数据存储五种方式

Andorid五种数据存储方式:
本文介绍Android平台进行数据存储的五大方式,分别如下:
1 使用SharedPreferences存储数据
2 文件存储数据
3 SQLite数据库存储数据
4 使用ContentProvider存储数据
5 网络存储数据
下面详细讲解这五种方式的特点
第一种:使用SharedPreferences存储数据共享参数
适用范围:保存少量的数据,且这些数据的格式非常简单:字符串型、基本类型的值。比如应用程序的各种配置信息(如是否打开音效、是否使用震动效果、小游戏的玩家积分等),解锁口令密码等
核心原理:保存基于XML文件存储的key-value键值对数据,通常用来存储一些简单的配置信息。通过DDMS的File Explorer面板,展开文件浏览树,很明显SharedPreferences 数据总是存储在/data/data/
Context.MODE_PRIVATE: 指定该SharedPreferences数据只能被本应用程序读、写。
Context.MODE_WORLD_READABLE: 指定该SharedPreferences数据能被其他应用程序读,但不能写。
Context.MODE_WORLD_WRITEABLE: 指定该SharedPreferences数据能被其他应用程序读,写
Editor有如下主要重要方法:
SharedPreferences.Editor clear():清空SharedPreferences里所有数据
SharedPreferences.Editor putXxx(String key , xxx value): 向SharedPreferences存入指定key对应的数据,其中xxx 可以是boolean,float,int等各种基本类型据
SharedPreferences.Editor remove(): 删除SharedPreferences中指定key对应的数据项
boolean commit(): 当Editor编辑完成后,使用该方法提交修改
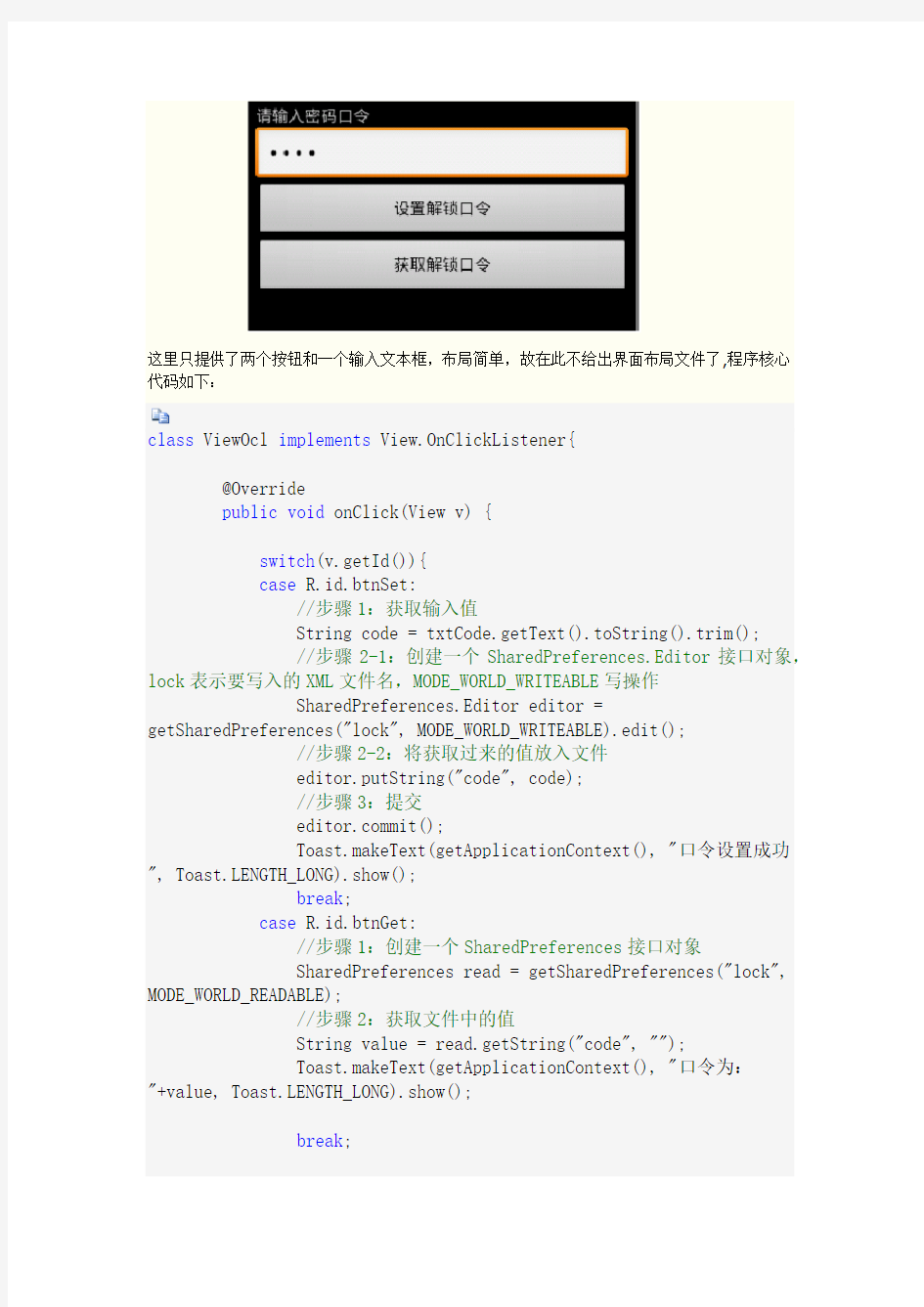
实际案例:运行界面如下
这里只提供了两个按钮和一个输入文本框,布局简单,故在此不给出界面布局文件了,程序核心
代码如下:
class ViewOcl implements View.OnClickListener{
@Override
public void onClick(View v) {
switch(v.getId()){
case R.id.btnSet:
//步骤1:获取输入值
String code = txtCode.getText().toString().trim();
//步骤2-1:创建一个SharedPreferences.Editor接口对象,lock表示要写入的XML文件名,MODE_WORLD_WRITEABLE写操作
SharedPreferences.Editor editor = getSharedPreferences("lock", MODE_WORLD_WRITEABLE).edit();
//步骤2-2:将获取过来的值放入文件
editor.putString("code", code);
//步骤3:提交
https://www.sodocs.net/doc/e110858253.html,mit();
Toast.makeText(getApplicationContext(), "口令设置成功", Toast.LENGTH_LONG).show();
break;
case R.id.btnGet:
//步骤1:创建一个SharedPreferences接口对象
SharedPreferences read = getSharedPreferences("lock", MODE_WORLD_READABLE);
//步骤2:获取文件中的值
String value = read.getString("code", "");
Toast.makeText(getApplicationContext(), "口令为:
"+value, Toast.LENGTH_LONG).show();
break;
}
}
}
读写其他应用的SharedPreferences: 步骤如下
1、在创建SharedPreferences时,指定MODE_WORLD_READABLE模式,
表明该SharedPreferences数据可以被其他程序读取
2、创建其他应用程序对应的Context:
Context pvCount = createPackageContext("com.tony.app", Context.CONTEXT_IGNORE_SECURITY);这里的com.tony.app就是其他程序的包名
3、使用其他程序的Context获取对应的SharedPreferences
SharedPreferences read = pvCount.getSharedPreferences("lock", Context.MODE_WORLD_READABLE);
4、如果是写入数据,使用Editor接口即可,所有其他操作均和前面一致。
SharedPreferences对象与SQLite数据库相比,免去了创建数据库,创建表,写SQL语句
等诸多操作,相对而言更加方便,简洁。但是SharedPreferences也有其自身缺陷,比如其
职能存储boolean,int,float,long和String五种简单的数据类型,比如其无法进行条件
查询等。所以不论SharedPreferences的数据存储操作是如何简单,它也只能是存储方式的
一种补充,而无法完全替代如SQLite数据库这样的其他数据存储方式。
第二种:文件存储数据 SD卡
核心原理: Context提供了两个方法来打开数据文件里的文件IO流 FileInputStream openFileInput(String name); FileOutputStream(String name , int mode),这两个方
法第一个参数用于指定文件名,第二个参数指定打开文件的模式。具体有以下值可选:
MODE_PRIVATE:为默认操作模式,代表该文件是私有数据,只能被应用本身
访问,在该模式下,写入的内容会覆盖原文件的内容,如果想把新写入的内容追加到原文件中。可以使用Context.MODE_APPEND
MODE_APPEND:模式会检查文件是否存在,存在就往文件追加内容,否则就创
建新文件。
MODE_WORLD_READABLE:表示当前文件可以被其他应用读取;
MODE_WORLD_WRITEABLE:表示当前文件可以被其他应用写入。
除此之外,Context还提供了如下几个重要的方法:
getDir(String name , int mode):在应用程序的数据文件夹下获取或者创建name对应的子目录
File getFilesDir():获取该应用程序的数据文件夹得绝对路径
String[] fileList():返回该应用数据文件夹的全部文件
实际案例:界面沿用上图
核心代码如下:
public String read() {
try {
FileInputStream inStream =
this.openFileInput("message.txt");
byte[] buffer = new byte[1024];
int hasRead = 0;
StringBuilder sb = new StringBuilder();
while ((hasRead = inStream.read(buffer)) != -1) {
sb.append(new String(buffer, 0, hasRead));
}
inStream.close();
return sb.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public void write(String msg){
// 步骤1:获取输入值
if(msg == null) return;
try {
// 步骤2:创建一个FileOutputStream对象,MODE_APPEND追加模式
FileOutputStream fos = openFileOutput("message.txt",
MODE_APPEND);
// 步骤3:将获取过来的值放入文件
fos.write(msg.getBytes());
// 步骤4:关闭数据流
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
openFileOutput()方法的第一参数用于指定文件名称,不能包含路径分隔符“/” ,如果文件不存在,Android 会自动创建它。创建的文件保存在/data/data/
下面讲解某些特殊文件读写需要注意的地方:
读写sdcard上的文件
其中读写步骤按如下进行:
1、调用Environment的getExternalStorageState()方法判断手机上是否插了sd卡,且应用程序具有读写SD卡的权限,如下代码将返回true
Environment.getExternalStorageState().equals(Environment.MEDIA_MOUNTED) 2、调用Environment.getExternalStorageDirectory()方法来获取外部存储器,也就是SD卡的目录,或者使用"/mnt/sdcard/"目录
3、使用IO流操作SD卡上的文件
注意点:手机应该已插入SD卡,对于模拟器而言,可通过mksdcard命令来创建虚拟存储卡必须在AndroidManifest.xml上配置读写SD卡的权限
