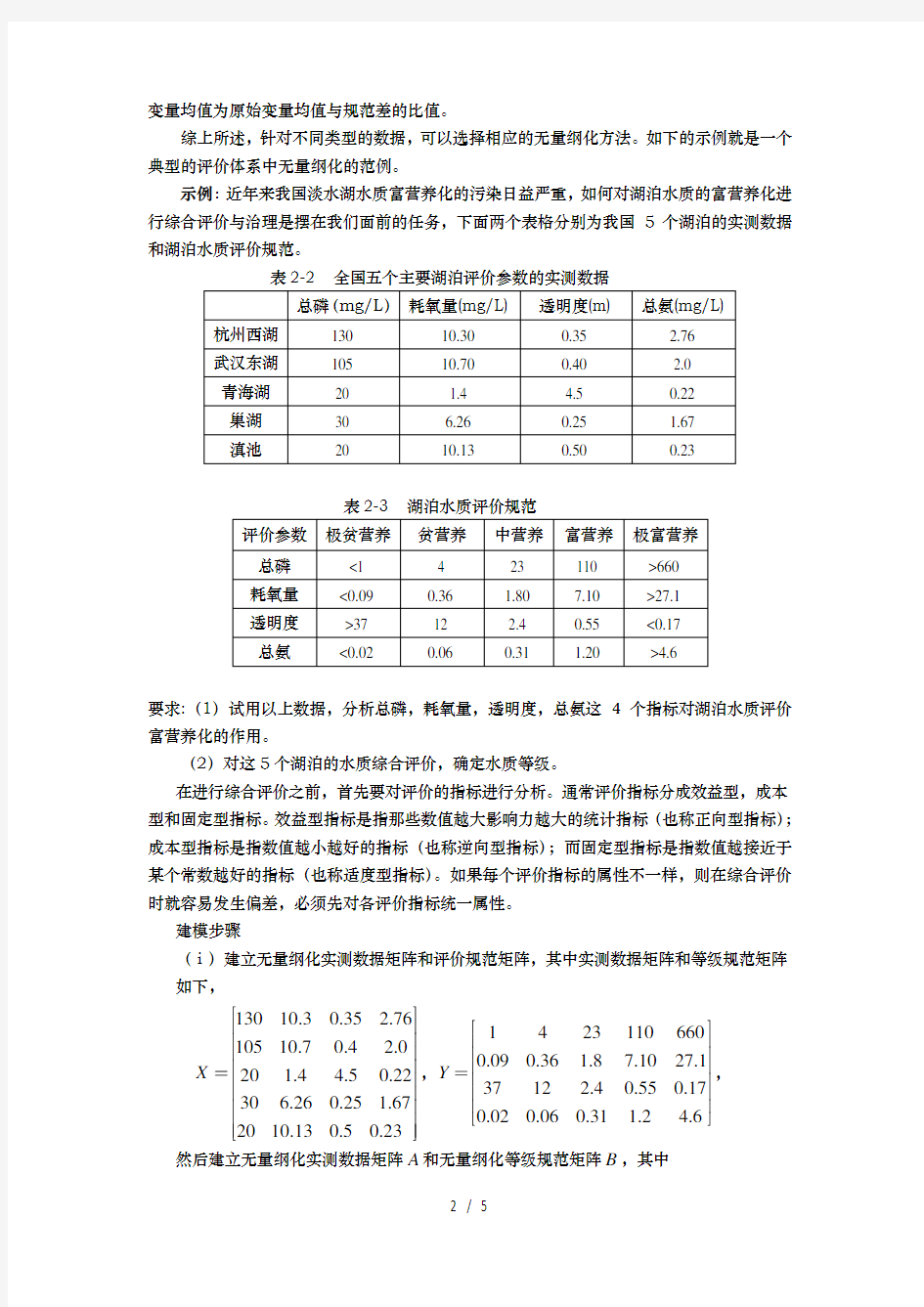
示例:近年来我国淡水湖水质富营养化的污染日益严重,如何对湖泊水质的富营养化进行综合评价与治理是摆在我们面前的任务,下面两个表格分别为我国5个湖泊的实测数据和湖泊水质评价规范。
表2-2 全国五个主要湖泊评价参数的实测数据
表2-3
湖泊水质评价规范
要求:(1)试用以上数据,分析总磷,耗氧量,透明度,总氨这4个指标对湖泊水质评价富营养化的作用。
(2)对这5个湖泊的水质综合评价,确定水质等级。
在进行综合评价之前,首先要对评价的指标进行分析。通常评价指标分成效益型,成本型和固定型指标。效益型指标是指那些数值越大影响力越大的统计指标(也称正向型指标);成本型指标是指数值越小越好的指标(也称逆向型指标);而固定型指标是指数值越接近于某个常数越好的指标(也称适度型指标)。如果每个评价指标的属性不一样,则在综合评价时就容易发生偏差,必须先对各评价指标统一属性。
建模步骤
(ⅰ)建立无量纲化实测数据矩阵和评价规范矩阵,其中实测数据矩阵和等级规范矩阵如下,
130
10.30.35 2.7610510.7
0.4 2.0
20 1.4
4.5
0.2230 6.260.25 1.672010.130.5
0.23
X 轾犏犏犏犏=犏
犏犏犏犏臌
,14231106600.090.36 1.87.1027.13712 2.40.550.170.020.060.31 1.2 4.6Y 轾犏犏犏=犏犏犏臌, 然后建立无量纲化实测数据矩阵A 和无量纲化等级规范矩阵B ,其中
/3
max /3min ij ij j
ij ij ij j
x x j a x x j ì1???=í
?=???/3max /3
min kt kt k
kt kt kt k
y y k b y y k ì1???=í
?=???
得到
1.00000.96260.7143 1.0000
