计量经济学1—

第二章课后习题
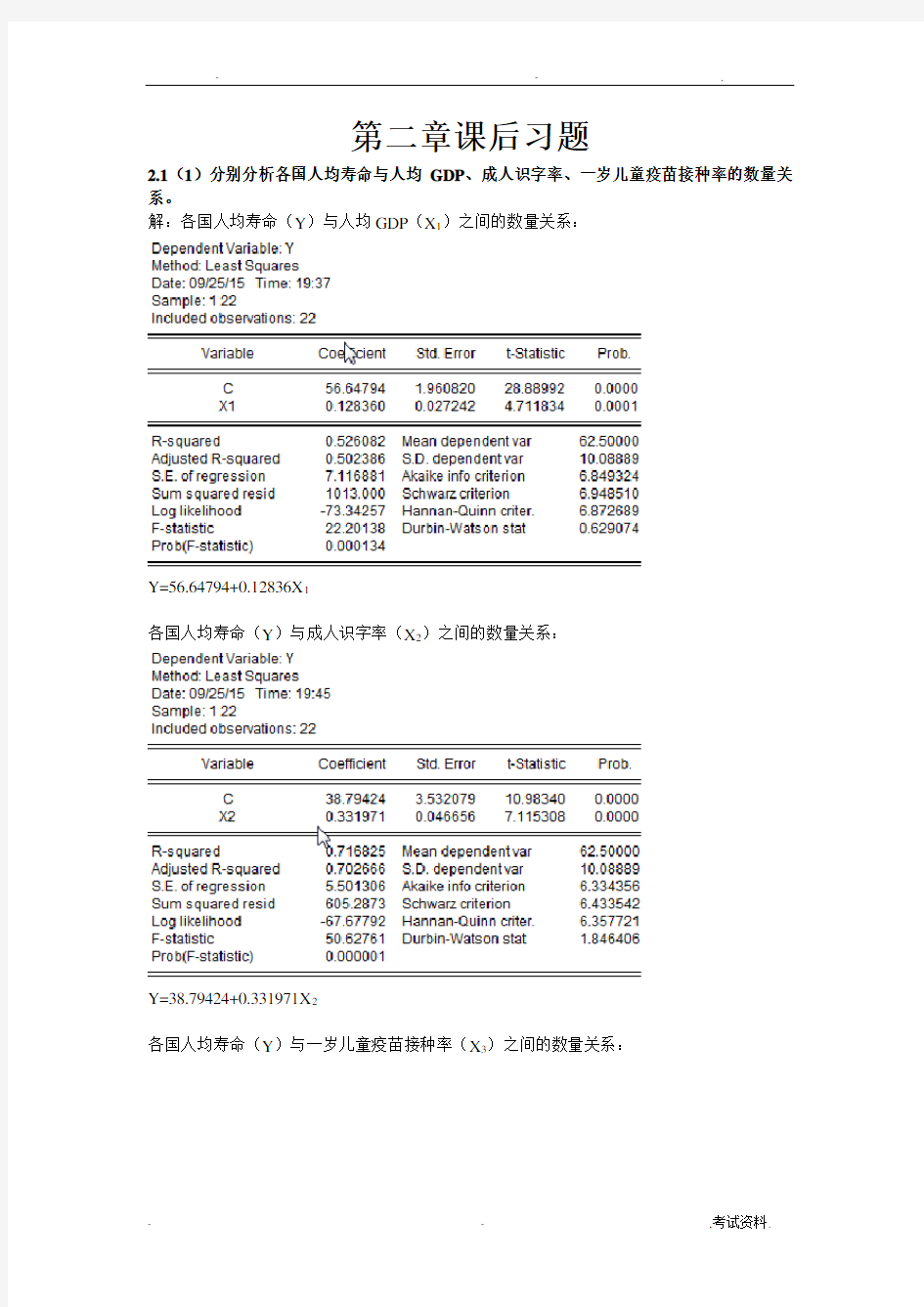
2.1(1)分别分析各国人均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的数量关系。
解:各国人均寿命(Y)与人均GDP(X1)之间的数量关系:
Y=56.64794+0.12836X1
各国人均寿命(Y)与成人识字率(X2)之间的数量关系:
Y=38.79424+0.331971X2
各国人均寿命(Y)与一岁儿童疫苗接种率(X3)之间的数量关系:
Y=31.79956+0.387276X3
(2)对所建立的回归模型近性检验(假设显著性水平α为0.05)。
解:各国人均寿命(Y)与人均GDP(X1)之间的回归模型检验:
1﹥经济意义检验:所估计的参数β1=56.64794,β2=0.12836,说明亚洲各国人均GDP每增加1美元,人均寿命将增加0.12836年,这与预期的经济意义相符。
2﹥拟合有度检验:可决系数R2=0.526082,说明所建模型整体上对样本数据拟合较好,即解释变量“人均GDP”对被解释变量“人均寿命”的一半多作出了解释。
3﹥统计检验:H0:β2=0,H1:β2≠0,因为P=0.0001<α=0.05,所以拒绝原假设,因此亚洲各国人均GDP对人均寿命具有显著影响。
各国人均寿命(Y)与成人识字率(X2)之间的回归模型检验:
1﹥经济意义检验:所估计的参数β1=38.79424,β2=0.331971,说明亚洲各国成人识字率每增加1%,人均寿命将增加0.331971年,这与预期的经济意义相符。
2﹥拟合优度检验:可决系数R2=0.716825,说明所建模型整体上对样本数据拟合较好,即解释变量“成人识字率”对被解释变量“人均寿命”的大部分作出了解释。
3﹥统计检验:H0:β2=0,H1:β2≠0,因为P=0.0000<α=0.05,所以拒绝原假设,因此亚洲各国成人识字率对人均寿命具有显著影响。
各国人均寿命(Y)与一岁儿童疫苗接种率(X3)之间的回归模型检验:
1﹥经济意义检验:所估计的参数β1=31.79956,β2=0.387276,说明亚洲各国一岁儿童疫苗接种率每增加1%,人均寿命将增加0.387276年,这与预期的经济意义相符。
2﹥拟合优度检验:可决系数R2=0.537929,说明所建模型整体上对样本数据拟合较好,即解释变量“一岁儿童疫苗接种率”对被解释变量“人均寿命”的一半多作出了解释。
3﹥统计检验:H0:β2=0,H1:β2≠0,因为P=0.0001<α=0.05,所以拒绝原假设,因此亚洲各国一岁儿童疫苗接种率对人均寿命具有显著影响。
2.2(1)建立浙江省财政预算收入与全省生产总值的计量经济模型,估计模型的参数,检验模型的显著性,用规范的形式写出估计检验结果,并解释所估计参数的经济意义(假设显著性水平为0.05)。
解:
计量经济模型:Y=﹣154.3063+0.176124X
估计模型的参数:β1=﹣154.3063,β2=0.176124
统计检验:H0:β2=0,H1:β2≠0,因为P=0.0000<α=0.05,所以拒绝原假设,因此全省生产总值对财政预算总收入具有显著影响。
所估计参数的经济意义:所估计的参数β1=﹣154.3063,β2=0.176124,说明全省生产总值每增加1亿元,财政预算总收入将增加0.176124亿元。
(2)如果2011年,全省生产总值为32000亿元,比上年增长9.0%,利用计量经济模型对浙江省2011年的财政预算总收入做出点预测和区间预测。