android:name="android.permission.MOUNT_UNMOUNT_FILESYSTEMS"/> android:name="android.permission.WRITE_EXTERNAL_STORAGE"/> 案例代码: // 文件写操作函数 private void write(String content) { if (Environment.getExternalStorageState().equals( Environment.MEDIA_MOUNTED)) { // 如果sdcard存在 File file = new File(Environment.getExternalStorageDirectory() .toString() + File.separator + DIR + File.separator + FILENAME); // 定义File类对象 if (!file.getParentFile().exists()) { // 父文件夹不存在 file.getParentFile().mkdirs(); // 创建文件夹 } PrintStream out = null; // 打印流对象用于输出 try { out = new PrintStream(new FileOutputStream(file, true)); // 追加文件 out.println(content); } catch (Exception e) { e.printStackTrace(); } finally { if (out != null) { out.close(); // 关闭打印流 } } } else { // SDCard不存在,使用Toast提示用户 Toast.makeText(this, "保存失败,SD卡不存在!", Toast.LENGTH_LONG).show(); } } // 文件读操作函数 private String read() { if (Environment.getExternalStorageState().equals( Environment.MEDIA_MOUNTED)) { // 如果sdcard存在 File file = new File(Environment.getExternalStorageDirectory() .toString() + File.separator + DIR + File.separator + FILENAME); // 定义File类对象 if (!file.getParentFile().exists()) { // 父文件夹不存在 file.getParentFile().mkdirs(); // 创建文件夹 } Scanner scan = null; // 扫描输入 StringBuilder sb = new StringBuilder(); try { scan = new Scanner(new FileInputStream(file)); // 实例化Scanner while (scan.hasNext()) { // 循环读取 sb.append(scan.next() + "\n"); // 设置文本 } return sb.toString(); } catch (Exception e) { e.printStackTrace(); } finally { if (scan != null) { scan.close(); // 关闭打印流 } } } else { // SDCard不存在,使用Toast提示用户 Toast.makeText(this, "读取失败,SD卡不存在!", Toast.LENGTH_LONG).show(); } return null; } 第三种:SQLite存储数据 {} SQLite是轻量级嵌入式数据库引擎,它支持 SQL 语言,并且只利用很少的内存就有很好的性能。现在的主流移动设备像Android、iPhone等都使用SQLite作为复杂数据的存储引擎,在 我们为移动设备开发应用程序时,也许就要使用到SQLite来存储我们大量的数据,所以我们 就需要掌握移动设备上的SQLite开发技巧 SQLiteDatabase类为我们提供了很多种方法,上面的代码中基本上囊括了大部分的数据库操作;对于添加、更新和删除来说,我们都可以使用 1 db.executeSQL(String sql); 2 db.executeSQL(String sql, Object[] bindArgs);//sql语句中使用占位符,然后第二个参数是实际的参数集 除了统一的形式之外,他们还有各自的操作方法: 1 db.insert(String table, String nullColumnHack, ContentValues values); 2 db.update(String table, Contentvalues values, String whereClause, String whereArgs); 3 db.delete(String table, String whereClause, String whereArgs); 以上三个方法的第一个参数都是表示要操作的表名;insert中的第二个参数表示如果插入的数 据每一列都为空的话,需要指定此行中某一列的名称,系统将此列设置为NULL,不至于出现 错误;insert中的第三个参数是ContentValues类型的变量,是键值对组成的Map,key代 表列名,value代表该列要插入的值;update的第二个参数也很类似,只不过它是更新该字 段key为最新的value值,第三个参数whereClause表示WHERE表达式,比如“age > ? and age < ?”等,最后的whereArgs参数是占位符的实际参数值;delete方法的参数也是 一样 下面给出demo 数据的添加 1.使用insert方法 1 ContentValues cv = new ContentValues();//实例化一个ContentValues用来装载待插入的数据 2 cv.put("title","you are beautiful");//添加title 3 cv.put("weather","sun"); //添加weather 4 cv.put("context","xxxx"); //添加context 5 String publish = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") 6 .format(new Date()); 7 cv.put("publish ",publish); //添加publish 8 db.insert("diary",null,cv);//执行插入操作 2.使用execSQL方式来实现 String sql = "insert into user(username,password) values ('Jack Johnson','iLovePopMuisc');//插入操作的SQL语句 db.execSQL(sql);//执行SQL语句 数据的删除 同样有2种方式可以实现 String whereClause = "username=?";//删除的条件 String[] whereArgs = {"Jack Johnson"};//删除的条件参数 db.delete("user",whereClause,whereArgs);//执行删除 使用execSQL方式的实现 String sql = "delete from user where username='Jack Johnson'";//删除 操作的SQL语句 db.execSQL(sql);//执行删除操作 数据修改 同上,仍是2种方式 ContentValues cv = new ContentValues();//实例化ContentValues cv.put("password","iHatePopMusic");//添加要更改的字段及内容 String whereClause = "username=?";//修改条件 String[] whereArgs = {"Jack Johnson"};//修改条件的参数 db.update("user",cv,whereClause,whereArgs);//执行修改 使用execSQL方式的实现 String sql = "update user set password = 'iHatePopMusic' where username='Jack Johnson'";//修改的SQL语句 db.execSQL(sql);//执行修改 数据查询 下面来说说查询操作。查询操作相对于上面的几种操作要复杂些,因为我们经常要面对着各种 各样的查询条件,所以系统也考虑到这种复杂性,为我们提供了较为丰富的查询形式: 1 db.rawQuery(String sql, String[] selectionArgs); 2 db.query(String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy); 3 db.query(String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy, String limit); 4 db.query(String distinct, String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy, String limit); 上面几种都是常用的查询方法,第一种最为简单,将所有的SQL语句都组织到一个字符串中,使用占位符代替实际参数,selectionArgs就是占位符实际参数集; 各参数说明: ?table:表名称 ?colums:表示要查询的列所有名称集 ?selection:表示WHERE之后的条件语句,可以使用占位符 ?selectionArgs:条件语句的参数数组 ?groupBy:指定分组的列名 ?having:指定分组条件,配合groupBy使用 ?orderBy:y指定排序的列名 ?limit:指定分页参数 ?distinct:指定“true”或“false”表示要不要过滤重复值 ?Cursor:返回值,相当于结果集ResultSet 最后,他们同时返回一个Cursor对象,代表数据集的游标,有点类似于JavaSE中的ResultSet。