0.8077 1.00000.62500.72460.15380.13080.05560.07970.23080.5850 1.00000.60510.15380.94670.50000.0833A 轾犏犏犏犏=犏犏犏犏犏臌,
0.00150.00610.03480.1667 1.00000.00330.01330.06640.2620 1.00000.00460.01420.07080.3091 1.00000.00430.01300.06740.2609 1.0000B 轾犏犏犏=犏犏犏臌
。
(ⅱ)计算各评价指标的权重
计算矩阵B 的各行向量的均值和规范差,
5
1
1,1,2,3,45i ij i j b s i m ===
=?
然后计算变异系数
/i i i w s m =,
最后对变异系数归一化得到各指标的权重为
[]0.27670.24440.23470.2442w =
(ⅲ)建立各湖泊水质的综合评价模型
通常可以利用向量之间的距离来衡量两个向量之间的接近程度,在Matlab 中,有以下的函数命令来计算向量之间的距离;
dist(,w p ): 计算w 中的每个行向量和p 中每个列向量之间的欧式距离; mandist(,w p ):绝对值距离。
计算A 中各行向量到B 中各列向量之间的欧氏距离,
ij d =
若15
min{}ik ij j d d #=,则第i 个湖泊属于第k 级。
1.8472 1.8312 1.7374 1.37690.28811.5959 1.5798 1.4859 1.12710.50340.2185
0.20450.13670.3383 1.79171.3201 1.3038 1.20820.83920.95911.0793 1.0650
0.9867
0.7328
1.3450
d 轾犏犏犏犏犏=犏犏犏犏犏臌
这说明杭州西湖,武汉东湖都属于极富营养水质,青海湖属于中营养水质,而巢湖和滇池属
于富营养水质。
同时也可以计算A 中各行向量到B 中各列向量之间的绝对值距离
4
1
||ij ik ik i D a b ==
-?
