文本文件中字符串匹配算法

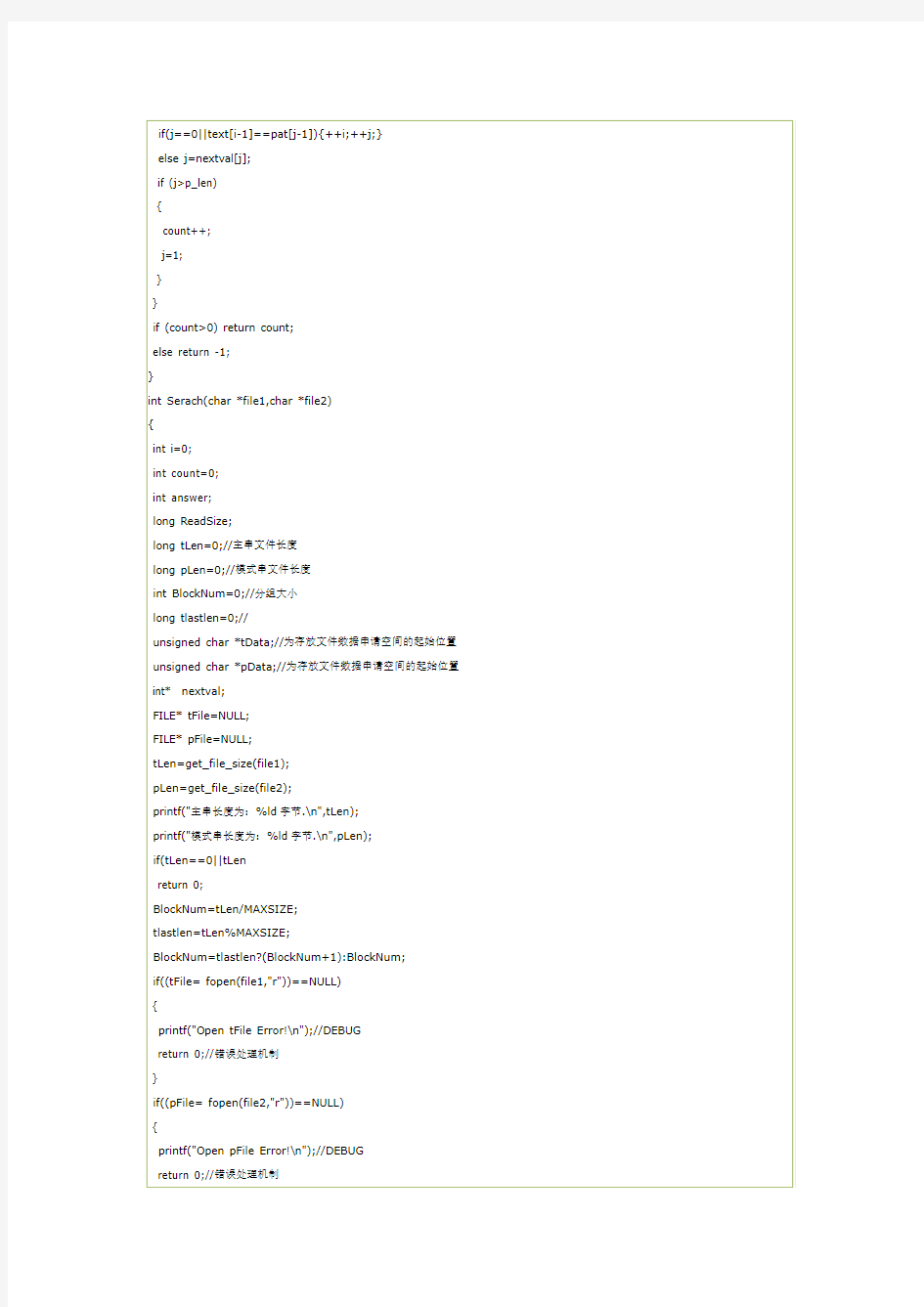
文本文件中字符串匹配算法(kmp)
Halcon中模板匹配方法的总结归纳
Halcon中模板匹配方法的总结归纳 基于组件的模板匹配: 应用场合:组件匹配是形状匹配的扩展,但不支持大小缩放匹配,一般用于多个对象(工件)定位的场合。 算法步骤: 1.获取组件模型里的初始控件gen_initial_components() 参数: ModelImage [Input] 初始组件的图片 InitialComponents [Output] 初始组件的轮廓区域 ContrastLow [Input] 对比度下限 ContrastHigh [Input] 对比度上限 MinSize [Input] 初始组件的最小尺寸 Mode[Input] 自动分段的类型 GenericName [Input] 可选控制参数的名称 GenericValue [Input] 可选控制参数的值 2.根据图像模型,初始组件,训练图片来训练组件和组件相互关系train_model_components() 3.创建组件模型create_trained_component_model() 4.寻找组件模型find_component_model() 5.释放组件模型clear_component_model() 基于形状的模板匹配: 应用场合:定位对象内部的灰度值可以有变化,但对象轮廓一定要清晰平滑。 1.创建形状模型:create_shape_model() 2.寻找形状模型:find_shpae_model() 3.释放形状模型:clear_shape_model() 基于灰度的模板匹配: 应用场合:定位对象内部的灰度值没有大的变化,没有缺失部分,没有干扰图像和噪声的场合。 1.创建模板:create_template() 2.寻找模板:best_match() 3.释放模板:clear_template() 基于互相关匹配: 应用场合:搜索对象有轻微的变形,大量的纹理,图像模糊等场合,速度快,精度低。 1.创建模板:create_ncc_model() 2.寻找模板:find_ncc_model() 3.释放模板:clear_ncc_model() 基于变形匹配: 应用场合:搜索对象有轻微的变形。 1.创建模板:create_local_deformable_model() 2.寻找模板:find_local_deformable_model() 3.释放模板:clear_deformable_model()
字符串的模式匹配算法
在前面的图文中,我们讲了“串”这种数据结构,其中有求“子串在主串中的位置”(字符串的模式匹配)这样的算法。解决这类问题,通常我们的方法是枚举从A串(主串)的什么位置起开始与B串(子串)匹配,然后验证是否匹配。假设A串长度为n,B串长度为m,那么这种方法的复杂度是O(m*n)的。虽然很多时候复杂度达不到m*n(验证时只看头一两个字母就发现不匹配了),但是我们有许多“最坏情况”,比如: A=“aaaaaaaaaaaaaaaaaaaaaaaaab”,B=“aaaaaaaab”。 大家可以忍受朴素模式匹配算法(前缀暴力匹配算法)的低效吗?也许可以,也许无所谓。 有三位前辈D.E.Knuth、J.H.Morris、V.R.Pratt发表一个模式匹配算法,最坏情况下是O(m+n),可以大大避免重复遍历的情况,我们把它称之为克努特-莫里斯-普拉特算法,简称KMP算法。 假如,A=“abababaababacb”,B=“ababacb”,我们来看看KMP是怎样工作的。我们用两个指针i和j分别表示,。也就是说,i是不断增加的,随着i 的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前j个字符(j当然越大越好),现在需要检验A[i+1]和B[j+1]的关系。 例子: S=“abcdefgab” T=“abcdex” 对于要匹配的子串T来说,“abcdex”首字符“a”与后面的串“bcdex”中任意一个字符都不相等。也就是说,既然“a”不与自己后面的子串中任何一字符相等,那么对于主串S来说,前5位字符分别相等,意味着子串T的首字符“a”不可能与S串的第2到第5位的字符相等。朴素算法步骤2,3,4,5的判断都是多余,下次的起始位置就是第6个字符。 例子: S=“abcabcabc” T=“abcabx”
基于模板匹配算法的数字识别讲解
中南民族大学 毕业论文(设计) 学院: 计算机科学学院 专业: 软件工程年级:2009 题目: 基于模板匹配算法的数字识别学生姓名: 李成学号:09065093指导教师姓名: 李波职称: 讲师 2013年5月
中南民族大学本科毕业论文(设计)原创性声明 本人郑重声明:所呈交的论文是本人在导师的指导下独立进行研究所取得的研究成果。除了文中特别加以标注引用的内容外,本论文不包含任何其他个人或集体已经发表或撰写的成果作品。本人完全意识到本声明的法律后果由本人承担。 作者签名:2013年月日