下面是Cursor对象的常用方法: 1 c.move(int offset); //以当前位置为参考,移动到指定行 2 c.moveToFirst(); //移动到第一行 3 c.moveToLast(); //移动到最后一行 4 c.moveToPosition(int position); //移动到指定行 5 c.moveToPrevious(); //移动到前一行 6 c.moveToNext(); //移动到下一行 7 c.isFirst(); //是否指向第一条 8 c.isLast(); //是否指向最后一条 9 c.isBeforeFirst(); //是否指向第一条之前 10 c.isAfterLast(); //是否指向最后一条之后 11 c.isNull(int columnIndex); //指定列是否为空(列基数为0) 12 c.isClosed(); //游标是否已关闭 13 c.getCount(); //总数据项数 14 c.getPosition(); //返回当前游标所指向的行数 15 c.getColumnIndex(String columnName);//返回某列名对应的列索引值 16 c.getString(int columnIndex); //返回当前行指定列的值 实现代码 String[] params = {12345,123456}; Cursor cursor = db.query("user",columns,"ID=?",params,null,null,null);//查询并获得游标 if(cursor.moveToFirst()){//判断游标是否为空 for(int i=0;i cursor.move(i);//移动到指定记录 String username = cursor.getString(cursor.getColumnIndex("username"); String password = cursor.getString(cursor.getColumnIndex("password")); } } 通过rawQuery实现的带参数查询 Cursor result=db.rawQuery("SELECT ID, name, inventory FROM mytable"); //Cursor c = db.rawQuery("s name, inventory FROM mytable where ID=?",new Stirng[]{"123456"}); result.moveToFirst(); while (!result.isAfterLast()) { int id=result.getInt(0); String name=result.getString(1); int inventory=result.getInt(2); // do something useful with these result.moveToNext(); } result.close(); 在上面的代码示例中,已经用到了这几个常用方法中的一些,关于更多的信息,大家可以参考官方文档中的说明。 最后当我们完成了对数据库的操作后,记得调用SQLiteDatabase的close()方法释放数据库连接,否则容易出现SQLiteException。 上面就是SQLite的基本应用,但在实际开发中,为了能够更好的管理和维护数据库,我们会 封装一个继承自SQLiteOpenHelper类的数据库操作类,然后以这个类为基础,再封装我们 的业务逻辑方法。 这里直接使用案例讲解:下面是案例demo的界面 SQLiteOpenHelper 类介绍 SQLiteOpenHelper是SQLiteDatabase的一个帮助类,用来管理数据库的创建和版本的更新。一般是建立一个类继承它,并实现它的onCreate和onUpgrade方法。 首先创建数据库类 1import android.content.Context; 2import android.database.sqlite.SQLiteDatabase; 3import android.database.sqlite.SQLiteDatabase.CursorFactory; 4import android.database.sqlite.SQLiteOpenHelper; 5 6public class SqliteDBHelper extends SQLiteOpenHelper { 7 8// 步骤1:设置常数参量 9private static final String DATABASE_NAME = "diary_db"; 10private static final int VERSION = 1; 11private static final String TABLE_NAME = "diary"; 12 13// 步骤2:重载构造方法 14public SqliteDBHelper(Context context) { 15super(context, DATABASE_NAME, null, VERSION); 16 } 17 18/* 19 * 参数介绍:context 程序上下文环境即:XXXActivity.this 20 * name 数据库名字 21 * factory 接收数据,一般情况为null 22 * version 数据库版本号 23*/ 24public SqliteDBHelper(Context context, String name, CursorFactory factory, 25int version) { 26super(context, name, factory, version); 27 } 28//数据库第一次被创建时,onCreate()会被调用 29 @Override 30public void onCreate(SQLiteDatabase db) { 31// 步骤3:数据库表的创建 32 String strSQL = "create table " 33 + TABLE_NAME 34 + "(tid integer primary key autoincrement,title varchar(20),weather varchar(10),context text,publish date)"; 35//步骤4:使用参数db,创建对象 36 db.execSQL(strSQL); 37 } 38//数据库版本变化时,会调用onUpgrade() 39 @Override 40public void onUpgrade(SQLiteDatabase arg0, int arg1, int arg2) { 41 42 } 43 } 正如上面所述,数据库第一次创建时onCreate方法会被调用,我们可以执行创建表的语句,当系统发现版本变化之后,会调用onUpgrade方法,我们可以执行修改表结构等语句。 我们需要一个Dao,来封装我们所有的业务方法,代码如下: 1import android.content.Context; 2import android.database.Cursor; 3import android.database.sqlite.SQLiteDatabase; 4 5import com.chinasoft.dbhelper.SqliteDBHelper; 6 7public class DiaryDao { 8 9private SqliteDBHelper sqliteDBHelper; 10private SQLiteDatabase db; 11 12// 重写构造方法 13public DiaryDao(Context context) { 14this.sqliteDBHelper = new SqliteDBHelper(context); 15 db = sqliteDBHelper.getWritableDatabase(); 16 } 17 18// 读操作 19public String execQuery(final String strSQL) { 20try { 21 System.out.println("strSQL>" + strSQL); 22// Cursor相当于JDBC中的ResultSet 23 Cursor cursor = db.rawQuery(strSQL, null); 24// 始终让cursor指向数据库表的第1行记录 25 cursor.moveToFirst(); 26// 定义一个StringBuffer的对象,用于动态拼接字符串 27 StringBuffer sb = new StringBuffer(); 28// 循环游标,如果不是最后一项记录 29while (!cursor.isAfterLast()) { 30 sb.append(cursor.getInt(0) + "/" + cursor.getString(1) + "/" 31 + cursor.getString(2) + "/" + cursor.getString(3) + "/" 32 + cursor.getString(4)+"#"); 33//cursor游标移动 34 cursor.moveToNext(); 35 } 36 db.close(); 37return sb.deleteCharAt(sb.length()-1).toString(); 38 } catch (RuntimeException e) { 39 e.printStackTrace(); 40return null; 41 } 42 43 } 44 45// 写操作 46public boolean execOther(final String strSQL) { 47 db.beginTransaction(); //开始事务 48try { 49 System.out.println("strSQL" + strSQL); 50 db.execSQL(strSQL); 51 db.setTransactionSuccessful(); //设置事务成功完成 52 db.close(); 53return true; 54 } catch (RuntimeException e) { 55 e.printStackTrace(); 56return false; 57 }finally { 58 db.endTransaction(); //结束事务 59 } 60 61 } 62 } 我们在Dao构造方法中实例化sqliteDBHelper并获取一个SQLiteDatabase对象,作为整个应用的数据库实例;在增删改信息时,我们采用了事务处理,确保数据完整性;最后要注意释放数据库资源db.close(),这一个步骤在我们整个应用关闭时执行,这个环节容易被忘记,所以朋友们要注意。 我们获取数据库实例时使用了getWritableDatabase()方法,也许朋友们会有疑问,在getWritableDatabase()和getReadableDatabase()中,你为什么选择前者作为整个应用的数据库实例呢?在这里我想和大家着重分析一下这一点。 