解:由EViews软件得出Y f=5481.659,这是当X f=32000时浙江省财政预算总收入的点预测值。
1>为了作区间预测,取α=0.05,Y f平均值置信度95%的预测区间为:
根据下图的数据可以计算出:
当X f=32000时,将相关数据代入计算得到
即是说,当浙江省全省生产总值达到32000亿元时,浙江省财政预算总收入平均值置信度95%的预测区间为(5256.972,5706.346)亿元。
2>Y f个别值置信度95%的预测区间为:
当X f=32000时,将相关数据代入计算得到
即是说,当浙江省全省生产总值达到32000亿元时,浙江省财政预算总收入个别值置信度95%的预测区间为(5039.510,5923.808)亿元。
(3)建立浙江省财政预算收入对数与全省生产总值对数的计量经济模型,估计模型的参数,检验模型的显著性,并解释所估计参数的经济意义。
解:
计量经济模型:lnY=﹣1.918289+0.980275lnX
估计模型的参数:β1=﹣1.918289,β2=0.980275
统计检验:H0:β2=0,H1:β2≠0,因为P=0.0000<α=0.05,所以拒绝原假设,因此全省生产总值对数对财政预算总收入对数具有显著影响。
所估计参数的经济意义:所估计的参数β1=﹣1.918289,β2=0.980275,说明全省生产总值对数每增加1亿元,财政预算总收入对数将增加0.980275亿元。
2.3由12对观测值估计得消费消费函数C i=50+0.6Y,其中,C是消费支出,Y是可支配收入(元),已知Y=800,(Y i-Y)2=8000, e =300,t0.025(10)=2.23。当Y f=1000时,试计算:
(1)消费支出C的点预测值;
解:因为Y f=1000,C i=50+0.6Y,所以消费支出C的点预测值是650
(2)在95%的置信概率下消费支出C平均值的预测区间;
解:
即是说,当可支配收入达到1000元时,消费支出平均值置信度95%的预测区间为(536.155,783.845)元。
(3)在95%的置信概率下消费支出C个别值的预测区间。
解:
即是说,当可支配收入达到1000元时,消费支出个别值置信度95%的预测区间为(517.954,782.046)元。
2.4(1)建立建筑面积与建造单位成本的回归方程;
解:
Y=1845.475-64.184X
(2)解释回归系数的经济意义;
解:所估计的参数β1=1845.475,β2=﹣64.184,说明建筑面积每增加1万平方米,建造单位成本将减少64.184元/平方米。
(3)估计当建筑面积为4.5万平方米时,对建造平均单位成本作区间预测。
解:由EViews软件得出Y f=1556.647,这是当X f=4.5时建造单位成本的点预测值。
为了作区间预测,取α=0.05,Y f平均值置信度95%的预测区间为:
根据下图的数据可以计算出:
当X f=4.5时,将相关数据代入计算得到
即是说,当建筑面积达到4.5万平方米时,建造单位成本平均值置信度95%的预测区间为(1533.708,1579.586)元/平方米。
2.6练习题2.2中如果将“财政预算总收入”和“全省生产总值”数据的计量单位分别或同时由“亿元”更改为“万元”,分别重新估计参数,对比被解释变量与解释变量的计量单位分别变动和同时变动的几种情况下,参数估计及统计检验结果与计量单位更改之前有什么区别?你能从中总结出什么规律性吗?