摘要 (1) Abstract (1) 1 绪论 (2) 1.1 研究目的和意义 (2) 1.2 国内外研究现状 (2) 2 本文基本理论介绍 (3) 2.1 位图格式介绍 (3) 2.2 二值化 (3) 2.3 去噪 (3) 2.4 细化 (4) 2.5 提取骨架 (4) 3 图像的预处理 (5) 3.1 位图读取 (5) 3.2 二值化及去噪声 (5) 3.3 提取骨架 (6) 4 基于模板匹配的字符识别 (8) 4.1 样本训练 (8) 4.2 特征提取 (8) 4.3 模板匹配 (9) 4.4 加权特征模板匹配 (10) 4.5 实验流程与结果 (10) 5 结论 (16) 5.1 小结 (16) 5.2 不足 (16) 6 参考文献 (17)
基于模板匹配算法的数字识别 摘要 数字识别已经广泛的应用到日常生活中,典型的数字自动识别系统由图像采集、预处理、二值化、字符定位、字符分割和字符识别等几部分组成, 这些过程存在着紧密的联系。传统的模板匹配算法因为图像在预处理之后可能仍然存在较大的干扰,数字笔画粗细不均匀,有较大的噪声,识别效率不高。本文采的主要思想就是对字符进行分类,之后对字符进行细化,提取细化后字符的特征矢量,与模板的特征矢量进行加权匹配,误差最小的作为识别结果。本文在模板匹配法的基础上, 采用了特征值加权模板匹配法, 并且改进了匹配系数的求法。应用该法取得了满意的效果, 提高了识别率。 关键词:模板匹配;数字识别;特征值加权;字符识别; Template matching algorithm-based digital identification Abstract Digital identification has been widely applied to daily life, the typical digital automatic identification system by the image acquisition, pre-processing, binarization, character positioning, character segmentation and character recognition several parts, there is a close link these processes. Traditional template matching algorithm because the image may still exist after pre-greater interference, digital strokes uneven thickness, the noise, the identification efficiency is not high. Adopted herein main idea is to classify the character after character refinement, the characters feature vector extraction refinement, and the template feature vector is weighted matching, the minimum error as a recognition result. Template matching method based on feature weighted template matching method, and improve the matching coefficient method. The application of the method to obtain satisfactory results, to improve the recognition rate. Key words:Template matching; digital identification; characteristic value weighted; character recognition;
模式匹配的KMP算法详解
模式匹配的KMP算法详解 模式匹配的KMP算法详解 这种由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现的改进的模式匹配算法简称为KMP算法。大概学过信息学的都知道,是个比较难理解的算法,今天特把它搞个彻彻底底明明白白。 注意到这是一个改进的算法,所以有必要把原来的模式匹配算法拿出来,其实理解的关键就在这里,一般的匹配算法: int Index(String S,String T,int pos)//参考《数据结构》中的程序 { i=pos;j=1;//这里的串的第1个元素下标是1 while(i<=S.Length && j<=T.Length) { if(S[i]==T[j]){++i;++j;} else{i=i-j+2;j=1;}//**************(1) } if(j>T.Length) return i-T.Length;//匹配成功 else return 0; } 匹配的过程非常清晰,关键是当‘失配’的时候程序是如何处理的?回溯,没错,注意到(1)句,为什么要回溯,看下面的例子: S:aaaaabababcaaa T:ababc aaaaabababcaaa ababc.(.表示前一个已经失配) 回溯的结果就是 aaaaabababcaaa a.(babc) 如果不回溯就是 aaaaabababcaaa aba.bc 这样就漏了一个可能匹配成功的情况 aaaaabababcaaa ababc 为什么会发生这样的情况?这是由T串本身的性质决定的,是因为T串本身有前后'部分匹配'的性质。如果T为abcdef这样的,大没有回溯的必要。