我们来看一下SQLiteOpenHelper中的getReadableDatabase()方法: 1public synchronized SQLiteDatabase getReadableDatabase() { 2if (mDatabase != null && mDatabase.isOpen()) { 3// 如果发现mDatabase不为空并且已经打开则直接返回 4return mDatabase; 5 } 6 7if (mIsInitializing) { 8// 如果正在初始化则抛出异常 9throw new IllegalStateException("getReadableDatabase called recursively"); 10 } 11 12// 开始实例化数据库mDatabase 13 14try { 15// 注意这里是调用了getWritableDatabase()方法 16return getWritableDatabase(); 17 } catch (SQLiteException e) { 18if (mName == null) 19throw e; // Can't open a temp database read-only! 20 Log.e(TAG, "Couldn't open " + mName + " for writing (will try read-only):", e); 21 } 22 23// 如果无法以可读写模式打开数据库则以只读方式打开 24 25 SQLiteDatabase db = null; 26try { 27 mIsInitializing = true; 28 String path = mContext.getDatabasePath(mName).getPath();// 获取数据库路径 29// 以只读方式打开数据库 30 db = SQLiteDatabase.openDatabase(path, mFactory, SQLiteDatabase.OPEN_READONLY); 31if (db.getVersion() != mNewVersion) { 32throw new SQLiteException("Can't upgrade read-only database from version " + db.getVersion() + " to " 33 + mNewVersion + ": " + path); 34 } 35 36 onOpen(db); 37 Log.w(TAG, "Opened " + mName + " in read-only mode"); 38 mDatabase = db;// 为mDatabase指定新打开的数据库 39return mDatabase;// 返回打开的数据库 40 } finally { 41 mIsInitializing = false; 42if (db != null && db != mDatabase) 43 db.close(); 44 } 45 } 在getReadableDatabase()方法中,首先判断是否已存在数据库实例并且是打开状态,如果是,则直接返回该实例,否则试图获取一个可读写模式的数据库实例,如果遇到磁盘空间已满等情况获取失败的话,再以只读模式打开数据库,获取数据库实例并返回,然后为mDatabase赋值为最新打开的数据库实例。既然有可能调用到getWritableDatabase()方法,我们就要看一下了: public synchronized SQLiteDatabase getWritableDatabase() { if (mDatabase != null && mDatabase.isOpen() && !mDatabase.isReadOnly()) { // 如果mDatabase不为空已打开并且不是只读模式则返回该实例 return mDatabase; } if (mIsInitializing) { throw new IllegalStateException("getWritableDatabase called recursively"); } // If we have a read-only database open, someone could be using it // (though they shouldn't), which would cause a lock to be held on // the file, and our attempts to open the database read-write would // fail waiting for the file lock. To prevent that, we acquire the // lock on the read-only database, which shuts out other users. boolean success = false; SQLiteDatabase db = null; // 如果mDatabase不为空则加锁阻止其他的操作 if (mDatabase != null) mDatabase.lock(); try { mIsInitializing = true; if (mName == null) { db = SQLiteDatabase.create(null); } else { // 打开或创建数据库 db = mContext.openOrCreateDatabase(mName, 0, mFactory); } // 获取数据库版本(如果刚创建的数据库,版本为0) int version = db.getVersion(); // 比较版本(我们代码中的版本mNewVersion为1) if (version != mNewVersion) { db.beginTransaction();// 开始事务 try { if (version == 0) { // 执行我们的onCreate方法 onCreate(db); } else { // 如果我们应用升级了mNewVersion为2,而原版本为1则执行onUpgrade方法 onUpgrade(db, version, mNewVersion); } db.setVersion(mNewVersion);// 设置最新版本 db.setTransactionSuccessful();// 设置事务成功 } finally { db.endTransaction();// 结束事务 } } onOpen(db); success = true; return db;// 返回可读写模式的数据库实例 } finally { mIsInitializing = false; if (success) { // 打开成功 if (mDatabase != null) { // 如果mDatabase有值则先关闭 try { mDatabase.close(); } catch (Exception e) { } mDatabase.unlock();// 解锁 } mDatabase = db;// 赋值给mDatabase } else { // 打开失败的情况:解锁、关闭 if (mDatabase != null) mDatabase.unlock(); if (db != null) db.close(); } } } 大家可以看到,几个关键步骤是,首先判断mDatabase如果不为空已打开并不是只读模式则直接返回,否则如果mDatabase不为空则加锁,然后开始打开或创建数据库,比较版本,根据版本号来调用相应的方法,为数据库设置新版本号,最后释放旧的不为空的mDatabase并解锁,把新打开的数据库实例赋予mDatabase,并返回最新实例。 看完上面的过程之后,大家或许就清楚了许多,如果不是在遇到磁盘空间已满等情况,getReadableDatabase()一般都会返回和getWritableDatabase()一样的数据库实例,所以我们在DBManager构造方法中使用getWritableDatabase()获取整个应用所使用的数据库实例是可行的。当然如果你真的担心这种情况会发生,那么你可以先用getWritableDatabase()获取数据实例,如果遇到异常,再试图用getReadableDatabase()获取实例,当然这个时候你获取的实例只能读不能写了 最后,让我们看一下如何使用这些数据操作方法来显示数据,界面核心逻辑代码: public class SQLiteActivity extends Activity { public DiaryDao diaryDao; //因为getWritableDatabase内部调用了 mContext.openOrCreateDatabase(mName, 0, mFactory); //所以要确保context已初始化,我们可以把实例化Dao的步骤放在Activity的onCreate里 @Override protected void onCreate(Bundle savedInstanceState) { diaryDao = new DiaryDao(SQLiteActivity.this); initDatabase(); } class ViewOcl implements View.OnClickListener { @Override public void onClick(View v) { String strSQL; boolean flag; String message; switch (v.getId()) { case R.id.btnAdd: String title = txtTitle.getText().toString().trim(); String weather = txtWeather.getText().toString().trim();; String context = txtContext.getText().toString().trim();; String publish = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") .format(new Date()); // 动态组件SQL语句 strSQL = "insert into diary values(null,'" + title + "','" + weather + "','" + context + "','" + publish + "')"; flag = diaryDao.execOther(strSQL); //返回信息 message = flag?"添加成功":"添加失败"; Toast.makeText(getApplicationContext(), message, Toast.LENGTH_LONG).show(); break; case R.id.btnDelete: strSQL = "delete from diary where tid = 1"; flag = diaryDao.execOther(strSQL); //返回信息 message = flag?"