解:1>当“全省生产总值”的计量单位由“亿元”跟改为“万元”,“财政预算总收入”计量单位不变时:
计量经济学实验三
实 验 三: 多元回归模型与非线性回归模型 【实验目的】掌握多元回归模型参数估计,特别是非线性回归模型的转化、参数估计及检验方法。 【实验内容】一、多元回归模型参数估计; 二、生成序列以及可线性化模型的参数估计; 三、不可线性化模型的迭代估计法的Eviews 软件的实现方式。 【实验数据】建立我国国有独立核算工业企业生产函数。根据生产函数理论,生产函数的基本形式为:()ε,,,K L t f Y =。其中,L 、K 分别为生产过程中投入的劳动与资金,时间变量t 反映技术进步的影响。表3-1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y 为工业总产值(可比价),L 、K 分别为年末职工人数和固定资产净值(可比价)。 资料来源:根据《中国统计年鉴-1995》和《中国工业经济年鉴-1995》计算整理 【实验步骤】Y=AK 一、建立多元线性回归模型 ㈠建立包括时间变量的三元线性回归模型; μββββ++++=L K T Y 3210
在命令窗口依次键入以下命令即可: ⒈建立工作文件: CREATE A 78 94 ⒉输入统计资料: DATA Y L K ⒊生成时间变量t : GENR T=@TREND(77) ⒋建立回归模型: LS Y C T L K 则生产函数的估计结果及有关信息如图3-1所示。 图3-1 我国国有独立核算工业企业生产函数的估计结果 因此,我国国有独立工业企业的生产函数为: K L t y 7764.06667.06789.7732.675?+++-= (模型1) t =(-0.252) (0.672) (0.781) (7.433) 9958.02=R 9948 .02=R 551.1018=F 模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为0.6667,资金的边际产出为0.7764,技术进步的影响使工业总产值平均每年递增77.68亿元。回归系数的符号和数值是较为合理的。9958.02=R ,说明模型有很高的拟合优度,F 检验也是高度显著的,说明职工人数L 、资金K 和时间变量t 对工业总产值的总影响是显著的。从图3-1看出,解释变量资金K 的t 统计量值为7.433,表明资金对企业产出的影响是显著的。但是,模型中其他变量(包括常数项)的t 统计量值都较小,未通过检验。因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除t 统计量最小的变量(即时间变量)而重新建立模型。 ㈡建立剔除时间变量的二元线性回归模型; 命令:LS Y C L K 则生产函数的估计结果及有关信息如图3-2所示。
计量经济学1
计量经济学: 是以经济理论为指导,以经济事实为依据,以数学、统计学为方法,以计量经济模型的建立和应用为核心,对经济关系与经济活动数量规律进行研究的一门应用型经济学科。 计量经济四个要素:经济变量(x ,y )、参数(β)、误差项(u )及方程的形式f (·) 利用方差分解表计算F 统计量的过程 完全多重共线性如果存在某解释变量是其他解释变量的线性组合,则称为存在完全多重共线性 近似(不完全)多重共线性若解释变量之间无准确的或完全的线性相关关系,但它们之间存在高度的线性相关性,称模型存在近似(不完全)多重共线性。 Y=X β+u 在多元线性回归模型中,回归系数 表示:在其它解释变量不变的条件下,第j 个解释变量的单位变动对被解释变量平均值的影响。u 是随机误差项。 多重共线性的判断:“经典”判断法多重共线性的“经典”特征是R2较高,方程的F 检验高度显著但参数t 检验显著的不多,如果一个回归分析结果中存在这一特征,则应考虑其是否存在多重共线性的问题。 方差扩大因子法(1-Rj 方)为自变量Xj 的容忍度(Tolerance ),其倒数称为方差扩大因子 经验表明,当VIFj ≥10时,自变量xj 与其它自变量之间的多重共线性程度就非常大了,以至于足以影响到OLSE 的稳定性(方差增大)。 双对数函数模型:βj 称为偏弹性系数。它度量了在其他变量不变的条件下,被解释变量y 对于解释变量Xi 的弹性系数。 对样本回归方程解释如下:斜率系数0.3397表示产出对劳动投入的弹性,即表明在资本投入保持不变的条件下,劳 动投入每增加一个百分点,平均产出将增加0.3397个百分点。同样地,在劳动投入保持不变的条件下,资本投入每增加一个百分点,产出将平均增加0.8419个百分点。两个弹性系数相加为规模报酬系数,其数值大于1,表明该市经济的特征很可能是规模报酬递增的(如果数值等于1,属于规模报酬不变;小于1,则属于规模报酬递减)。根据单边检验的结果,这两个系数各自均是统计显著的(这是用单边检验,即 ,因为我们预期劳动力和资本对产出影响都是正向的),模型的F 值也是高度显著的(因为prob=0.0000),因此能够拒绝零假设:劳动力与资本对产出无影响。R2值为0.995,表明劳动力和资本(对数)的变动解释了大约99.5%的产出(对数)的变动,说明了模型很好地拟合了样本数据。 误差项一阶自相关的DW 检验DW 值越接近于2,ut 的自相关性越小;DW 值越接近于零, ut 正自相关程度越高;DW 值越接近于4, ut 负自相关程度越高 DW 检验的准则如下:⑴当DW
- (4- dL)时,拒绝原假设 H0:ρ=0 ;接受备择假设H1:ρ≠0,ut 存在一阶负自相关。⑶当dU
计量经济学实验一
《计量经济学》综合实验一系金融系专业经融工程姓名程若宸 学号20141206031035 实验地点:B楼305 实验日期:216.9.30 实验题目:研究中国汽车市场未来发展趋势 实验类型:基本操作训练。 实验目的:掌握简单线性回归模型的Eviews操作 实验内容:第三章的“引子”中分析了,经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”等变量,2011年全国各省市区的有关数据见附件:1)建立百户拥有家用汽车量计量经济模型? 2)估计参数并写出回归分析结果报告? 3) 对模型进行经济意义上的检验,统计意义上的检验? 评分标准:操作步骤正确,回归结果正确,结果分析准确到位,符合实际。 实验步骤:
Dependent Variable: Y Method: Least Squares Date: 09/30/16 Time: 11:27 Sample: 1 31 Included observations: 31 Variable Coefficient Std. Error t-Statistic Prob. C 246.8540 51.97500 4.749476 0.0001 X2 5.996865 1.406058 4.265020 0.0002 X3 -0.524027 0.179280 -2.922950 0.0069 X4 -2.265680 0.518837 -4.366842 0.0002 R-squared 0.666062 Mean dependent var 16.77355 Adjusted R-squared 0.628957 S.D. dependent var 8.252535 S.E. of regression 5.026889 Akaike info criterion 6.187394 Sum squared resid 682.2795 Schwarz criterion 6.372424 Log likelihood -91.90460 Hannan-Quinn criter. 6.247709 F-statistic 17.95108 Durbin-Watson stat 1.206953 Prob(F-statistic) 0.000001 (51.98) (1.41) (0.18) (0.52) t= (4.75) (4.27) (-2.92) (-4.37) F=17.951 n=31 模型检验 1.经济意义检验 模型估计结果的数据说明理论分析与经验判断相一致 2.统计检验 (1)拟合优度:修正的可决系数为说明模型对样本拟和
1什么是计量经济学
1什么是计量经济学? 计量经济学是以一定的经济理论和统计资料为基础,运用数学、统计学方法与电脑技术,以建立经济计量模型为主要手段,定量分析研究具有随机性特性的经济变量关系的一门经济学学科。主要内容包括理论计量经济学和应用经济计量学。 2计量经济学分析问题的一般步骤? 设计理论模型,包括模型中变量及模型形式的确定。收集样本数据。估计参数。对模型进行检验,包括经济意义的检验,模型参数的检验,模型假定条件的检验等 3现实数据包括哪几种类型? 横截面数据时间序列数据集合数据 4回归分析的含义? 回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析是应用极其广泛的数据分析方法之一。它基于观测数据建立变量间适当的依赖关系,以分析数据内在规律,并可用于预报、控制等问题。 5回归分析和相关分析的区别? 相关分析中两组变量的地位是平等的,不能说一个是因,另外一个是果。或者他们只是跟另外第三个变量存在因果关系。而回归分析可以定量地得到两个变量之间的关系,其中一个可以看作是因,另一个看作是果。两者位置一般不能互换。 6线性回归和线性分析 8最小二乘法原则:最小二乘法的基本原则是各观察点距直线的纵向距离的平方和最小.这里的“二乘”指的是用平方来度量观测点与估计点的远近,“最小”指的是参数的估计值要保证各个观测点与估计点的距离的平方和达到最小. 9经典线性回归模型的基本假设:1、模型对参数为线性2、重复抽样中X是固定的或非随机的3、干扰项的均值为零4、u的方差相等5、各个干扰项之间无自相关6、无多重共线性,即解释变量间没有完全线性关系7、u和X不相关8、X要有变异性9、模型设定正确 10最小二乘估计量的统计性质? 1.线性特性。 2.无偏性。 3.有效性 4.渐近无偏性 5.一致性 6.渐近有效性 17什么是多重共线性? 对于多元性回归模型,如果某两个或多个解释变量间出现相关性,则称为多重共线性 18多重共线性诊断方法? 1)对两个解释变量的模型,采用简单相关系数法 求出X1和X2的简单相关系数r,若|r|接近1,则说明两变量间存在较强的多重共 线性。 (2)对多个解释变量的模型,采用综合统计检验法 若在OLS下,模型的与F值较大,但各参数估计值的t检验值较少,说明各解释变量对Y的联合线性作用显著,但各解释变量间存在共线性而使得它们对Y的独立作用不能分辨,故t检验不显著。 20虚拟变量引入的原则是什么?虚拟变量的个数按以下原则确定:每一定性变量所需的虚拟变量个数要比该定性变量的类别少1,即如果有m个定性变量,只在模型中引入m-1个虚拟变量
计量经济学实验
中国海洋大学本科生课程大纲 一、课程介绍 1.课程描述: 计量经济学是经济学、数学和统计学相结合的综合性边缘学科。它是以经济理论为基础,以经济事实表现的经济数据为依据,运用数学和统计学的方法,通过建立计量经济模型来研究经济变量之间随机数量关系和规律的一门经济学科。计量经济学是教育部规定的经济类专业核心课程之一,是经济类专业的专业必修课,在经济类的各个专业的教学中占有非常重要的地位。 计量经济实验分析在现代经济研究中具有重要的地位,是经验解释的理论验证、经济发展规律的总结以及经济冲击效果的预测等工作的主要方式。计量经济学的工具类课程性质、软件依赖特征使得实验教学成为理解计量经济理论和掌握其应用方法的有效方式。课程的重点是讲授常用的计量经济学软件的基本操作,使学生熟悉软件界面,熟悉了解常用的菜单项和工具栏的操作,通过分步骤讲解的上机实践,使学生逐步掌握关于计量经济分析的理论和应用问题的研究过程。 