图像处理技术--模板匹配
图像处理技术——模板匹配算法 左力2002.3. 认知是一个把未知与已知联系起来的过程。对一个复杂的视觉系统来说,它的内部常同时存在着多种输入和其它知识共存的表达形式。感知是把视觉输入与事前已有表达结合的过程,而识别也需要建立或发现各种内部表达式之间的联系。 匹配就是建立这些联系的技术和过程。建立联系的目的是为了用已知解释未知。 章毓晋《图像工程下册》P.163 一.模板匹配的基本概念 模板就是一幅已知的小图像。模板匹配就是在一幅大图像中搜寻目标,已知该图中有要找的目标,且该目标同模板有相同的尺寸、方向和图像,通过一定的算法可以在图中找到目标,确定其坐标位置。 以8位图像(其1个像素由1个字节描述)为例,模板T( m ? n个像素)叠放在被搜索图S( W ? H个像素)上平移,模板覆盖被搜索图的那块区域叫子图Sij。i,j为子图左上角在被搜索图S上的坐标。搜索范围是: 1 ≤ i ≤ W – M 1 ≤ j ≤ H – N 通过比较T和Sij的相似性,完成模板匹配过程。 注意:图像的数据是从下到上、从左到右排列的。 可以用下式衡量T和Sij相似性: ∑∑ = =- = N n ij M m n m T n m S j i D 12 1 )] , ( ) , ( [ ) ,(被搜索图 S 模板 T m i {
∑∑ ∑∑ ∑∑ ======+?-=N n M m N n ij M m N n ij M m n m T n m T n m S n m S 1 2 1 1 1 1 2 1 )] ,([),(),(2)],([ 上式的第一项为子图的能量,第三项为模板的能量,都与模板匹配无关。第二项是模板和子图的互相关,随( i, j )而改变。当模板和子图匹配时,该项有极大值。将其归一化,得模板匹配的相关系数: ∑∑∑∑∑∑======?= N n M m N n ij M m N n ij M m n m T n m S n m T n m S j i R 1 2 1 1 2 1 1 1 )] ,([)],([) ,(),(),( 当模板和子图完全一样时,相关系数R( i, j ) = 1。在被搜索图S 中完成全部搜索后,找出R 的最大值Rmax( im, jm ),其对应的子图Simjm 即为匹配目标。显然,用这种公式做图像匹配计算量大、速度较慢。 另一种算法是衡量T 和Sij 的误差,其公式为: ∑∑ ==-=N n ij M m n m T n m S j i E 1 1 |),(),(|),( E( i, j )为最小值处即为匹配目标。为提高计算速度,取一个误差阈值E 0,当E( i, j )> E 0时就停止该点的计算,继续下一点计算。 试验结果如下: 注:以上试验是在赛扬600 PC 机上用VC6.0进行的。 结果表明:被搜索图越大,匹配速度越慢;模板越小,匹配速度越快。误差法速度较快,阈值的大小对匹配速度影响大,和模板的尺寸有关。 二.改进模板匹配算法 我在误差算法的基础上设计了二次匹配误差算法: 第一次匹配是粗略匹配。取模板的隔行隔列数据,即四分之一的模板数据,在被搜索图上进行隔行隔列扫描匹配,即在原图的四分之一范围内匹配。由于数据量大幅度减少,匹配速度显著提高。 为了合理的给出一个误差阈值E0,我设计了一个确定误差阈值E0的准则: E 0 = e 0 * (m+1)/2 * (n+1)/2
基于HALCON的模板匹配方法总结--蓝云杨的机器视觉之路
基于HALCON的模板匹配方法总结--蓝云杨的机器视觉之路 蓝云杨的机器视觉之路https://www.sodocs.net/doc/5d7244700.html,/blog/user1/8/index.html 首页相册 标签机器视觉(64)图像处理(11)视频压缩(12)小波分析(5)三峡(3)生活随笔(32)HALCON(7)编程感悟(18)哲思慧语(32) 基于HALCON的模板匹配方法总结 2006-8-16 16:34:00 4 推荐很早就想总结一下前段时间学习HALCON的心得,但由于其他的事情总是抽不出时间。去年有过一段时间的集中学习,做了许多的练习和实验,并对基于HDevelop 的形状匹配算法的参数优化进行了研究,写了一篇《基于HDevelop的形状匹配算法参数的优化研究》文章,总结了在形状匹配过程中哪些参数影响到模板的搜索和匹配,又如何来协调这些参数来加快匹配过程,提高匹配的精度,这篇paper放到了中国论文在线了,需要可以去下载。 德国MVTec公司开发的HALCON机器视觉开发软件,提供了许多的功能,在这里我主要学习和研究了其中的形状匹配的算法和流程。HDevelop开发环境中提供的匹配的方法主要有三种,即Component-Based、Gray-Value-Based、Shape-Based,分别是基于组件(或成分、元素)的匹配,基于灰度值的匹配和基于形状的匹配。