,
若15
min{}ik ij j D D #=,则第i 个湖泊属于第k 级。
3.6631 3.6303 3.4374 2.67830.32313.1436 3.1108 2.9178 2.15870.84270.4062
0.37340.21100.5787 3.58002.4071 2.3743 2.1814 1.4223 1.57911.6701 1.6374
1.4444
1.0660
2.3161
D 轾犏犏犏犏犏=犏犏
犏犏犏臌
其评价结果与利用欧氏距离得到的评价结果完全一样。
所以,从上面的计算可以看出,尽管欧氏距离和绝对值距离的意义完全不一样,但对湖泊水质的评价等级是一样的,这表明了方法的稳定性。
程序:
X=[130 10.3 0.35 2.76。 105 10.7 0.4 2。 20 1.4 4.5 0.22
30 6.26 0.25 1.67 。 20 10.13 0.5 0.23]。
Y=[1 4 23 100 660。 0.09 0.36 1.8 7.1 27.1。 37 12 2.4 0.55 0.17。 0.02 0.06 0.31 1.2 4.6]。 B1=Y(1,:)./660。 B2=Y(2,:)./27.1。 B3=0.17./Y(3,:)。 B4=Y(4,:)./4.6。
B=[B1。B2。B3。B4]。
A1=X(:,1)./130。
A2=X(:,1)./10.7。
A3=0.25./X(:,3)。A4=X(:,4)./2.76。
A=[A1 A2 A3 A4]。B=B’。
t=std(b)./mean(b)。w=t/sum(t)。
jd=dist(A,B)。
mjd=mandist(A,B)
数据的无量纲化处理及示例
数据的无量纲处理方法及示例 在对实际问题建模过程中,特别是在建立指标评价体系时,常常会面临不同类型的数据处理及融合。而各个指标之间由于计量单位和数量级的不尽相同,从而使得各指标间不具有可比性。在数据分析之前,通常需要先将数据规范化,利用规范化后的数据进行分析。数据规范化处理主要包括同趋化处理和无量纲化处理两个方面。数据的同趋化处理主要解决不同性质的数据问题,对不同性质指标直接累加不能正确反应不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对评价体系的作用力同趋化。数据无量纲化主要解决数据的不可比性,在此处主要介绍几种数据的无量纲化的处理方式。 (1)极值化方法 可以选择如下的三种方式: (A )' max min i i i x x x R 即每一个变量除以该变量取值的全距,规范化后的每个变量的取值范围限于[-1,1]。 (B)' min min max min i i i x x x R 即每一个变量与变量最小值之差除以该变量取值的全距,规范化后各变量的取值范围限于[0,1]。 (C) ' max i i x x ,即每一个变量值除以该变量取值的最大值,规范化后使变量的最大取值为1。 采用极值化方法对变量数据无量纲化是通过变量取值的最大值和最小值将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级的影响。由于极值化方法对变量无量纲化过程中仅仅对该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。 (2)规范化方法 利用'i i x x x 来计算,即每一个变量值与其平均值之差除以该变量的规范差,无量 纲化后各变量的平均值为0,规范差为1,从而消除量纲和数量级的影响。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且规范差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异。
数据标准化处理方法
数据标准化处理方法 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA 分别为属性A的最小值和最大值,将A的一个原始值x通过min-max 标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理: zij=(xij-xi)/si 其中:zij为标准化后的变量值;xij为实际变量值。 3.将逆指标前的正负号对调。 标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。 三、Decimal scaling小数定标标准化
数据标准化处理
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化 这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理: zij=(xij-xi)/si 其中:zij为标准化后的变量值;xij为实际变量值。 3.将逆指标前的正负号对调。 标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。 三、Decimal scaling小数定标标准化 这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性A