Econometrics is a comprehensive fringe subject that combines economics, mathematics and statistics. It is an economic discipline based on economic theory, economic data and economic facts. It uses mathematical and statistical methods to establish econometric models to study the random quantitative relationships and laws between economic variables. Econometrics is one of the core courses for economics majors stipulated by the Ministry of Education. It is a compulsory course for economics majors. It occupies a very important position in the teaching of economics majors. Econometric experimental analysis has an important position in modern economic research. It is the main method of theoretical verification of empirical interpretation,
计量经济学1—
第二章课后习题 2.1(1)分别分析各国人均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的数量关系。 解:各国人均寿命(Y)与人均GDP(X1)之间的数量关系: Y=56.64794+0.12836X1 各国人均寿命(Y)与成人识字率(X2)之间的数量关系: Y=38.79424+0.331971X2 各国人均寿命(Y)与一岁儿童疫苗接种率(X3)之间的数量关系:
Y=31.79956+0.387276X3 (2)对所建立的回归模型近性检验(假设显著性水平α为0.05)。 解:各国人均寿命(Y)与人均GDP(X1)之间的回归模型检验: 1﹥经济意义检验:所估计的参数β1=56.64794,β2=0.12836,说明亚洲各国人均GDP每增加1美元,人均寿命将增加0.12836年,这与预期的经济意义相符。 2﹥拟合有度检验:可决系数R2=0.526082,说明所建模型整体上对样本数据拟合较好,即解释变量“人均GDP”对被解释变量“人均寿命”的一半多作出了解释。 3﹥统计检验:H0:β2=0,H1:β2≠0,因为P=0.0001<α=0.05,所以拒绝原假设,因此亚洲各国人均GDP对人均寿命具有显著影响。 各国人均寿命(Y)与成人识字率(X2)之间的回归模型检验: 1﹥经济意义检验:所估计的参数β1=38.79424,β2=0.331971,说明亚洲各国成人识字率每增加1%,人均寿命将增加0.331971年,这与预期的经济意义相符。 2﹥拟合优度检验:可决系数R2=0.716825,说明所建模型整体上对样本数据拟合较好,即解释变量“成人识字率”对被解释变量“人均寿命”的大部分作出了解释。 3﹥统计检验:H0:β2=0,H1:β2≠0,因为P=0.0000<α=0.05,所以拒绝原假设,因此亚洲各国成人识字率对人均寿命具有显著影响。 各国人均寿命(Y)与一岁儿童疫苗接种率(X3)之间的回归模型检验: 1﹥经济意义检验:所估计的参数β1=31.79956,β2=0.387276,说明亚洲各国一岁儿童疫苗接种率每增加1%,人均寿命将增加0.387276年,这与预期的经济意义相符。 2﹥拟合优度检验:可决系数R2=0.537929,说明所建模型整体上对样本数据拟合较好,即解释变量“一岁儿童疫苗接种率”对被解释变量“人均寿命”的一半多作出了解释。 3﹥统计检验:H0:β2=0,H1:β2≠0,因为P=0.0001<α=0.05,所以拒绝原假设,因此亚洲各国一岁儿童疫苗接种率对人均寿命具有显著影响。 2.2(1)建立浙江省财政预算收入与全省生产总值的计量经济模型,估计模型的参数,检验模型的显著性,用规范的形式写出估计检验结果,并解释所估计参数的经济意义(假设显著性水平为0.05)。
计量经济学1
计量经济学试题 一、单项选择题(本大题共25小题,每小题1分,共25分) 在每小题列出的四个备选项中只有一个是符合题目要求的。请将其代码填写在题后的括号内。错选、多选或未选均无分。 1.经济计量分析工作的研究对象是() A.经济理论 B.经济数学方法 C.经济数学模型 D.社会经济系统 2.在双对数线性模型lnY i=lnβ0+β1lnX i+u i中,β1的含义是() A.Y关于X的增长量 B.Y关于X的发展速度 C.Y关于X的边际倾向 D.Y关于X的弹性 3.在二元线性回归模型:中,表示() A.当X2不变、X1变动一个单位时,Y的平均变动 B.当X1不变、X2变动一个单位时,Y的平均变动 C.当X1和X2都保持不变时, Y的平均变动 D.当X1和X2都变动一个单位时, Y的平均变动 4.如果线性回归模型的随机误差项存在异方差,则参数的普通最小二乘估计量是() A.无偏的,但方差不是最小的 B.有偏的,且方差不是最小的C.无偏的,且方差最小 D.有偏的,但方差仍为最小 5.DW检验法适用于检验() A.异方差 B.序列相关 C.多重共线性 D.设定误差 6.如果X为随机解释变量,X i与随机误差项u i相关,即有Cov(X i, u i)≠0,则普通最小二乘估计是() A.有偏的、一致的 B.有偏的、非一致的 C.无偏的、一致的 D.无偏的、非一致的 7.设某商品需求模型为Y t=β0+β1X t+ u t,其中Y是商品的需求量,X是商品价格,为了考虑全年4个季节变动的影响,假设模型中引入了4个虚拟变量,则会产生的问题为() A.异方差性 B.序列相关 C.不完全的多重共线性 D.完全的多重共线性
计量经济学1