这三种匹配的方法各具特点,分别适用于不同的图像特征,但都有创建模板和寻找模板的相同过程。这三种方法里面,我主要就第三种-基于形状的匹配,做了许多的实验,因此也做了基于形状匹配的物体识别,基于形状匹配的视频对象分割和基于形状匹配的视频对象跟踪这些研究,从中取得较好的效果,简化了用其他工具,比如VC++来开发的过程。在VC下往往针对不同的图像格式,就会弄的很头疼,更不用说编写图像特征提取、模板建立和搜寻模板的代码呢,我想其中间过程会很复杂,效果也不一定会显著。下面我就具体地谈谈基于HALCON的形状匹配算法的研究和心得总结。 1. Shape-Based matching的基本流程 HALCON提供的基于形状匹配的算法主要是针对感兴趣的小区域来建立模板,对整个图像建立模板也可以,但这样除非是对象在整个图像中所占比例很大,比如像视频会议中人体上半身这样的图像,我在后面的视频对象跟踪实验中就是针对整个图像的,这往往也是要牺牲匹配速度的,这个后面再讲。基本流程是这样的,如下所示: ⑴ 首先确定出ROI的矩形区域,这里只需要确定矩形的左上点和右下点的坐标即可,gen_rectangle1()这个函数就会帮助你生成一个矩形,利用area_center()找到这个矩形的中心; ⑵ 然后需要从图像中获取这个矩形区域的图像,reduce_domain()会得到这个ROI;这之后就可以对这个矩形建立模板,而在建立模板之前,可以先对这个区域进行一些处理,方便以后的建模,比如阈值分割,数学形态学的一些处理等等; ⑶ 接下来就可以利用create_shape_model()来创建模板了,这个函数有许多参数,其中金字塔的级数由Numlevels指定,值越大则找到物体的时间越少,AngleStart 和AngleExtent决定可能的旋转范围,AngleStep指定角度范围搜索的步长;这里需要提醒的是,在任何情况下,模板应适合主内存,搜索时间会缩短。对特别大的模板,用Optimization
字符串匹配算法总结
Brute Force(BF或蛮力搜索) 算法: 这是世界上最简单的算法了。 首先将匹配串和模式串左对齐,然后从左向右一个一个进行比较,如果不成功则模式串向右移动一个单位。 速度最慢。 那么,怎么改进呢? 我们注意到Brute Force 算法是每次移动一个单位,一个一个单位移动显然太慢,是不是可以找到一些办法,让每次能够让模式串多移动一些位置呢? 当然是可以的。 我们也注意到,Brute Force 是很不intelligent 的,每次匹配不成功的时候,前面匹配成功的信息都被当作废物丢弃了,当然,就如现在的变废为宝一样,我们也同样可以将前面匹配成功的信息利用起来,极大地减少计算机的处理时间,节省成本。^_^ 注意,蛮力搜索算法虽然速度慢,但其很通用,文章最后会有一些更多的关于蛮力搜索的信息。 KMP算法 首先介绍的就是KMP 算法。 这个算法实在是太有名了,大学上的算法课程除了最笨的Brute Force 算法,然后就介绍了KMP 算法。也难怪,呵呵。谁让Knuth D.E. 这么world famous 呢,不仅拿了图灵奖,而且还写出了计算机界的Bible
模板匹配
图像模式识别中模板匹配的基本概念以及基本算法 认知是一个把未知与已知联系起来的过程。对一个复杂的视觉系统来说,他的内部常同时存在着多种输入和其他知识共存的表达形式。感知是把视觉输入与事先已有表达结合的过程,而识别与需要建立或发现各种内部表达式之间的联系。匹配就是建立这些联系的技术和过程。建立联系的目的是为了用已知解释未知。(摘自章毓晋《图像工程》) 1、模板匹配法: 在机器识别事物的过程中,常常需要把不同传感器或同一传感器在不同时间、不同成像条件下对同一景象获取的两幅或多幅图像在空间上对准,或根据已知模式到另一幅图像中寻找相应的模式,这就叫匹配。在遥感图像处理中需要把不同波段传感器对同一景物的多光谱图像按照像点对应套准,然后根据像点的性质进行分类。如果利用在不同时间对同一地面拍摄的两幅照片,经套准后找到其中特征有了变化的像点,就可以用来分析图中那些部分发生了变化;而利用放在一定间距处的两只传感器对同一物体拍摄得到两幅图片,找出对应点后可计算出物体离开摄像机的距离,即深度信息。 一般的图像匹配技术是利用已知的模板利用某种算法对识别图像进行匹配计算获得图像中是否含有该模板的信息和坐标; 2、基本算法: 我们采用以下的算式来衡量模板T(m,n)与所覆盖的子图Sij(i,j)的关系,已知原始图像S(W,H),如图所示: 利用以下公式衡量它们的相似性: 上述公式中第一项为子图的能量,第三项为模板的能量,都和模板匹配无关。第二项是模板和子图的互为相关,随(i,j)而改变。当模板和子图匹配时,该项由