删除成功":"删除失败"; Toast.makeText(getApplicationContext(), message, Toast.LENGTH_LONG).show(); break; case R.id.btnQuery: strSQL = "select * from diary order by publish desc"; String data = diaryDao.execQuery(strSQL); Toast.makeText(getApplicationContext(), data, Toast.LENGTH_LONG).show(); break; case R.id.btnUpdate: strSQL = "update diary set title = '测试标题1-1' where tid = 1"; flag = diaryDao.execOther(strSQL); //返回信息 message = flag?"更新成功":"更新失败"; Toast.makeText(getApplicationContext(), message, Toast.LENGTH_LONG).show(); break; } } } private void initDatabase() { // 创建数据库对象 SqliteDBHelper sqliteDBHelper = new SqliteDBHelper(SQLiteActivity.this); sqliteDBHelper.getWritableDatabase(); System.out.println("数据库创建成功"); } } Android sqlite3数据库管理工具 Android SDK的tools目录下提供了一个sqlite3.exe工具,这是一个简单的 sqlite数据库管理工具。开发者可以方便的使用其对sqlite数据库进行命令行的操作。程序运行生成的*.db文件一般位于"/data/data/项目名(包括所处包 名)/databases/*.db",因此要对数据库文件进行操作需要先找到数据库文件: 1、进入shell 命令 adb shell 2、找到数据库文件 #cd data/data #ls --列出所有项目 #cd project_name --进入所需项目名 #cd databases #ls --列出现寸的数据库文件 3、进入数据库 #sqlite3 test_db --进入所需数据库 会出现类似如下字样: SQLite version 3.6.22 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> 至此,可对数据库进行sql操作。 4、sqlite常用命令 >.databases --产看当前数据库 >.tables --查看当前数据库中的表 >.help --sqlite3帮助 >.schema --各个表的生成语句 大数据存储方式概述 随着信息社会的发展,越来越多的信息被数据化,尤其是伴随着Internet的发展,数据呈爆炸式增长。从存储服务的发展趋势来看,一方面,是对数据的存储量的需求越来越大,另一方面,是对数据的有效管理提出了更高的要求。首先是存储容量的急剧膨胀,从而对于存储服务器提出了更大的需求;其次是数据持续时间的增加。最后,对数据存储的管理提出了更高的要求。数据的多样化、地理上的分散性、对重要数据的保护等等都对数据管理提出了更高的要求。随着数字图书馆、电子商务、多媒体传输等用的不断发展,数据从GB、TB 到PB量级海量急速增长。存储产品已不再是附属于服务器的辅助设备,而成为互联网中最主要的花费所在。海量存储技术已成为继计算机浪潮和互联网浪潮之后的第三次浪潮,磁盘阵列与网络存储成为先锋。 一、海量数据存储简介 海量存储的含义在于,其在数据存储中的容量增长是没有止境的。因此,用户需要不断地扩张存储空间。但是,存储容量的增长往往同存储性能并不成正比。这也就造成了数据存储上的误区和障碍。海量存储技术的概念已经不仅仅是单台的存储设备。而多个存储设备的连接使得数据管理成为一大难题。因此,统一平台的数据管理产品近年来受到了广大用户的欢迎。这一类型产品能够整合不同平台的存储设备在一个单一的控制界面上,结合虚拟化软件对存储资源进行管理。这样的产品无疑简化了用户的管理。 数据容量的增长是无限的,如果只是一味的添加存储设备,那么无疑会大幅增加存储成本。因此,海量存储对于数据的精简也提出了要求。同时,不同应用对于存储容量的需求也有所不同,而应用所要求的存储空间往往并不能得到充分利用,这也造成了浪费。 针对以上的问题,重复数据删除和自动精简配置两项技术在近年来受到了广泛的关注和追捧。重复数据删除通过文件块级的比对,将重复的数据块删除而只留下单一实例。这一做法使得冗余的存储空间得到释放,从客观上增加了存储容量。 二、企业在处理海量数据存储中存在的问题 目前企业存储面临几个问题,一是存储数据的成本在不断地增加,如何削减开支节约成本以保证高可用性;二是数据存储容量爆炸性增长且难以预估;三是越来越复杂的环境使得存储的数据无法管理。企业信息架构如何适应现状去提供一个较为理想的解决方案,目前业界有几个发展方向。 1.存储虚拟化 对于存储面临的难题,业界采用的解决手段之一就是存储虚拟化。虚拟存储的概念实际上在早期的计算机虚拟存储器中就已经很好地得以体现,常说的网络存储虚拟化只不过是在更大规模范围内体现存储虚拟化的思想。该技术通过聚合多个存储设备的空间,灵活部署存储空间的分配,从而实现现有存储空间高利用率,避免了不必要的设备开支。 存储虚拟化的好处显而易见,可实现存储系统的整合,提高存储空间的利用率,简化系统的管理,保护原有投资等。越来越多的厂商正积极投身于存储虚拟化领域,比如数据复制、自动精简配置等技术也用到了虚拟化技术。虚拟化并不是一个单独的产品,而是存储系统的一项基本功能。它对于整合异构存储环境、降低系统整体拥有成本是十分有效的。在存储系统的各个层面和不同应用领域都广泛使用虚拟化这个概念。考虑整个存储层次大体分为应用、文件和块设备三个层次,相应的虚拟化技术也大致可以按这三个层次分类。 目前大部分设备提供商和服务提供商都在自己的产品中包含存储虚拟化技术,使得用户能够方便地使用。 2.容量扩展 目前而言,在发展趋势上,存储管理的重点已经从对存储资源的管理转变到对数据资源 Android数据存储五种方式总结 本文介绍Android平台进行数据存储的五大方式,分别如下: 1 使用SharedPreferences存储数据 2 文件存储数据 3 SQLite数据库存储数据 4 使用ContentProvider存储数据 5 网络存储数据 下面详细讲解这五种方式的特点 第一种:使用SharedPreferences存储数据 适用范围:保存少量的数据,且这些数据的格式非常简单:字符串型、基本类型的值。比如应用 程序的各种配置信息(如是否打开音效、是否使用震动效果、小游戏的玩家积分等),解锁口令密码等 核心原理:保存基于XML文件存储的key-value键值对数据,通常用来存储一些简单的配置信息。通过DDMS的File Explorer面板,展开文件浏览树,很明显SharedPreferences数据总是存储在/data/data/ https://www.sodocs.net/doc/e110858253.html, 数据存储的四种常见方式 数据存储,它的概念为数据在交流过程的情况下发生的临时数据以及加工的操作的进程里面要进行查找的讯息,一般的存储介质包含有磁盘以及磁带。数据存取的方法和数据文件组织紧紧的相连,它的最主要的就是创立记录逻辑和物理顺序的两者之间的互相对应的联系,进行存储地址的肯定,从而使得数据进行存取的速度得到提升。进行存储介质的方法因为使用的存储介质不一样采用的方法也不一样,当磁带上面的数据只是按照次序来进行存取的时候;在磁盘上面就能够根据使用的需求使用顺序或者是直接存取的方法。 ●在线存储 (Online storage):有时也称为二级存储。这种存储方式的好处是读写非常 方便迅捷,缺点是相对较贵并且容易因为误操作或者防病毒软件的误删除而使数据受到损害。这种存储方式提供最好的数据获取便利性,大磁盘阵列是其中最典型的代表之一。 ●脱机存储 (Offline storage):脱机存储用于永久或长期保存数据,而又不需要介质当 前在线或连接到存储系统上。这种存储方式指的是每次在读写数据时,必须人为的将存储介质放入存储系统。脱机存储的介质通常可以方便携带或转运,如磁带和移动硬盘。 ●近线存储 (Near-line storage):也称为三级存储。自动磁带库是一个典型代表。比起 在线存储,近线存储提供的数据获取便利性相对差一些,但是价格要便宜些。近线存储由于读取速度较慢,主要用于归档较不常用的数据。 ●异站保护 (Off-site vault):这种存储方式保证即使站内数据丢失,其他站点仍有数 据副本。为了防止可能影响到整个站点的问题,许多人选择将重要的数据发送到其他站点来作为灾难恢复计划。异站保护可防止由自然灾害、人为错误或系统崩溃造成的数据丢失。 Android中5种数据存储方式 1概述 SharedPreferences存储数据。 ContentProvider存储 文件存储 SQLlite存储 网络存储 Preference,File,DataBase这三种方式分别对应的目录是: ●/data/data/Package Name/Shared_Pref ●/data/data/Package Name/files ●/data/data/Package Name/database 关于这五种数据存储方式,根据实际情况选择最合适的,秉持最简单原则,也就是说能用简单的方式处理,就不要用复杂的方式。比如存储几个数据或简单对象,用SharedPreference也能做到,就没必要写个ContentProvider。 ●简单数据和配置信息,SharedPreference是首选; ●如果SharedPreferences不够用,那么就创建一个数据库; ●结构化数据,一定要创建数据库,虽然这稍显烦锁,但是好处无穷; ●文件就是用来存储文件(也即非配置信息或结构化数据),如文本文件,二进制文件,PC文件, 多媒体文件,下载的文件等等; ●尽量不要创建文件; ●如果创建文件,如果是私密文件或是重要文件,就存储在内部存储,否则放到外部存储。 2SharedPreferences存储数据 SharedPreferences 可以将数据保存到应用程序的私有存储区,这些存储区中的数据只能被写入这些数据的软件读取。 它的本质是基于XML文件存储key-value键值对数据,通常用来存储一些简单的配置信息。 其存储位置在/data/data/<包名>/shared_prefs 目录下。 使用SharedPreferences是有些限制的:只能在同一个包内使用,不能在不同的包之间使用。 例如:登录用户的用户名与密码。 步骤如下: (1)使用Activity类的getSharedPreference 方法获得SharePreferences对象。