计量经济学 1、一元线性回归模型:建立两个变量的数学模型:Yi=β?+β?Xi +μi ,Yi 为被解释变量。 Xi 为解释变量。μi 为随机误差项(随机扰动项或随机项、误差项)。β?,β?为回归系数(待 定系数、待定参数),这样的模型含有一个解释变量,而且变量之间的关系又是线性的,所 以上式称为一元线性回归模型。 2、线性回归模型的基本假设:假设1、解释变量X 是确定性变量,不是随机变量;假设2、 随机误差项μi 具有零均值、同方差和不序列相关性:E(μi )=0 i=1,2, …,n 。 Var(μi )= δu2 i=1,2, …,n 。Cov(μi ,μj)=0,i≠j i,j= 1,2, …n,假设3、随机误差项μi 与解释变量X 之间不相关:Cov(Xi,μi)=0 i=1,2, …,n,假设4、μi 服从零均值、同方差、零协方差 的正态分布: μi -N(0,δu2)i=1,2, …,n 。注意:1、如果假设1、2满足,则假设3也满足;2、如 果假设4满足,则假设2也满足。 3、普通最小二乘法(OLS ):为了研究总体回归模型中变量X 和Y 之间的线性关系,需要求 一条拟合直线,一条好的拟合直线应该是使残差平方和达到最小,以此为准则,确定X 与Y 之间的线性关系。 4、回归系数:β?=1/n ﹙∑Yi -β?∑Xi ﹚,β?=n∑XiYi -∑Xi∑Yi /n∑Xi2-﹙∑Xi ﹚2 5、常用结果:1、∑ei=0即残差项ei 的均值为0,2、∑eiXi=0即残差项ei 与解释变量Xi 不 相关。3、样本回归方程可以写成Yi o-ˉYˉ=β?(Xi-ˉXˉ)即样本回归直线过点(ˉXˉ, ˉYˉ) 4、ˉYi oˉ=ˉYˉ即被解释变量的样本平均值等于其估计值的平均值 6、样本可决系数:对样本回归直线与样本观测值之间拟合程度的检验。样本观测值距回归 曲线越近,拟合优度越好,X 对Y 的解释程度越强。TSS=∑(Yi- ˉYˉ)2,RSS=∑(Yi o-ˉYˉ) 2,ESS=∑(Yi- Yi o)2其中TSS 为总离差平方和,RSS 为回归平方和(为样本回归线解释的 部分),ESS 为残差平方和(样本回归线不解释的部)R2=RSS /TSS=1-∑ei2/∑yi2=β?2∑xi2 /∑yi=(∑xiyi) 2/∑xi2∑yi2,可决系数的取值范围:[0,1],R2越接近1,说明实际观测点离 样本线越近,拟合优度越高。 7、样本相关系数:R=∑xiyi /(∑xi2∑yi2)? 检验相关系数的t 统计量t=R(n-2) ?/(1-R 2)?~ t(n-2) 8、置信区间:β?~N (β·, δu2∑Xi2/n∑xi 2), β?~﹙βo, δu2/∑xi2﹚令δu2=∑ei2/n-2,t=β?-βo /δβ?~t(n-2),==≥βo∈[β?-tα/2δβ?,β?+tα/2δβ?],β·∈[β?-tα/2δβ?,β?+tα/2δβ?] 9、回归系数估计值的显著性检验-t 检验:t=β?-βo/δβ?~t(n-2),提出假设H0:βo=0,H1: βo≠0 计算t=β2/δβ?,然后比较t 与tα/2(n-2)的大小 10、一元线性回归方程的预测:(1)点预测。将X 的一个特定值 代入样本回归方程,计算得出的 就是 的点预测 (2)区间预测。是求出 的点预测值 之后在一定置信度下求 落在以 为中心的的一个区间,从而可以分析 与 的接近程度,分析结果的可靠性。(1)单个值的预测区间Var(e o)=se 2[1+1/n+( - ) 2/∑xi 2],t= - /δ(e o) ~t(n-2), ∈[ -t α/2δ(e o), + t α/2δ(e o) ](2)均值的预测区间Var(δ0)= se 2[1/n+( - )2/∑xi 2],,t=E( )- /δ0~t(n-2), E( ) ∈[ - t α/2δ0, + t α/2δ0] 11、回归系数的经济意义:β?表示边际倾向,表示Xi 每增加或减少一单位,Yi 便增加或 减少β?个单位,β?是样本回归线在y 轴的截距,表示Yi 不受Xi 影响的情况下自发产生的 行为。 12、多元线性回归模型的基本假定:1、E (ui )=0,即随机误差项是一个期望值或平均值为 零的随机变量。2、var(ui)=E(ui 2) =δ2即对于解释变量X1、X2、·····Xk 的所有观测值, 随机误差项有相同的方差3、cov(ui,uj)=E(uiuj)=0即随机误差项彼此之间不相关。4、 cov(Xij,uj)=0即解释变量X1、X2、····Xk 是确定性变量,不是随机变量,与随机误差项彼 X 0 Y ?0Y 0Y 0Y ?0Y 0Y ?0Y ?0Y 0X 0X Y 0Y ?0Y 0Y ?0Y ?0X 0X Y 0Y ?0 Y 0Y ?0Y ?0
(可直接使用)计量经济学大作业(1).doc
2010-2011第二学期 计量经济学大作业 大作业名称:2008年12月我国税收多因素分析 组长: 学号:00 姓名:专业:财政学 成员: 学号:00 姓名:专业:财政学 学号:00 姓名:专业:财政学 选课班级:A01 任课教师:徐晔成绩: 评语:__________________________________________________ 教师签名:批阅日期:
计量经济大作业要求如下: 目的要求: 1.熟练掌握计量经济学的主要理论与方法; 2.能够理论联系实际; 3.能够运用计量经济学软件Eviews进行计算和分析; 4.要求:word文档格式,内容四千字左右,并附数据。 内容: 1.确立问题: 选择一个经济预测问题或经济分析问题,根据一定的经济理论和实际经验分析所涉及的经济领域或经济系统中某一经济变量与其它一些(至少二个)经济变量之间的因果关系。 2.建立模型: 初步建立其多元线性回归模型,利用软件求解回归方程;进行经济意义检验、统计与经济计量检验,解决可能出现的违反基本假设的问题,最后确定回归方程。 3.提供图表: 给出说明该回归方程建立效果较好的必要的图表,如通过被解释变量的观察值曲线与拟合值曲线来比较其拟合效果。 4.实证分析: 利用回归方程的结果进行一定的经济预测或经济分析。 江西财经大学信息管理学院 计量经济学课程组 2011/2/19