数据标准化的原因和方法
数据标准化的原因和方法 一、为何要将数据标准化? 由于不同变量常常具有不同的单位和不同的变异程度。不同的单位常使系数的实践解释发生困难。例如:第1个变量的单位是kg,第2个变量的单位是cm,那么在计算绝对距离时将出现将两个事例中第1个变量观察值之差的绝对值(单位是kg)与第2个变量观察值之差的绝对值(单位是cm )相加的情况。使用者会说5kg的差异怎么可以与3cm的差异相加?不同变量自身具有相差较大的变异时,会使在计算出的关系系数中,不同变量所占的比重大不相同。例如如果第1个变量(两水稻品种米粒中的脂肪含量)的数值在 2%到4%之间,而第2个变量(两水稻品种的亩产量)的数值范围都在1000与5000之间。为了消除量纲影响和变量自身变异大小和数值大小的影响,故将数据标准化。 二、数据标准化的方法: 1、对变量的离差标准化 离差标准化是将某变量中的观察值减去该变量的最小值,然后除以该变量的极差。即 x’ =[x ik-Min (x k)]/R k ik 经过离差标准化后,各种变量的观察值的数值范围都将在〔0,1〕之间,并且经标准化的数据都是没有单位的纯数量。离差标准化是消除量纲(单位)影响和变异大小因素的影响的最简单的方法。有一些关系系数(例如绝对值指数尺度)在定义时就已经要求对数据进行离差标准化,但有些关系系数的计算公式却没有这样要求,当选用这类关系系数前,不妨先对数据进行标准化,看看分析的结果是否为有意义的变化。 2,对变量的标准差标准化 标准差标准化是将某变量中的观察值减去该变量的平均数,然后除以该变量的标准差。即 x’ = (x ik- )/s k ik 经过标准差标准化后,各变量将有约一半观察值的数值小于0,另一半观察值的数值大于0,变量的平均数为0,标准差为1。经标准化的数据都是没有单位的纯数量。对变量进行的标准差标准化可以消除量纲(单位)影响和变量自身变异的影响。但有人认为经过这种标准化后,原来数值较大的的观察值对分类结果的影响仍然占明显的优势,应该进一步消除大小因子的影响。尽管如此,它还是当前用得最多的数据标准化方法。
数据标准化.归一化处理
数据的标准化 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”
和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化 这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。步骤如下: 求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; .进行标准化处理:zij=(xij-xi)/si,其中:zij为标准化后的变量值;xij为实际变量值。 将逆指标前的正负号对调。标准化后的变量值围绕0上下波动,
数据的标准化
数据的标准化 数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上,常见的数据归一化的方法有:min-max标准化(Min-max normalization)也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:其中max为样本数据的最大值,min为样本数据的最小值。这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。log函数转换通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:看了下网上很多介绍都是x*=log10(x),其实是有问题的,这个结果并非一定落到[0,1]区间上,应该还要除以log10(max),max为样本数据最大值,并且所有的数据都要大于等于1。atan 函数转换用反正切函数也可以实现数据的归一化:使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。而并非所有数据标准化的结果都映射到[0,1]区间上,其中最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法:z-score 标准化(zero-mean normalization)也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:其中μ为所有样本数据的均值,σ为所有样本数据的标准差。 z-score 标准化 用zscore,标准化的目的是:使得平均值为0,标准差为1,这样可以使不同量纲的数据放在一个矩阵. >> A=magic(4) A = 16 2 3 13 5 11 10 8 9 7 6 12 4 14 1 5 1 >> [Z,MU,SIGMA] = zscore(A) Z = 1.3770 -1.2509 -1.0585 0.8262 -0.6426 0.4811 0.2887 -0.0918
数据的无量纲化处理及示例