最大值。在将其归一化后,得到模板匹配的相关系数: 当模板和子图完全一样时,相关系数R(i,j) = 1。在被搜索图S中完成全部搜索后,找出R的最大值Rmax(im,jm),其对应的子图Simjm即位匹配目标。显然,用这种公式做图像匹配计算量大、速度慢。我们可以使用另外一种算法来衡量T和Sij的误差,其公式为: 计算两个图像的向量误差,可以增加计算速度,根据不同的匹配方向选取一个误差阀值E0,当E(i,j)>E0时就停止该点的计算,继续下一点的计算。 最终的实验证明,被搜索的图像越大,匹配的速度越慢;模板越小,匹配的速度越快;阀值的大小对匹配速度影响大; 3、改进的模板匹配算法 将一次的模板匹配过程更改为两次匹配; 第一次匹配为粗略匹配。取模板的隔行隔列数据,即1/4的模板数据,在被搜索土上进行隔行隔列匹配,即在原图的1/4范围内匹配。由于数据量大幅减少,匹配速度显著提高。同时需要设计一个合理的误差阀值E0: E0 = e0 * (m + 1) / 2 * (n + 1) / 2 式中:e0为各点平均的最大误差,一般取40~50即可; m,n为模板的长宽; 第二次匹配是精确匹配。在第一次误差最小点(imin, jmin)的邻域内,即在对角点为(imin -1, jmin -1), (Imin + 1, jmin + 1)的矩形内,进行搜索匹配,得到最后结果。
实验三____串的模式匹配
实验三串的模式匹配 一、实验目的 1.利用顺序结构存储串,并实现串的匹配算法。 2.掌握简单模式匹配思想,熟悉KMP算法。 二、实验要求 1.认真理解简单模式匹配思想,高效实现简单模式匹配; 2.结合参考程序调试KMP算法,努力算法思想; 3.保存程序的运行结果,并结合程序进行分析。 三、实验内容 1、通过键盘初始化目标串和模式串,通过简单模式匹配算法实现串的模式匹配,匹配成功后要求输出模式串在目标串中的位置; 2、参考程序给出了两种不同形式的next数组的计算方法,请完善程序从键盘初始化一目标串并设计匹配算法完整调试KMP算法,并与简单模式匹配算法进行比较。 参考程序: #include "stdio.h" void GetNext1(char *t,int next[])/*求模式t的next值并寸入next数组中*/ { int i=1,j=0; next[1]=0; while(i<=9)//t[0] { if(j==0||t[i]==t[j]) {++i; ++j; next[i]=j; } else j=next[j]; } } void GetNext2(char *t , int next[])/* 求模式t 的next值并放入数组next中 */ { int i=1, j = 0; next[1]= 0; /* 初始化 */ while (i<=9) /* 计算next[i+1] t[0]*/ { while (j>=1 && t[i] != t[j] ) j = next[j]; i++; j++;
if(t[i]==t[j]) next[i] = next[j]; else next[i] = j; } } void main() { char *p="abcaababc"; int i,str[10]; GetNext1(p,str); printf("\n"); for(i=1;i<10;i++) printf("%d",str[i]); GetNext2(p,str); printf("\n"); for(i=1;i<10;i++) printf("%d",str[i]); printf("\n\n"); }
基於HALCON的模板匹配方法总结
基於HALCON的模板匹配方法總結 基於HALCON的模板匹配方法總結 很早就想總結一下前段時間學習HALCON的心得,但由於其他的事情總是抽不出時間。去年有過一段時間的集中學習,做了許多的練習和實驗,並對基於HDevelop的形狀匹配算法的參數優化進行了研究,寫了一篇《基於HDevelop的形狀匹配算法參數的優化研究》文章,總結了在形狀匹配過程中哪些參數影響到模板的搜索和匹配,又如何來協調這些參數來加快匹配過程,提高匹配的精度,這篇paper放到了中國論文在線了,需要可以去下載。 德國MVTec公司開發的HALCON機器視覺開發軟件,提供了許多的功能,在這裡我主要學習和研究了其中的形狀匹配的算法和流程。HDevelop開發環境中提供的匹配的方法主要有三種,即Component-Based、Gray-Value-Based、Shape-Based,分別是基於組件(或成分、元素)的匹配,基於灰度值的匹配和基於形狀的匹配。這三種匹配的方法各具特點,分別適用於不同的圖像特征,但都有創建模板和尋找模板的相同過程。這三種方法裡面,我主要就第三種-基於形狀的匹配,做了許多的實驗,因此也做了基於形狀匹配的物體識別,基於形狀匹配的視頻對象分割和基於形狀匹配的視頻對象跟蹤這些研究,從中取得較好的效果,簡化了用其他工具,比如VC++來開發的過程。在VC下往往針對不同的圖像格式,就會弄的很頭疼,更不用說編寫圖像特征提取、模板建立和搜尋模板的代碼呢,我想其中間過程會很復雜,效果也不一定會顯著。下面我就具體地談談基於HALCON的形狀匹配算法的研究和心得總結。 1. Shape-Based matching的基本流程 HALCON提供的基於形狀匹配的算法主要是針對感興趣的小區域來建立模板,對整個圖像建立模板也可以,但這樣除非是對象在整個圖像中所佔比例很大,比如像視頻會議中人體上半身這樣的圖像,我在後面的視頻對象跟蹤實驗中就是針對整個圖像的,這往往也是要犧牲匹配速度的,這個後面再講。基本流程是這樣的,如下所示: ⑴首先確定出ROI的矩形區域,這裡只需要確定矩形的左上點和右下點的坐標即可, gen_rectangle1()這個函數就會幫助你生成一個矩形,利用area_center()找到這個矩形的中心; ⑵然後需要從圖像中獲取這個矩形區域的圖像,reduce_domain()會得到這個ROI;這之後就可以對這個矩形建立模板,而在建立模板之前,可以先對這個區域進行一些處理,方便以後的建模,比如閾值分割,數學形態學的一些處理等等; ⑶接下來就可以利用create_shape_model()來創建模板了,這個函數有許多參數,其中金字塔的級數由Numlevels指定,值越大則找到物體的時間越少,AngleStart和AngleExtent 決定可能的旋轉范圍,AngleStep指定角度范圍搜索的步長;這裡需要提醒的是,在任何情