2008年12月 我国税收多因素分析 【摘要】:本文主要分析税收收入与国民生产总值及进出口的关系,通过数据拟合模型,将几者之间的关系量化。 一、研究背景 税收是国家为了实现其职能,按照法定标准,无偿取得财政收入的一种手段,是国家凭借政治权力参与国民收入分配和再分配而形成的一种特定分配关系。是我们国财政收入的基本因素,也影响着我国经济的发展。税收收入的影响因素是来自于多方面的,如居民消费水平、城乡储蓄存款年末余额、财政支出总量以及国内生产总值等等。近年来,我国的税收增长远远快于GDP的增长速度,通过对税收增长的两个影响因素进行分析,从中找出对我国的税收增长影响最大的影响因素。 二、研究目的 税收是国家为了实现其职能,凭借政治权利,参与一部分社会产品或国民收入分配与再分配所进行的一系列经济活动。税收的课税权主体是国家,具体包括各级政府及其财税部门。税收活动的目的是为国家实现其职能服务的,这是所有国家爱税收的共性。 税收分配的对象是一部分社会产品或国民收入,可以是实物或货币,这反映出税收分配由实物形式向货币形式发展演变的过程。税收既是财政收入的支柱,又是宏观调控的杠杆。在国家的宏观调控体系中,税收是集经济、法律、行政手段于一身的重要工具,具有不可替代的作用,是国家职能实现不可缺少的手段。因此,分析税收收入,有助于正确把握宏观经济规律,有助于合理制定国家财政政策,从而起到维护国家、分配收入、配置资源、稳定经济的重要作用。 本文主要通过对国内生产总值和国内进出口总额两个因素进行多因素分析,并根据相关数据,建立模型,对此进行数量分析。在得到我国税收收入与各主要因素间的线性关系后,针对此模型分别对违背基本假设的三种情况进行假设检验和计量经济学检验,并对模型的估计结果进行分析。 我们建立税收收入模型的目的有以下三点: (1)结果分析,即对宏观经济变量之间的关系作定性的分析; (2)预测未来,即预测未来税收收入的总量及规模; (3)政策评价,利用模型对各种政策方案进行分析和比较。 在实际经济系统税收收入的实现过程中,税收收入受到经济增长、GDP总量及结构、进出口总额以及税收政策与制度等因素的影响。而由经济增长转换为税收的增长还要经过政策性和实施性两次漏出,如下图: GDP分解: GDP(C+V+M) →可征税GDP(V+M) →应税GDP →税收 ↓↓↓税收漏出:不可征税GDP(C)政策性漏出实施性漏出 ↓↓税收政策及制度:税制不完善税收征管不力税收经济生活受制于国家政策,国家政策会因税收经济现状而处于部分调整中,这种调整主要是指税收经济的动荡对整体宏观经济造成的消极影响会促使国家为稳定经济采取相应措施。
计量经济学实验报告
《计量经济学》实验报告一,数据 二,理论模型的设计 解释变量:可支配收入X 被解释变量:消费性支出Y 软件操作: (1)X与Y散点图
从散点图可以粗略的看出,随着可支配收入的增加,消费性支出也在增加,大致呈线性关系。因此,建立一元线性回归模型: 01i i i Y X ββμ=++ (2)对模型做OLS 估计 OLS 估计结果为 272.36350.7551Y X ∧ =+ 011.705732.3869t t == 20.9831.. 1.30171048.912R DW F === 三,模型检验 从回归估计结果看,模型拟合较好,可决系数为0.98,表明家庭人均年可消费性支出变化的98.31%可由支配性收入的变化来解释。 t 检验:在5%的显著性水平下1β不显著为0,表明可支配收入增加1个单位,消费性支出平均增加0.7551单位。 1,预测 现已知2018年人均年可支配收入为20000元,预测消费支出预测值为 0272.36350.75512000015374.3635Y =+?= E(X)=6222.209,Var(X)=1994.033
则在95%的置信度下,E( Y)的预测区间为(874.28,16041.68) 2,异方差性检验 对于经济发达地区和经济落后地区,消费支出的决定因素不一定相同甚至差异很大。如经济越落后储蓄率越高,可能出现异方差性问题。 G-Q检验 对样本进行处理,X按从大到小排序,去掉中间4个,分为两组数据, 128 n n ==分别回归
1615472.0RSS = 2126528. 3R S S = 于是的F 统计量: ()() 12811 4.86811RSS F RSS --==-- 在5%的想著想水平下,0.050.05(6,6) 4.28,(6,6)F F F =>,即拒绝无异方差性假设,说明模型存在异方差性。
斯托克,沃森计量经济学第七章实证练习stata
E7.2 E7.3 E7.4
-------------------------------------------- (1) (2) ahe ahe -------------------------------------------- age 0.605*** 0.585*** (15.02) (16.02) female -3.664*** (-17.65) bachelor 8.083*** (38.00) _cons 1.082 -0.636 (0.93) (-0.59) (表2)Robust ci in parentheses *** p<0.01, ** p<0.05, * p<0.1 -------------------------------------------- N 7711 7711 -------------------------------------------- t statistics in parentheses * p<0.10, ** p<0.05, *** p<0.01 (表1) (1) 建立ahe 对age 的回归。截距估计值是1.082,斜率估计值是0.605。 (2) ①建立ahe 对age ,female 和bachelor 的回归。Age 对收入的效应的估计值是0.585。 ② age 回归系数的95%置信区间: (0.514,0.657) (3) 设H 0:βa,(2)-βa,(1)=0 H1:βa,(2)-βa (1)≠0 由表3,得SE ,SE(βa,(2)-βa,(1))=√(0.0403)2+(0.0365)2=0.054 t=(0.605-0.585)/0.054=0.37<1.96 所以不拒绝原假设,即在5%显著水平下age 对ahe 的效应估计没有显著差异,所以(1)中的回归没有遭遇遗漏变量偏差。 (4) B ob’s predicted ahe=0.585×26-3.664×0+8.083×0-0.636=$14.574 Alexis ’s predicted ahe=0.585×30-3.664×1+8.083×1-0.636=$21.333 VARIABLES ahe age 0.585*** (0.514 - 0.657) female -3.664*** (-4.071 - -3.257) bachelor 8.083*** (7.666 - 8.500) Constant -0.636 (-2.759 - 1.487) Observations 7,711 R-squared 0.200