数据得无量纲处理方法及示例 在对实际问题建模过程中,特别就是在建立指标评价体系时,常常会面临不同类型得数据处理及融合。而各个指标之间由于计量单位与数量级得不尽相同,从而使得各指标间不具有可比性。在数据分析之前,通常需要先将数据规范化,利用规范化后得数据进行分析.数据规范化处理主要包括同趋化处理与无量纲化处理两个方面.数据得同趋化处理主要解决不同性质得数据问题,对不同性质指标直接累加不能正确反应不同作用力得综合结果,须先考虑改变逆指标数据性质,使所有指标对评价体系得作用力同趋化。数据无量纲化主要解决数据得不可比性,在此处主要介绍几种数据得无量纲化得处理方式。 (1)极值化方法 可以选择如下得三种方式: (A) 即每一个变量除以该变量取值得全距,规范化后得每个变量得取值范围限于[-1,1]。 (B) 即每一个变量与变量最小值之差除以该变量取值得全距,规范化后各变量得取值范围限于[0,1]。 (C),即每一个变量值除以该变量取值得最大值,规范化后使变量得最大取值为1。 采用极值化方法对变量数据无量纲化就是通过变量取值得最大值与最小值将原始数据转换为界于某一特定范围得数据,从而消除量纲与数量级得影响。由于极值化方法对变量无量纲化过程中仅仅对该变量得最大值与最小值这两个极端值有关,而与其她取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。 (2)规范化方法 利用来计算,即每一个变量值与其平均值之差除以该变量得规范差,无量纲化后各变量得平均值为0,规范差为1,从而消除量纲与数量级得影响.虽然该方法在无量纲化过程中利用了所有得数据信息,但就是该方法在无量纲化后不仅使得转换后得各变量均值相同,且规范差也相同,即无量纲化得同时还消除了各变量在变异程度上得差异. (3)均值化方法 计算公式为:,该方法在消除量纲与数量级影响得同时,保留了各变量取值差异程度上得信息。 (4)规范差化方法 计算公式为:。该方法就是规范化方法得基础上得一种变形,两者得差别仅在无量纲化后各变量得均值上,规范化方法处理后各变量得均值为0,而规范差化方法处理后各变量均值为原始变量均值与规范差得比值。 综上所述,针对不同类型得数据,可以选择相应得无量纲化方法。如下得示例就就是一个典型得评价体系中无量纲化得范例. 示例:近年来我国淡水湖水质富营养化得污染日益严重,如何对湖泊水质得富营养化进行综合评价与治理就是摆在我们面前得任务,下面两个表格分别为我国5个湖泊得实测数据与湖泊水质评价规范。 表2-2全国五个主要湖泊评价参数得实测数据
评价指标的无量纲化处理
评价指标的无量纲化处理 在多指标综合评价中涉及到两个基本变量:一是各评价指标的实际值,另一个是各指标的评价值。由于各指标所代表的物理涵义不同,因此存在着量纲上的差异。这种异量纲性是影响对事物整体评价的主要因素。指标的无量纲化处理是解决这一问题的主要手段。无量纲化,也称作数据的标准化、规格化,是一种通过数学变换来消除原始变量量纲影响的方法。 (1)直线型无量纲化方法 基本思想是假定实际指标和评价指标之间存在着线性关系,实际指标的变化将引起评价指标一个相应的比例变化。代表方法有:阈值法、标准化法(Z-score 法)、比重法等等。 a. 阈值法 阈值也称临界值,是衡量事物发展变化的一些特殊指标值,比如极大值、极小值、满意值、不允许值等。阈值法是用指标实际值与阈值相比以得到指标评价值的无量纲化方法。常用算法公式有: n i i i i x x y ≤≤=1max (2.24) n i i i n i i n i i i x x x x y ≤≤≤≤≤≤-+=111max min max (2.25) n i i n i i i n i i i x x x x y ≤≤≤≤≤≤--=111min max max (2.26) n i i n i i n i i i i x x x x y ≤≤≤≤≤≤--=111min max max (2.27) q k x x x x y n i i n i i n i i i i +--=≤≤≤≤≤≤111min max max (2.28) b 标准化法 统计学原理告诉我们,要对多组不同量纲数据进行比较,可以先将它 们标准化转化成无量纲的标准化数据。而综合评价就是要将多组不同的数 据进行综合,因而可以借助于标准化方法来消除数据量纲的影响。标准化 (Z-score )公式为:
数据标准化的几种方法
数据标准化的几种方法 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。在SPSS中依次点击Analyze Descriptive Descriptive 点击Save standardized values as varianles即可。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理: zij=(xij-xi)/si 其中:zij为标准化后的变量值;xij为实际变量值。 3.将逆指标前的正负号对调。 标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。 三、Decimal scaling小数定标标准化
数据标准化的原因及方法