MySQL中的字符串模式匹配.
MySQL中的字符串模式匹配 本文关键字:MySQL 字符串模式匹配 MySQL提供标准的SQL模式匹配,以及一种基于象Unix实用程序如vi、grep 和sed的扩展正则表达式模式匹配的格式。 标准的SQL模式匹配 SQL的模式匹配允许你使用“_”匹配任何单个字符,而“%”匹配任意数目字符(包括零个字符)。在 MySQL中,SQL的模式缺省是忽略大小写的。下面显示一些例子。注意在你使用SQL模式时,你不能使用=或!=;而使用LIKE或NOT LIKE比较操作符。 例如,在表pet中,为了找出以“b”开头的名字: +--------+--------+---------+------+------------+------------+ | name | owner | species | sex | birth | death | +--------+--------+---------+------+------------+------------+ | Buffy | Harold | dog | f | 1989-05-13 | NULL | | Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 | +--------+--------+---------+------+------------+------------+ 为了找出以“fy”结尾的名字:
+--------+--------+---------+------+------------+-------+ | name | owner | species | sex | birth | death | +--------+--------+---------+------+------------+-------+ | Fluffy | Harold | cat | f | 1993-02-04 | NULL | | Buffy | Harold | dog | f | 1989-05-13 | NULL | +--------+--------+---------+------+------------+-------+ 为了找出包含一个“w”的名字: +----------+-------+---------+------+------------+------------+ | name | owner | species | sex | birth | death | +----------+-------+---------+------+------------+------------+
串的模式匹配算法实验报告
竭诚为您提供优质文档/双击可除串的模式匹配算法实验报告 篇一:串的模式匹配算法 串的匹配算法——bruteForce(bF)算法 匹配模式的定义 设有主串s和子串T,子串T的定位就是要在主串s中找到一个与子串T相等的子串。通常把主串s称为目标串,把子串T称为模式串,因此定位也称作模式匹配。模式匹配成功是指在目标串s中找到一个模式串T;不成功则指目标串s中不存在模式串T。bF算法 brute-Force算法简称为bF算法,其基本思路是:从目标串s的第一个字符开始和模式串T中的第一个字符比较,若相等,则继续逐个比较后续的字符;否则从目标串s的第二个字符开始重新与模式串T的第一个字符进行比较。以此类推,若从模式串T的第i个字符开始,每个字符依次和目标串s中的对应字符相等,则匹配成功,该算法返回i;否则,匹配失败,算法返回0。 实现代码如下:
/*返回子串T在主串s中第pos个字符之后的位置。若不存在,则函数返回值为0./*T非空。 intindex(strings,stringT,intpos) { inti=pos;//用于主串s中当前位置下标,若pos不为1则从pos位置开始匹配intj=1;//j用于子串T中当前位置下标值while(i j=1; } if(j>T[0]) returni-T[0]; else return0; } } bF算法的时间复杂度 若n为主串长度,m为子串长度则 最好的情况是:一配就中,只比较了m次。 最坏的情况是:主串前面n-m个位置都部分匹配到子串的最后一位,即这n-m位比较了m次,最后m位也各比较了一次,还要加上m,所以总次数为:(n-m)*m+m=(n-m+1)*m从最好到最坏情况统计总的比较次数,然后取平均,得到一般情况是o(n+m).