其中存储key-value 的文件名称由getSharedPreferences方法的第一个参数指定;第二个参数表示所创建的数据文件的访问权限(“MODE_WORLD_READABLE”表示其他用户有“读”的权限; “MODE_WORLD_WRITEABLE ” 表示其他用户有“写”权限;MODE_PRIVATE 和 MODE_APPEND创建的文件对其他用户都是不可访问的); (2)使用SharedPreferences 接口的edit 获得SharedPreferences.Editor对象; (3)通过Sharedreferences.Editor接口的putXxx方法保存key-value对。其中Xxx表示value 不同数据类型。例如,Boolean类型的value需要用putBoolean方法,字符串类型的value需要用putString方法; (4)通过Sharedreferences.Editor接口的commit方法保存key-value对。commit方法相当于数据库事务中的提交(commit)操作,只有在事务结束后进行提交,才会将数据真正保存在数据库中。保存key-value也是一样,在使用putXxx方法指定了key-value对后,必须调用commit方法才能将key-value对真正保存在相应的文件中。 几种常见网络存储技术的比较 一、直接附加存储(DAS 是指将存储设备直接连接服务器上使用。成本低,配置简单,和使用本机硬盘并无太大差别。DAS问题:(1服务器容易成为系统瓶颈;(2服务器发生故障,数据不可访问;(3对于存在多个服务器的系统来说,设备分散,不便管理。(4数据备份操作复杂。 二、网络附加存储(NAS NAS是一种带有瘦服务器的存储设备。NAS设备直接连接到TCP/IP网络上,网络服务器通过TCP/IP网络存取管理数据。由于NAS只需要在一个磁盘阵列柜外增加一套瘦服务器系统,对硬件要求很低,成本不高。NAS 主要问题是:(1由于存储数据通过普通数据网络传输,因此易受流量的影响。(2由于存储数据通过普通数据网络传输,因此容易产生数据泄漏等安全问题;(3存储只能以文件方式访问,而不能像普通文件系统一样直接访问物理数据块,因此会在某些情况下严重影响系统效率,比如大型数据库就不能使用NAS。 NAS(Network Attached Storage:网络附属存储是将分布独立的数据整合为数据中心,以便于访问的技术,也称为“网络存储器”。以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽、提高性能、降低成本。其成本远低于使用服务器存储,而效率却远远高于后者。NAS的存储以文件为单位,一般支持CIFS / HTTP / FTP等方式的访问。 NAS:NAS从结构上讲就是一台精简型的电脑,在架构上不像个人电脑那么复杂,在外观上就像家电产品,只需电源与简单的控制钮,。一般只具有网络接口。也有部分NAS产品需要与SAN产品连接,可能会有FC接口。NAS产品一般用系统软件。一个NAS系统包括处理器,文件服务管理模块和多个硬盘驱动器(用于数据的存储。NAS 可以应用在任何的网络环境当中。主服务器和客户端可以非常方便地 https://www.sodocs.net/doc/e110858253.html, 常见的几种数据存储方法 在数据恢复中,小编经常强调“数据覆盖”的问题,也就是数据丢失后,如果往丢失磁盘存入了新数据,那么就可能造成数据覆盖,影响后续的数据恢复进程。因此,也有很多人有疑问:“怎么才能知道新存入的数据是不是刚好覆盖到了丢失数据上面呢?”这个问题其实和我们磁盘的数据存储方法有关了。 我们平时用来保存数据的存储介质不外乎这几种:硬盘、存储卡(内存卡)、U盘、光盘。常见的数据存储方法主要有下面四种: 1、顺序存储方法 把逻辑上相邻的结点存储在物理位置上相邻的存储单元里,结点间的逻辑关系由存储单元的邻接关系来体现。由此得到的存储表示称为顺序存储结构,通常借助程序语言的数组描述。该方法主要应用于线性的数据结构。非线性的数据结构也可通过某种线性化的方法实现顺序存储。 简单来说,如果你的数据存储介质的存储方法是顺序存储,比如顺序是从前往后,那么数据丢失后,新存入的数据也是按照从前往后的顺序写入的。 2、链接存储方法 该方法不要求逻辑上相邻的结点在物理位置上亦相邻,结点间的逻辑关系由附加的指针字段表示。由此得到的存储表示称为链式存储结构,通常借助于程序语言的指针类型描述。 这种存储方法乍一看是没有顺序可言的,可以简单理解成数据呈点状存储在磁盘中。 3、索引存储方法 该方法通常在储存结点信息的同时,还建立附加的索引表。索引表由若干索引项组成。若每个结点在索引表中都有一个索引项,则该索引表称之为稠密索引。若一组结点在索引表中只对应一个索引项,则该索引表称为稀疏索引。索引项的一般形式是:(关键字、地址)。 关键字是能唯一标识一个结点的那些数据项。稠密索引中索引项的地址指示结点所在的存储位置;稀疏索引中索引项的地址指示一组结点的起始存储位置。 4、散列存储方法 该方法的基本思想是:根据结点的关键字直接计算出该结点的存储地址。 四种基本存储方法,既可单独使用,也可组合起来对数据结构进行存储映像。同一逻辑结构采用不同的存储方法,可以得到不同的存储结构。选择何种存储结构来表示相应的逻辑结构,视具体要求而定,主要考虑运算方便及算法的时空要求。 磁盘文件数据存储方式 在介绍各种操作文件方式之前,需要先介绍磁盘上文件数据的组织方式。 实际上,文件是在计算机内存中以二进制表示的数据. 在外部存储介质上的另一种存放形式。 文件通常分为二进制文件和文本文件。 根据数据的组织的形式,可分为 ASCII文件和二进制文件。 ASCII文件又称文本文件,它的每一个字节放一个ASCII代码,代表一个字符。二进制文件是把内存中的数据按其在内存中的存储形式原样输出到磁盘上存放。 如果有一个整数10000,在内存中占2个字节,如果按ASCII码形式输出,则占5个字节,而按二进制形式输出在磁盘上只占2个字节。 用ASCII码形式输出与字符一一对应,一个字节代表一个字符因而便于对字符进行逐个处理,也便于输出字符 。但一般占存储空间较多,而且要花费转换时间。 用二进制形式输出数值,可以节省外存空间和转换时间,但一个字节并不对应一个字符,不能直接输出字符 形式。 一般中间结果数据需要暂时保存在外存上,以后又需要输入到内存的,常用二进制文件保存。 ASCII形式 00110001 00110000 00110000 00110000 00110000 内存中的存储形式 00100111 00010000 二进制形式 00100111 00010000 比如在内存中数据 00110000 00111001 (十进制为12345) 在磁盘上可以以ASCII码存储为 00110001 00110010 00110011 00110100 00110101 '1' '2' '3' '4' '5' 二进制存储格式 00110000 00111001 字符,字节和编码 摘要:本文介绍了字符与编码的发展过程,相关概念的正确理解。举例说明了一些实际应用中,编码的实现方法。然后,本文讲述了通常对字符与编码的几种误解,由于这些误解而导致乱码产生的原因,以及消除乱码的办法。本文的内容涵盖了“中文问题”,“乱码问题”。 掌握编码问题的关键是正确地理解相关概念,编码所涉及的技术其实是很简单的。因此,阅读本文时需要慢读多想,多思考。 引言 “字符与编码”是一个被经常讨论的话题。即使这样,时常出现的乱码仍然困扰着大家。虽然我们有很多的办法可以用来消除乱码,但我们并不一定理解这些办法的内在原理。而有的乱码产生的原因,实际上由于底层代码本身有问题所导致的。因此,不仅是初学者会对字符编码感到模糊,有的底层开发人员同样对字符编码缺乏准确的理解。 1. 编码问题的由来,相关概念的理解 1.1 字符与编码的发展 从计算机对多国语言的支持角度看,大致可以分为三个阶段: 系统内码说明系统 阶段一ASCII 计算机刚开始只支持英语,其它语言不能 够在计算机上存储和显示。 英文 DOS 阶段二 ANSI编码 (本地化) 为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 '中' 在中文操作系 统中,使用 [0xD6,0xD0] 这两个字节存 储。 不同的国家和地区制定了不同的标准,由 此产生了 GB2312, BIG5, JIS 等各自的 编码标准。这些使用 2 个字节来代表一 个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编 码代表 GB2312 编码,在日文操作系统 下,ANSI 编码代表 JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在 国际间交流时,无法将属于两种语言的文 中文 DOS,中文 Windows 95/98, 日文 Windows 95/98 1、下列典型行业应用对存储的需求,正确的是( C ) A.WEB应用不包括对数据库的访问 B.WEB应用是大数据块的读取居多 C.邮件系统的数据特点介于数据库和普通文件二者之间,邮件用户等信息属于数据库操作,但是每个用户的邮件又是按照文件组织的 D.视频点播系统要求比较高的IOPS,但对存储带宽的稳定性要求不高 2、对于存储系统性能调优说法正确的是:( C ) A. 必须在线业务下进行调优 B. 存储系统的调优可以与主机单独进行,应为两者性能互不影响 C. 存储系统的性能调优属于系统性调优,需要了解客户IO模型、业务大小、服务器资 源利用和存储侧资源利用综合分析,对于存储侧重点关注RAID级别,分条深度, LUN映射给主机的分布情况等 D. 以上都不正确 3、不具备扩展性的存储架构有( A ) A. DAS B. NAS C. SAN D. IP SAN 4、DAS代表的意思是( D )direct access s A. 两个异步的存储 B. 数据归档软件 C. 连接一个可选的存储 D. 直连存储 5、哪种应用更适合采用大缓存块?( A ) A. 视频流媒体 B. 数据库 C. 文件系统 D. 数据仓库 6、衡量一个系统可靠性常见时间指标有哪些?( CD ) A. 可靠度 B. 有效率 C. 平均失效时间 D. 平均无故障时间 7、主机访问存储的主要模式包括( ABC ) A. NAS B. SAN C. DAS D. NFS 8、群集技术适用于以下场合:( ABCD ) A. 大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性 B. 应用规模的发展使单个服务器难以承担负载 C. 不断增长的需求需要硬件有灵活的可扩展性 D. 关键性的业务需要可靠的容错机制 9、常见数据访问的级别有( AD ) A.文件级(file level) B.异构级(NFS level) C.通用级(UFS level) D.块级(block level) 10、常用的存储设备介质包括( ABC ) A. 硬盘 B. 磁带 C. 光盘 D. 软盘 11、常用的存储设备包括( ABCD) A. 