计量经济学实验报告54995
1.背景 经济增长是指一个国家生产商品和劳务能力的扩大。在实际核算中,常以一国生产的商品和劳务总量的增加来表示,即以国民生产总值(GDP )和国内生产总值的的增长来计算。 古典经济增长理论以社会财富的增长为中心,指出生产劳动是财富增长的源泉。现代经济增长理论认为知识、人力资本、技术进步是经济增长的主要因素。 从古典增长理论到新增长理论,都重视物质资本和劳动的贡献。物质资本是指经济系统运行中实际投入的资本数量.然而,由于资本服务流量难以测度,在这里我们用全社会固定资产投资总额(亿元)来衡量物质资本。中国拥有十三亿人口,为经济增长提供了丰富的劳动力资源。因此本文用总就业人数(万人)来衡量劳动力。居民消费需求也是经济增长的主要因素。 经济增长问题既受各国政府和居民的关注,也是经济学理论研究的一个重要方面。在1978—2008年的31年中,我国经济年均增长率高达9.6%,综合国力大大增强,居民收入水平与生活水平不断提高,居民的消费需求的数量和质量有了很大的提高。但是,我国目前仍然面临消费需求不足问题。 本文将以中国经济增长作为研究对象,选择时间序列数据的计量经济学模型方法,将中国国内生产总值与和其相关的经济变量联系起来,建立多元线性回归模型,研究我国中国经济增长变动趋势,以及重要的影响因素,并根据所得的结论提出相关的建议与意见。用计量经济学的方法进行数据的分析将得到更加具有说服力和更加具体的指标,可以更好的帮助我们进行预测与决策。因此,对我国经济增长的计量经济学研究是有意义同时也是很必要的。 2.模型的建立 2.1 假设模型 为了具体分析各要素对我国经济增长影响的大小,我们可以用国内生产总值(Y )这个经济指标作为研究对象;用总就业人员数(1X )衡量劳动力;用固定资产投资总额(2X )衡量资本投入:用价格指数(3X )去代表消费需求。运用这些数据进行回归分析。 这里的被解释变量是,Y :国内生产总值, 与Y-国内生产总值密切相关的经济因素作为模型可能的解释变量,共计3个,它们分别为: 1X 代表社会就业人数, 2X 代表固定资产投资, 3X 代表消费价格指数, μ代表随机干扰项。
计量经济学 作业1
Econometrics ASSIGNMENT 1 100 POINTS TOTAL DUE: Thursday, January 26, 3:20 p.m. **IMPORTANT REMINDER: LATE ASSIGNMENTS CANNOT BE ACCEPTED – NO EXCEPTIONS** Note : Questions 1~3 are simple and straightforward. Questions 4 & 5 are also simple, albeit long. Questions 7 & 8 are on hypothesis testing. 1. [5] Let X be the random variable distributed as Normal (5,4). Find the probabilities of the following events: (i) P(X ≤ 6) (ii) P(X > 4) (iii) P(|X – 5| > 1) 2. [5] Let X denote the prison sentence, in years, for people convicted of auto theft in California. Suppose that the pdf of X is given by 219()(,0 3.=< 一分钟看完计量经济学!!!------开学后的计量笔记 建模是计量的灵魂,所以就从建模开始。 一、 建模步骤:A,理论模型的设计: a,选择变量b,确定变量关系c,拟定参数范围 B,样本数据的收集: a,数据的类型b,数据的质量 C,样本参数的估计: a,模型的识别b,估价方法选择 D,模型的检验 a,经济意义的检验1正相关 2反相关等等 b,统计检验:1检验样本回归函数和样本的拟合优度,R的平方即其修正检验 2样本回归函数和总体回归函数的接近程度:单个解释变量显著性即t检验,函数显著性即F检验,接近程度的区间检验 c,模型预测检验1解释变量条件条件均值与个值的预测 2预测置信空间变化 d,参数的线性约束检验:1参数线性约束的检验 2模型增加或减少变量的检验 3参数的稳定性检验:邹氏参数稳定性检验,邹氏预测检验----------主要方法是以 F检验受约束前后模型的差异 e,参数的非线性约束检验:1最大似然比检验 2沃尔德检验 3拉格朗日乘数检验---------主要方法使用 X平方分布检验统计量分布特征 f,计量经济学检验 1,异方差性问题:特征:无偏,一致但标准差偏误。检测方法:图示法,Park与Gleiser检验法,Goldfeld-Quandt检验法,White检验法-------用WLS修正异方差 2,序列相关性问题:特征:无偏,一致,但检验不可靠,预测无效。检测方法:图示法,回归检验法,Durbin-Waston检验法,Lagrange乘子检验法-------用GLS或广义差分法修正序列相关性 3,多重共线性问题:特征:无偏,一致但标准差过大,t减小,正负号混乱。检测方法:先检验 多重共线性是否存在,再检验多重共线性的范围-------------用逐步回归法,差分法或使用额外信息,增大样本容量可以修正。一分钟看懂计量经济学