数据标准化的原因及方法 (2011-01-21 20:43:34) 转载▼ 标签: 杂谈 一、为何要将数据标准化? 由于不同变量常常具有不同的单位和不同的变异程度。不同的单位常使系数的实践解释发生困难。例如:第1个变量的单位是kg,第2个变量的单位是cm,那么在计算绝对距离时将出现将两个事例中第1个变量观察值之差的绝对值(单位是kg)与第2个变量观察值之差的绝对值(单位是cm )相加的情况。使用者会说5kg的差异怎么可以与3cm的差异相加?不同变量自身具有相差较大的变异时,会使在计算出的关系系数中,不同变量所占的比重大不相同。例如如果第1个变量(两水稻品种米粒中的脂肪含量)的数值在2%到4%之间,而第2个变量(两水稻品种的亩产量)的数值范围都在1000与5000之间。为了消除量纲影响和变量自身变异大小和数值大小的影响,故将数据标准化。 二、数据标准化的方法: 1、对变量的离差标准化 离差标准化是将某变量中的观察值减去该变量的最小值,然后除以该变量的极差。即x’ik=[x ik-Min (x k)]/R k 经过离差标准化后,各种变量的观察值的数值范围都将在〔0,1〕之间,并且经标准化的数据都是没有单位的纯数量。离差标准化是消除量纲(单位)影响和变异大小因素的影响的最简单的方法。有一些关系系数(例如绝对值指数尺度)在定义时就已经要求对数据进行离差标准化,但有些关系系数的计算公式却没有这样要求,当选用这类关系系数前,不妨先对数据进行标准化,看看分析的结果是否为有意义的变化。 2,对变量的标准差标准化 标准差标准化是将某变量中的观察值减去该变量的平均数,然后除以该变量的标准差。即 x’ik=(x ik-)/s k 经过标准差标准化后,各变量将有约一半观察值的数值小于0,另一半观察值的数值大于0,变量的平均数为0,标准差为1。经标准化的数据都是没有单位的纯数量。对变量进行的标准差标准化可以消除量纲(单位)影响和变量自身变异的影响。但有人认为经过这种标准化后,原来数值较大的的观察值对分类结果的影响仍然占明显的优势,应该进一步消除大小因子的影响。尽管如此,它还是当前用得最多的数据标准化方法。 3,先对事例进行标准差标准化,再对变量进行标准差标准化 第一步,先对事例进行标准差标准化,即将某事例中的观察值减去该事例的平均数,然后除以该事例的标准差。即 x’ik=(x ik-)/s i 第二步,再对变量进行标准差标准化,即将某变量中的观察值减去该变量的平均数,然后除以该变量的标准差。即
数据的标准化处理及实际应用
数据的标准化处理及实际应用 数据标准化处理是数据挖掘一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标即处于同一数量级,适合进行综合对比评价。 极差法 极差法是对原始数据的线性变换,首先计算指标值得最小值、 最大值,计算 极差,通过极差法将指标值映射到[0-1]之间。公式为: 新数据=(原数据-极小值)/ (极大值-极小值) t ;r ? min 需= ~ max — frun Z-score 标准化法 SPSS默认的数据标准化方法即是Z得分法,这种方法基于原始数据的均值 (mean和标准差(standard deviation )进行数据的标准化。经过处理的数 据符合标准正态分布,即均值为0,标准差为1。公式为: 其中卩为所有样本数据的均值,c为所有样本数据的标准差。 数据标准化的另外一个实用之处 在实际应用中,数据标准化不只是用于指标的可比性处理,还有一些非常实用的用处,利用标准化方法将指标归到最适于我们观测的范围,更加直观。且看案例:有一组数据,是学生参加某次社会公益活动的数据,其中有一指标为:在校综合评价指数,反映学生在校综合表现水平。
可以看出这个指标的范围为[0-140],但这个范围不太符合我们在学校里的习惯,在学校里经常用[0-100]的百分制,60分以上基本认可为及格,现在这个范围不能直观的反映学生在校表现水平。此时,极差法是一个非常好的选择,我 们可以将[0-140]数值,映射到[0-100],便于直观对比学生的表现。 公式为:(原数据-极小值)/ (极大值-极小值)*100 我们再来看看结果:
数据标准化处理方法
数据标准化处理方法 在数据分析之前,通常需要先将数据标准化(normalization),再利用标准化后的数据进行分析。数据标准化处理主要包括同趋化处理和无量纲化处理两个方面。 同趋化处理主要解决数据不同性质的问题,对不同性质指标直接运算,不能正确反映不同作用的综合结果,须先考虑改变各指标数据性质,使所有指标对测评方案的作用同趋化,再运算,才能得出正确结果。 无量纲化处理主要解决数据可比性的问题,方法有很多种,常用的有“Min-Max标准化”、“z-score标准化”和“小数定标标准化”等三种。原始数据转换为无量纲化指标后,各指标值处于同一个数量级上,方便进行综合测评分析。 一、Min-Max 标准化 Min-Max标准化方法是对原始数据进行线性变换。设Min和Max 分别为指标A的最小值和最大值,将A的一个原始值x通过Min-Max 标准化映射成在区间[0,1]中的值x',其公式为: x'=(x-Min)/(Max-Min) 即:新数据=(原数据-最小值)/(最大值-最小值) 二、z-score 标准化 z-score标准化方法基于原始数据的均值(mean)和标准差(standard deviation)。 将A的原始值x使用z-score标准化到x'的公式为:
x'=(x-Mean)/Std 即:新数据=(原数据-均值)/标准差 z-score标准化方法适用于指标A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 三、小数定标(Decimal scaling)标准化 Decimal scaling标准化方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于指标A的取值中的最大绝对值。将指标A的原始值x使用decimal scaling标准化到x'的计算方法是: x'=x/(10*j) 即:新数据=原数据/(10*j) 其中,j是使x'的绝对值小于1的最小整数,*指幂指数运算。 例如假定A的值由-986到917,A的最大绝对值为986,为使用小数定标标准化,我们用1000(即j=3)除以每个值,这样-986被规范化为-0.986。 最后,标准化会对原始数据做出改变,需要保存所使用标准化方法的参数,以便对后续的数据进行统一的标准化处理。
数据标准化方法
数据标准化方法 问题1:将一个人的体重和身高相加在一起有无什么意义? 答:量纲(就是单位)不同的量相加是没有意义的。不加处理就将两个不同量纲的量相加这是数学建模的大忌! 问题2:如何将一个人的体重G 和身高H 这两个指标综合为一个指标用以评价一个人身材? 答:通常考虑加法模型和乘法模型。乘法模型在这里不太适合,故考虑加法模型,一般采用加权组合的方式,即12P w G w H =+,这里121w w +=,但是这样就犯了一个严重的错误。 因此需要先对,G H 进行预处理→无量纲化,也就是数据标准化方法。 数据标准化方法主要有以下三种: (1)规范化方法 对序列12,,...,n x x x 进行变换: 111m in{} m ax{}m in{} i j j n i j j j n j n x x y x x ≤≤≤≤≤≤-= - 则新序列12,,...,[0,1]n y y y ∈且无量纲。一般的数据需要时都可以考虑先进行规范化处理。 (2)正规化方法 对序列12,,...,n x x x 进行变换: i i x x y s -= ,这里1 1 n i i x x n == ∑ ,s = 则新序列12,,...,n y y y 的均值为0,而方差为1,且无量纲。 (3)归一化方法 对正项序列12,,...,n x x x 进行变换: 1 i i n i i x y x == ∑ 则新序列12,,...,[0,1]n y y y ∈且无量纲,并且显然有1 1n i i y ==∑。 归一化方法在确定权重时经常用到。 针对实际情况,也可能有其他一些量化方法,或者要综合使用多种方法,总之最后的结果都是无量纲化。
数据的无量纲化处理
常用的数据无量纲化处理方法,主要包括如下几种: (1)总和标准化。分别求出各聚类要素所对应的数据的总和,以各要素的数据除以该要素的数据的总和,即 ),,2,1;,,2,1(1n j m i x x x m i ij ij ij ==='∑= (2.4.1) 经过总和标准化处理后所得到的新数据ij x ',满足 ∑==='m i ij n j x 1),,2,1(1 (2)标准差标准化,即 ),,2,1;,,2,1(n j m i s x x x j j ij ij ==-=' (2.4.2) 式中: ∑==m i ij j x m x 1 1 ∑=-=m i j ij j x x m s 1 2)(1 经过标准差标准化处理后所得到的新数据ij x ',各要素(指标)的平均值为0, 标准差为1,即有: 011 ='=∑=m i ij j x m x ∑=='-'=m i j ij j x x m s 1 21)(1 (3)极大值标准化,即 ),,2,1;,,2,1(}{m a x n j m i x x x ij i ij ij ===' (2.4.3) 经过极大值标准化处理后所得的新数据ij x ',各要素(指标)的极大值为1,其余各数值小于1。 (4)极差的标准化,即
{} {}{}),,2,1;,,2,1(m i n m a x m i n n j m i x x x x x ij i ij i ij i ij ij ==--= (2.4.4) 经过极差标准化处理后所得的新数据ij x ',各要素(指标)的极大值为1,极小值为0,其余的数值均在0与1之间。
数据标准化的几种方法