磁盘阵列 B. 磁带机 C. 磁带库 D. 虚拟磁带库 12、存储网络的类别包括( ABC ) A. DAS B. NAS C. SAN D. Ethernet 13、常用数据备份方式包括( ACD ) A. D2D B. D2T2D C. D2D2T D. D2T 14、为了解决同位(为)检查码技术的缺陷而产生的一种内存纠错技术是( D ) A. Chipkill B. 热插拔 C. S.M.A.R.T D. Advanced ECC Memory 15、以下不是智能网卡的主要特点是( D ) A. 节能降耗 B. 降低TCO C. 数据更安全 D. 可作为主机总线适配器HBA使用 数据存储的四种常见方式 This model paper was revised by the Standardization Office on December 10, 2020 数据存储的四种常见方式 数据存储,它的概念为数据在交流过程的情况下发生的临时数据以及加工的操作的进程里面要进行查找的讯息,一般的存储介质包含有磁盘以及磁带。数据存取的方法和数据文件组织紧紧的相连,它的最主要的就是创立记录逻辑和物理顺序的两者之间的互相对应的联系,进行存储地址的肯定,从而使得数据进行存取的速度得到提升。进行存储介质的方法因为使用的存储介质不一样采用的方法也不一样,当磁带上面的数据只是按照次序来进行存取的时候;在磁盘上面就能够根据使用的需求使用顺序或者是直接存取的方法。 在线存储 (Online storage):有时也称为二级存储。这种存储方式的好处是读写非常方便迅捷,缺点是相对较贵并且容易因为误操作或者防病毒软件的误删除而使数据受到损害。这种存储方式提供最好的数据获取便利性,大磁盘阵列是其中最典型的代表之一。 脱机存储 (Offline storage):脱机存储用于永久或长期保存数据,而又不需要介质当前在线或连接到存储系统上。这种存储方式指的是每次在读写数据时,必须人为的将存储介质放入存储系统。脱机存储的介质通常可以方便携带或转运,如磁带和移动硬盘。 近线存储 (Near-line storage):也称为三级存储。自动磁带库是一个典型代表。比起在线存储,近线存储提供的数据获取便利性相对差一些,但是价格要便宜些。近线存储由于读取速度较慢,主要用于归档较不常用的数据。 异站保护 (Off-site vault):这种存储方式保证即使站内数据丢失,其他站点仍有数据副本。为了防止可能影响到整个站点的问题,许多人选择将重要的数据发送到其他站点来作为灾难恢复计划。异站保护可防止由自然灾害、人为错误或系统崩溃造成的数据丢失。 常见存储类型 对于企业存储设备而言,根据其实现方式主要划分为DAS、SAN和NAS三种,分别针对不同的应用环境,提供了不同解决方案。(区别见图2) 图1三种存储技术比较 DAS DAS(Direct Attach Storage):是直接连接于主机服务器的一种储存方式,每一台主机服务器有独立的储存设备,每台主机服务器的储存设备无法互通,需要跨主机存取资料时,必须经过相对复杂的设定,若主机服务器分属不同的操作系统,要存取彼此的资料,更是复杂,有些系统甚至不能存取。通常用在单一网络环境下且数据交换量不大,性能要求不高的环境下,可以说是一种应用较为早的技术实现。 SAN SAN(Storage Area Network):是一种用高速(光纤)网络联接专业主机服务器的一种储存方式,此系统会位于主机群的后端,它使用高速I/O 联结方式, 如SCSI, ESCON 及 Fibre- Channels。一般而言,SAN应用在对网络速度要求高、对数据的可靠性和安全性要求高、对数据共享的性能要求高的应用环境中,特点是代价高,性能好。例如电信、银行的大数据量关键应用。 NAS NAS(Network Attached Storage):是一套网络储存设备,通常是直接连在网络上并提供资料存取服务,一套 NAS 储存设备就如同一个提供数据文件服务的系统,特点是性价比高。例如教育、政府、企业等数据存储应用。 三种技术比较 以下,通过表格的方式对于三种存储技术进行一个简单的比较。 表格 1 三种技术的比较 录像存储 录像存储是指将监控图像录制下来,并以文件形式存储在存储设备中,并可在以后随时被读出回放。 存储的实现有多种模式,包括DAS(直连存储)、SAN(存储区域网)和NAS(网络存储)等。DAS就是普通计算机系统最常用的存储方式,即将存储介质(硬盘)直接挂接在CPU的直接访问总线上,优点是访问效率高,缺点是占用系统总线资源、挂接数量有限,一般适用于低端PC系统。SAN是将存储和传统的计算机系统分开,系统对存储的访问通过专用的存储网络来访问,对存储的管理可交付与存储网络来管理,优点是高效的存储管理、存储升级容易,而缺点则是系统较大,成本过高,适用于高端设备。NAS则充分利用系统原有的网络接口,对存储的访问是通过通用网络接口,访问通过高层接口实现,同时设备可专注与存储的管理,优点是系统简单、兼容现有系统、扩容方便,缺点则是效率相对比较低。 典型的传统数字硬盘录像机设备一般都采用DAS方式,即自身包含若干硬盘,录像数据进行压缩编码后直接存储在本地硬盘中,回放也从本地硬盘中读出。网络功能只是个附加的功能,主要面向远程终端实时监控本地图像和回放本地录像。在系统比较大时,这种方式必然是分布式存储的,给系统管理带来了麻烦。数字硬盘录像机的发展将使网络成为中心,而规模的增大使得分布式存储的缺点更加显著。采用NAS作为录像的存储设备,解决了传统数字硬盘录像机所限制的这些问题,作为下一代数字录像系统,其优势表现在: ●优良的设备环境:由于硬盘的不稳定性,需要一个更好的工作环境来延 长硬盘的寿命和减少存储的不可用时间。NAS作为专业的存储设备,针 对多硬盘环境作了优化设计,让硬盘工作的更稳定、更可靠。 ●专业的存储管理:有效的存储管理在数据量上升时更加显得重要,数据 的安全性与冗余性将更受关注。NAS通过专业软件对大容量存储进行管 理,增加安全机制及冗余管理,使得存放的数据更便捷、更放心。 ●轻松的容量扩张:对容量的需求日益增加的今日,更加看重存储容量的 可扩张性。NAS的容量扩张基本上是Plug&Play的模式,方便用户升级。 数据存储的四种常见方式精编W O R D版 IBM system office room 【A0816H-A0912AAAHH-GX8Q8-GNTHHJ8】 数据存储的四种常见方式 数据存储,它的概念为数据在交流过程的情况下发生的临时数据以及加工的操作的进程里面要进行查找的讯息,一般的存储介质包含有磁盘以及磁带。数据存取的方法和数据文件组织紧紧的相连,它的最主要的就是创立记录逻辑和物理顺序的两者之间的互相对应的联系,进行存储地址的肯定,从而使得数据进行存取的速度得到提升。进行存储介质的方法因为使用的存储介质不一样采用的方法也不一样,当磁带上面的数据只是按照次序来进行存取的时候;在磁盘上面就能够根据使用的需求使用顺序或者是直接存取的方法。 在线存储(Online storage):有时也称为二级存储。这种存储方式的好处是读写非常方便迅捷,缺点是相对较贵并且容易因为误操作或者防病毒软件的误删除而使数据受到损害。这种存储方式提供最好的数据获取便利性,大磁盘阵列是其中最典型的代表之一。 脱机存储(Offline storage):脱机存储用于永久或长期保存数据,而又不需要介质当前在线或连接到存储系统上。这种存储方式指的是每次在读写数据时,必须人为的将存储介质放入存储系统。脱机存储的介质通常可以方便携带或转运,如磁带和移动硬盘。 近线存储(Near-line storage):也称为三级存储。自动磁带库是一个典型代表。比起在线存储,近线存储提供的数据获取便利性相对差一些,但是价格要便宜些。近线存储由于读取速度较慢,主要用于归档较不常用的数据。 异站保护(Off-site vault):这种存储方式保证即使站内数据丢失,其他站点仍有数据副本。为了防止可能影响到整个站点的问题,许多人选择将重要的数据发送到其他站点 五种常用的数据加密方法.txt22真诚是美酒,年份越久越醇香浓型;真诚是焰火,在高处绽放才愈是美丽;真诚是鲜花,送之于人手有余香。一颗孤独的心需要爱的滋润;一颗冰冷的心需要友谊的温暖;一颗绝望的心需要力量的托慰;一颗苍白的心需要真诚的帮助;一颗充满戒备关闭的门是多么需要真诚这一把钥匙打开呀!每台电脑的硬盘中都会有一些不适合公开的隐私或机密文件,如个人照片或客户资料之类的东西。在上网的时候,这些信息很容易被黑客窃取并非法利用。解决这个问题的根本办法就是对重要文件加密,下面介绍五种常见的加密办法。加密方法一: 利用组策略工具,把存放隐私资料的硬盘分区设置为不可访问。具体方法:首先在开始菜单中选择“运行”,输入 gpedit.msc,回车,打开组策略配置窗口。选择“用户配置”->“管理模板”->“Windows 资源管理器”,双击右边的“防止从“我的电脑”访问驱动器”,选择“已启用”,然后在“选择下列组合中的一个”的下拉组合框中选择你希望限制的驱动器,点击确定就可以了。 这时,如果你双击试图打开被限制的驱动器,将会出现错误对话框,提示“本次操作由于这台计算机的限制而被取消。请与您的系统管理员联系。”。这样就可以防止大部分黑客程序和病毒侵犯你的隐私了。绝大多数磁盘加密软件的功能都是利用这个小技巧实现的。这种加密方法比较实用,但是其缺点在于安全系数很低。厉害一点的电脑高手或者病毒程序通常都知道怎么修改组策略,他们也可以把用户设置的组策略限制取消掉。因此这种加密方法不太适合对保密强度要求较高的用户。对于一般的用户,这种加密方法还是有用的。 加密方法二: 利用注册表中的设置,把某些驱动器设置为隐藏。隐藏驱动器方法如下: 在注册表HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Policies\E xplorer中新建一个DWORD值,命名为NoDrives,并为它赋上相应的值。例如想隐藏驱动器C,就赋上十进制的4(注意一定要在赋值对话框中设置为十进制的4)。如果我们新建的NoDrives想隐藏A、B、C三个驱动器,那么只需要将A、B、C 驱动器所对应的DWORD值加起来就可以了。同样的,如果我们需要隐藏D、F、G三个驱动器,那么NoDrives就应该赋值为8+32+64=104。怎么样,应该明白了如何隐藏对应的驱动器吧。目前大部分磁盘隐藏软件的功能都是利用这个小技巧实现的。隐藏之后,WIndows下面就看不见这个驱动器了,就不用担心别人偷窥你的隐私了。 但这仅仅是一种只能防君子,不能防小人的加密方法。因为一个电脑高手很可能知道这个技巧,病毒就更不用说了,病毒编写者肯定也知道这个技巧。只要把注册表改回来,隐藏的驱动器就又回来了。虽然加密强度低,但如果只是对付一下自己的小孩和其他的菜鸟,这种方法也足够了。 加密方法三: 网络上介绍加密方法一和加密方法二的知识性文章已经很多,已经为大家所熟悉了。