KMP字符串模式匹配算法解释
个人觉得这篇文章是网上的介绍有关KMP算法更让人容易理解的文章了,确实说得很“详细”,耐心地把它看完肯定会有所收获的~~,另外有关模式函数值next[i]确实有很多版本啊,在另外一些面向对象的算法描述书中也有失效函数f(j)的说法,其实是一个意思,即next[j]=f(j-1)+1,不过还是next[j]这种表示法好理解啊: KMP字符串模式匹配详解 KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。简单匹配算法的时间复杂度为O(m*n);KMP匹配算法。可以证明它的时间复杂度为O(m+n).。 一.简单匹配算法 先来看一个简单匹配算法的函数: int Index_BF ( char S [ ], char T [ ], int pos ) { /* 若串S 中从第pos(S 的下标0≤pos 基于HALCON的模板匹配方法总结 基于HALCON的模板匹配方法总结 HDevelop开发环境中提供的匹配的方法主要有三种,即Component-Based、Gray-Value-Based、Shape-Based,分别是基于组件(或成分、元素)的匹配,基于灰度值的匹配和基于形状的匹配。这三种匹配的方法各具特点,分别适用于不同的图像特征,但都有创建模板和寻找模板的相同过程。这三种方法里面,我主要就第三种-基于形状的匹配,做了许多的实验,因此也做了基于形状匹配的物体识别,基于形状匹配的视频对象分割和基于形状匹配的视频对象跟踪这些研究,从中取得较好的效果。在VC下往往针对不同的图像格式,就会弄的很头疼,更不用说编写图像特征提取、模板建立和搜寻模板的代码呢,我想其中间过程会很复杂,效果也不一定会显著。下面我就具体地谈谈基于HALCON的形状匹配算法的研究和心得总结。 1. Shape-Based matching的基本流程 HALCON提供的基于形状匹配的算法主要是针对感兴趣的小区域来建立模板,对整个图像建立模板也可以,但这样除非是对象在整个图像中所占比例很大,比如像视频会议中人体上半身这样的图像,我在后面的视频对象跟踪实验中就是针对整个图像的,这往往也是要牺牲匹配速度的,这个后面再讲。基本流程是这样的,如下所示: ⑴ 首先确定出ROI的矩形区域,这里只需要确定矩形的左上点和右下点的坐标即可,gen_rectangle1()这个函数就会帮助你生成一个矩形,利用 area_center()找到这个矩形的中心; ⑵ 然后需要从图像中获取这个矩形区域的图像,reduce_domain()会得到这个ROI;这之后就可以对这个矩形建立模板,而在建立模板之前,可以先对这个区域进行一些处理,方便以后的建模,比如阈值分割,数学形态学的一些处理等等; ⑶ 接下来就可以利用create_shape_model()来创建模板了,这个函数有许多参数,其中金字塔的级数由Numlevels指定,值越大则找到物体的时间越少,AngleStart和AngleExtent决定可能的旋转范围,AngleStep指定角度范围搜索的步长;这里需要提醒的是,在任何情况下,模板应适合主内存,搜索时间会缩短。对特别大的模板,用Optimization来减少模板点的数量是很有用的;MinConstrast将模板从图像的噪声中分离出来,如果灰度值的波动范围是10,则MinConstrast应当设为10;Metric参数决定模板识别的条件,如果设为’use_polarity’,则图像中的物体和模板必须有相同的对比度;创建好模板后,这时还需要监视模板,用inspect_shape_model()来完成,它检查参数的适用性,还能帮助找到合适的参数;另外,还需要获得这个模板的轮廓,用于后面的匹配,get_shape_model_contours()则会很容易的帮我们找到模板的轮廓; ⑷ 创建好模板后,就可以打开另一幅图像,来进行模板匹配了。这个过程也就是在新图像中寻找与模板匹配的图像部分,这部分的工作就由函数 find_shape_model()来承担了,它也拥有许多的参数,这些参数都影响着寻找模板的速度和精度。这个的功能就是在一幅图中找出最佳匹配的模板,返回一个模板实例的长、宽和旋转角度。其中参数SubPixel决定是否精确到亚像素级,设为’interpolation’,则会精确到,这个模式不会占用太多时间,若需要更精确,则可设为’least_square’,’lease_square_high’,但这样会增加额外的时间,因此,这需要在时间和精度上作个折中,需要和实际联系起来。比较重要的两个参数是MinSocre和Greediness,前一个用来分析模板的旋转对称和它们之间的相似度,值越大,则越相似,后一个是搜索贪婪度,这个值在很大程度上影响着搜索速度,若为0,则为启发式搜索,很耗时,若为1,则为不安全搜索,但最快。在大多数情况下,在能够匹配的情况下,尽可能的增大其值。 ⑸ 找到之后,还需要对其进行转化,使之能够显示,这两个函数 vector_angle_to_rigid()和affine_trans_contour_xld()在这里就起这个作用。