数据标准化的几种方法 数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。 其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上,常见的数据归一化的方法有: min-max标准化(Min-max normalization) 也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下: 其中max为样本数据的最大值,min为样本数据的最小值。这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。 log函数转换 通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下: 看了下网上很多介绍都是x*=log10(x),其实是有问题的,这个结果并非一定落到[0,1]区间上,应该还要除以log10(max),max为样本数据最大值,并且所有的数据都要大于等于1。 atan函数转换 用反正切函数也可以实现数据的归一化: 使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。
而并非所有数据标准化的结果都映射到[0,1]区间上,其中最常见的标准化方法就是Z 标准化,也是SPSS中最为常用的标准化方法: z-score 标准化(zero-mean normalization) 也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为: 其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
数据标准化的几种方法
数据标准化的几种方法 TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】
数据标准化的几种方法 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。在SPSS中依次点击Analyze Descriptive Descriptive 点击Save standardized values as varianles即可。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理: zij=(xij-xi)/si 其中:zij为标准化后的变量值;xij为实际变量值。 3.将逆指标前的正负号对调。
数据标准化处理方法
数据标准化处理方法 Company number:【WTUT-WT88Y-W8BBGB-BWYTT-19998】
数据标准化处理方法 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理: zij=(xij-xi)/si 其中:zij为标准化后的变量值;xij为实际变量值。 3.将逆指标前的正负号对调。 标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
(完整版)2.3数据的无量纲化处理及示例(可编辑修改word版)
i i i i i i 数据的无量纲处理方法及示例 在对实际问题建模过程中,特别是在建立指标评价体系时,常常会面临不同类型的数据处理及融合。而各个指标之间由于计量单位和数量级的不尽相同,从而使得各指标间不具有可比性。在数据分析之前,通常需要先将数据标准化,利用标准化后的数据进行分析。数据标准化处理主要包括同趋化处理和无量纲化处理两个方面。数据的同趋化处理主要解决不同性质的数据问题,对不同性质指标直接累加不能正确反应不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对评价体系的作用力同趋化。数据无量纲化主要解决数据的不可比性,在此处主要介绍几种数据的无量纲化的处理方式。 (1) 极值化方法 可以选择如下的三种方式: (A ) x ' = x i max - = x i min R 即每一个变量除以该变量取值的全距,标准化后的每个变量的取值范围限于[-1,1]。 (B) x ' = xi - max - min = min x i - min R 即每一个变量与变量最小值之差除以该变量取值的全距,标准化后各变量的取值范围限于[0,1]。 (C) 值为 1。 x ' = x i max ,即每一个变量值除以该变量取值的最大值,标准化后使变量的最大取 采用极值化方法对变量数据无量纲化是通过变量取值的最大值和最小值将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级的影响。由于极值化方法对变量无量纲化过程中仅仅对该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。 (2) 标准化方法 利用 x ' = x i - s x 来计算,即每一个变量值与其平均值之差除以该变量的标准差,无量 纲化后各变量的平均值为 0,标准差为 1,从而消除量纲和数量级的影响。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且标准差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异。 (3) 均值化方法 计算公式为: x ' = 异程度上的信息。 x i ,该方法在消除量纲和数量级影响的同时,保留了各变量取值差 x i (4) 标准差化方法 计算公式为: x ' = x i 。该方法是标准化方法的基础上的一种变形,两者的差别仅在无 s 量纲化后各变量的均值上,标准化方法处理后各变量的均值为 0,而标准差化方法处理后各