但是加密方法三却较少有人知道。专家就在这里告诉大家一个秘密:利用Windows自带的“磁盘管理”组件也可以实现硬盘隐藏! 具体操作步骤如下:右键“我的电脑”->“管理”,打开“计算机管理”配置窗口。选择“存储”->“磁盘管理”,选定你希望隐藏的驱动器,右键选择“更改驱动器名和路径”,然后在出现的对话框中选择“删除”即可。很多用户在这里不 数据存储的四种常见方式 数据存储,它的概念为数据在交流过程的情况下发生的临时数据以及加工的操作的进程里面要进行查找的讯息,一般的存储介质包含有磁盘以及磁带。数据存取的方法和数据文件组织紧紧的相连,它的最主要的就是创立记录逻辑和物理顺序的两者之间的互相对应的联系,进行存储地址的肯定,从而使得数据进行存取的速度得到提升。进行存储介质的方法因为使用的存储介质不一样采用的方法也不一样,当磁带上面的数据只是按照次序来进行存取的时候;在磁盘上面就能够根据使用的需求使用顺序或者是直接存取的方法。 ●在线存储(Online storage):有时也称为二级存储。这种存储方式的好处是读写非常方 便迅捷,缺点是相对较贵并且容易因为误操作或者防病毒软件的误删除而使数据受到损害。这种存储方式提供最好的数据获取便利性,大磁盘阵列是其中最典型的代表之一。 ●脱机存储(Offline storage):脱机存储用于永久或长期保存数据,而又不需要介质当前 在线或连接到存储系统上。这种存储方式指的是每次在读写数据时,必须人为的将存储介质放入存储系统。脱机存储的介质通常可以方便携带或转运,如磁带和移动硬盘。 ●近线存储(Near-line storage):也称为三级存储。自动磁带库是一个典型代表。比起在 线存储,近线存储提供的数据获取便利性相对差一些,但是价格要便宜些。近线存储由于读取速度较慢,主要用于归档较不常用的数据。 ●异站保护(Off-site vault):这种存储方式保证即使站内数据丢失,其他站点仍有数据副 本。为了防止可能影响到整个站点的问题,许多人选择将重要的数据发送到其他站点来作为灾难恢复计划。异站保护可防止由自然灾害、人为错误或系统崩溃造成的数据丢失。 数据存放问题非常重要,然而在实际应用中却是错事连连。经常会出现掉盘、卷锁死等诸多问题,严重影响了整体系统的正常使用,所以数据专用存储已经成为市场上最关注的安防产品之一。 数据传统存储方式 在目前的数字领域中,最常用的无非是如下四种存储方式:硬盘、DAS、NAS、SAN。 1.硬盘 无论是DVR、DVS后挂硬盘还是服务器后面直接连接扩展柜的方式,都是采用硬盘进行存储方式。应该说采用硬盘方式进行的存储,并不能算作严格意义上的存储系统。其原因有以下几点: 第一,其一般不具备RAID系统,对于硬盘上的数据没有进行冗余保护,即使有也是通过主机端的RAID卡或者软RAID实现。严重的影响整体性能; 第二,其扩展能力极为有限,当录像时间超过60天时,往往不能满足录像时间的存储需求; 第三,无法实现数据集中存储,后期维护成本较高,特别是在DVS后挂硬盘的方式,其维护成本往往在一年之内就超过了购置成本。 应该说硬盘存储方式不适合大型数字视频监控系统的应用。特别是需要长时间录像的数字视频监控系统。一般这种方式都是与其它存储方式并存于同一系统中,作为其他存储方式的缓冲或应急替代。 2.DAS(直接附加存储) DAS(Direct Attached Storage),全称为直接连接附加存储,采用DAS的方式可以很简单的实现平台的容量扩容,同时对数据可以提供多种RAlD级别的保护。 采用DAS方式时。在视频存储单元上部署相关的HBA卡。用于跟后端的存储设备建立数据通道。前端的视频存储单元可以是DVR,也可以是视频存储服务器。其通道可以采用光纤、IP网线、SAS线缆甚至于USB、1394线等。 采用DAS方式并不能同时支持很多视频存储服务单元同时接入,而且其扩容能力严重依赖所选择的存储设备自身的扩容能力。所以在大型数字视频监控系统中,应用DAS存储方式将造成系统维护难度的极大提升。 正是由于DAS存储的这些特点,所以这种存储方式一般应用于对于DVR的扩容或者小型数字视频监控项目中。 数据存储的几种方式: 总体的来讲,数据存储方式有三种:一个是文件,一个是数据库,另一个则是网络。其中文件和数据库可能用的稍多一些,文件用起来较为方便,程序可以自己定义格式;数据库用起稍烦锁一些,但它有它的优点,比如在海量数据时性能优越,有查询功能,可以加密,可以加锁,可以跨应用,跨平台等等;网络,则用于比较重要的事情,比如科研,勘探,航空等实时采集到的数据需要马上通过网络传输到数据处理中心进行存储并进行处理。对于Android平台来讲,它的存储方式也不外乎这几种,按方式总体来分,也是文件,数据库和网络。但从开发者的角度来讲它可以分为以下五种方式: 1.SharedPreferences共享偏好2.Internal Storage内部存储空间3.External Storage外部存储空间4.SQLite Database数据库5.Internet网络这几种方式各自有各自的优点和缺点,要根据不同的实际情况来选择,而无法给出统一的标准。下面就各种方式谈谈它们的优缺点,以及最合适的使用情况:1.Shared Preferences共享偏好SharedPreferences是用来存储一些Key/Value类似的成对的基本数据类型,注意,它只能存储基本数据类型,也即int, long, boolean, String, float。事实上它完全相当于一个HashMap,唯一不同的就是HashMap中的Value可以是任何对象,而SharedPreferences中的值只能存储基本数据类型(primitive types)。对于它的使用方法,可以参考Android Developer Guide,这里不重复。如此来看,最适合SharedPreferences的地方就是保存配置信息,因为很多配置信息都是Key/Value。事实上,在Android当中SharedPreferences使用最多的地方也是用来保存配置(Settings)信息,系统中的Settings中这样,各个应用中的Settings也是这样。并且,Android中为了方便的使用SharedPreferences 保存配置信息,它来专门有PreferenceActivity用来封装。也就是说如果你想在应用程序中创建配置(Settings),你可以直接使用PreferenceActivity和一些相关的专门为Preference封装的组件,而不用再直接去创建,读取和保存SharedPreference,Framework中的这些组件会为你做这些事。再谈谈一些使用SharedPreference时的技巧,它只能保存基本数据类型,但假如我想保存一个数组,怎么办?可以把数据进行处理,把它转化成一个String,取出的时候再还原就好了;再如,如想保存一个对象,怎么办,同样,可以把对象序列化成为字符序列,或转成String(Object.toString()),或是把它的HashCode(Object.hashCode())当成Value 保存进去。总之,SharedPreferences使用起来十分的方便,可以灵活应用,因为它简单方便,所以能用它就尽量不要用文件或是数据库。 1.Internal Storage内部存储空间所谓的内部存储与外部存储,是指是否是手机内置。手机内置的存储空间,称为内部存储,它是手机一旦出厂就无法改变,它也是手机的硬件指标之一,通常来讲手机内置存储空间越大意味着手机价格会越贵(很多地方把它称为手机内存,但我们做软件的知道,这并不准确,内存是指手机运行时存储程序,数据和指令的地方;这里应该是手机内部存储的简称为内存,而并非严格意义上的内存)。内部存储空间十分有限,因而显得可贵,所以我们要尽可能避免使用;另外,它也是系统本身和系统应用程序主要的数据存储所在地,一旦内部存储空间耗尽,手机也就无法使用了。所以对于内部存储空间,我们要尽量避免使用。上面所谈到的Shared Preferences和下面要谈到的SQLite数据库也都是存储在内部存储空间上的。Android本身来讲是一个Linux操作系统,所以它的内部存储空间,对于应用程序和用户来讲就是“/data/data"目录。它与其他的(外部的存储)相比有着比较稳定,存储方便,操作简单,更加安全(因为可以控制访问权限)等优点。而它唯一的缺点就是它比较有限,比较可贵。虽然,可以非常容易的知道程序本身的数据所在路径,所有的应用程序的数据路径都是“/data/data/app-package-name/”,所有的程序用到的数据,比如libs库,SharedPreferences 数据存储的四种常见方 式 公司标准化编码 [QQX96QT-XQQB89Q8-NQQJ6Q8-MQM9N] 数据存储的四种常见方式 数据存储,它的概念为数据在交流过程的情况下发生的临时数据以及加工的操作的进程里面要进行查找的讯息,一般的存储介质包含有磁盘以及磁带。数据存取的方法和数据文件组织紧紧的相连,它的最主要的就是创立记录逻辑和物理顺序的两者之间的互相对应的联系,进行存储地址的肯定,从而使得数据进行存取的速度得到提升。进行存储介质的方法因为使用的存储介质不一样采用的方法也不一样,当磁带上面的数据只是按照次序来进行存取的时候;在磁盘上面就能够根据使用的需求使用顺序或者是直接存取的方法。 在线存储 (Online storage):有时也称为二级存储。这种存储方式的好处是读写非常方便迅捷,缺点是相对较贵并且容易因为误操作或者防病毒软件的误删除而使数据受到损害。这种存储方式提供最好的数据获取便利性,大磁盘阵列是其中最典型的代表之一。 脱机存储 (Offline storage):脱机存储用于永久或长期保存数据,而又不需要介质当前在线或连接到存储系统上。这种存储方式指的是每次在读写数据时,必须人为的将存储介质放入存储系统。脱机存储的介质通常可以方便携带或转运,如磁带和移动硬盘。 近线存储 (Near-line storage):也称为三级存储。自动磁带库是一个典型代表。比起在线存储,近线存储提供的数据获取便利性相对差一些,但是价格要便宜些。近线存储由于读取速度较慢,主要用于归档较不常用的数据。 异站保护 (Off-site vault):这种存储方式保证即使站内数据丢失,其他站点仍有数据副本。为了防止可能影响到整个站点的问题,许多人选择将重要的数据发送到其他站点来作为灾难恢复计划。异站保护可防止由自然灾害、人为错误或系统崩溃造成的数据丢失。大数据存储方式概述
Android数据存储五种方式总结(DOC)
数据存储的四种常见方式
Android中5种数据存储方式
几种常见网络存储技术的比较(精)
常见的几种数据存储方法
磁盘文件数据存储方式
网络存储试题及答案..
数据存储的四种常见方式
存储类型分类资料
数据存储的四种常见方式精编WORD版
五种常用的数据加密方法
数据存储的四种常见方式
四大传统存储方式利弊一览
数据存储方式
数据存储的四种常见方式