前一个是从一个点和角度计算一个刚体仿射变换,这个函数从匹配函数的 HALCON形状匹配总结 Halcon有三种模板匹配方法:即Component-Based、Gray-Value-Based、Shaped_based,分别是基于组件(或成分、元素)的匹配,基于灰度值的匹配和基于形状的匹配, 此外还有变形匹配和三维模型匹配也是分属于前面的大类 本文只对形状匹配做简要说明和补充: Shape_Based匹配方法: 上图介绍的是形状匹配做法的一般流程及模板制作的两种 方法。 先要补充点知识:形状匹配常见的有四种情况一般形状匹配模板shape_model、线性变形匹配模板 planar_deformable_model、局部可变形模板 local_deformable_model、和比例缩放模板Scale_model 第一种是不支持投影变形的模板匹配,但是速度是最高的, 第二种和第四种是支持投影变形的匹配,第三种则是支持局 部变形的匹配。 一般形状匹配模板是最常用的,模板的形状和大小一经制作 完毕便不再改变,在查找模板的过程中,只会改变模板的方 向和位置等来匹配目标图像中的图像。这个方法查找速度很 快,但是当目标图像中与模板对应的图像存在比例放大缩小 或是投影变形如倾斜等,均会影响查找结果。涉及到的算子 通常为create_shape_model 和find_shape_model 线性变形匹配模板planar_deformable_model是指模板在行列方向上可以进行适当的缩放。行列方向上可以分别独立的 进行一个适当的缩放变形来匹配。主要参数有行列方向查找 缩放比例、图像金字塔、行列方向匹配分数(指可接受的匹 配分数,大于这个值就接受,小于它就舍弃)、设置超找的角度、已经超找结果后得到的位置和匹配分数 线性变形匹配又分为两种:带标定的可变形模板匹配和不带 标定的可变形模板匹配。涉及到的算子有: 不带标定的模板:创建和查找模板算子 create_planar_uncalib_deformable_model和 find_planar_uncalib_deformable_model 带标定模板的匹配:先读入摄像机内参和外参 read_cam_par 和read_pose 创建和查找模板算子create_planar_calib_deformable_model和 find_planar_calib_deformable_model 局部变形模板是指在一张图上查找模板的时候,可以改变 模板的尺寸,来查找图像上具有局部变形的模板。例如包装 纸袋上图案查找。参数和线性变形额差不多 算子如下:create_local_deformable_model和 find_local_deformable_model 1、模板匹配法: 在机器识别事物的过程中,常常需要把不同传感器或同一传感器在不同时间、不同成像条件下对同一景象获取的两幅或多幅图像在空间上对准,或根据已知模式到另一幅图像中寻找相应的模式,这就叫匹配。在遥感图像处理中需要把不同波段传感器对同一景物的多光谱图像按照像点对应套准,然后根据像点的性质进行分类。如果利用在不同时间对同一地面拍摄的两幅照片,经套准后找到其中特征有了变化的像点,就可以用来分析图中那些部分发生了变化;而利用放在一定间距处的两只传感器对同一物体拍摄得到两幅图片,找出对应点后可计算出物体离开摄像机的距离,即深度信息。 一般的图像匹配技术是利用已知的模板利用某种算法对识别图像进行匹配计算获得图像中是否含有该模板的信息和坐标; 2、基本算法: 我们采用以下的算式来衡量模板T(m,n)与所覆盖的子图Sij(i,j)的关系,已知原始图像S(W,H),如图所示: 利用以下公式衡量它们的相似性: 上述公式中第一项为子图的能量,第三项为模板的能量,都和模板匹配无关。第二项是模板和子图的互为相关,随(i,j)而改变。当模板和子图匹配时,该项由最大值。在将其归一化后,得到模板匹配的相关系数: 当模板和子图完全一样时,相关系数R(i,j) = 1。在被搜索图S中完成全部搜索后,找出R的最大值Rmax(im,jm),其对应的子图Simjm即位匹配目标。显然,用这种公式做图像匹配计算量大、速度慢。我们可以使用另外一种算法来衡量T和Sij的误差,其公式为: 计算两个图像的向量误差,可以增加计算速度,根据不同的匹配方向选取一个误差阀值E0,当E(i,j)>E0时就停止该点的计算,继续下一点的计算。 最终的实验证明,被搜索的图像越大,匹配的速度越慢;模板越小,匹配的速度越快;阀值的大小对匹配速度影响大; 3、改进的模板匹配算法 将一次的模板匹配过程更改为两次匹配; 第一次匹配为粗略匹配。取模板的隔行隔列数据,即1/4的模板数据,在被搜索土上进行隔行隔列匹配,即在原图的1/4范围内匹配。由于数据量大幅减少,匹配速度显著提高。同时需要设计一个合理的误差阀值E0: E0 = e0 * (m + 1) / 2 * (n + 1) / 2 式中:e0为各点平均的最大误差,一般取40~50即可; m,n为模板的长宽; 第二次匹配是精确匹配。在第一次误差最小点(imin, jmin)的邻域内,即在对角点为(imin -1, jmin -1), (Imin + 1, jmin + 1)的矩形内,进行搜索匹配,得到最后结果。基于HALCON的模板匹配方法总结.
HALCON形状匹配总结
模板匹配算法