5分钟速学stata面板数据回归(初学者超实用!)
5分钟速学stata面板数据回归(超实用!)
第一步:编辑数据。
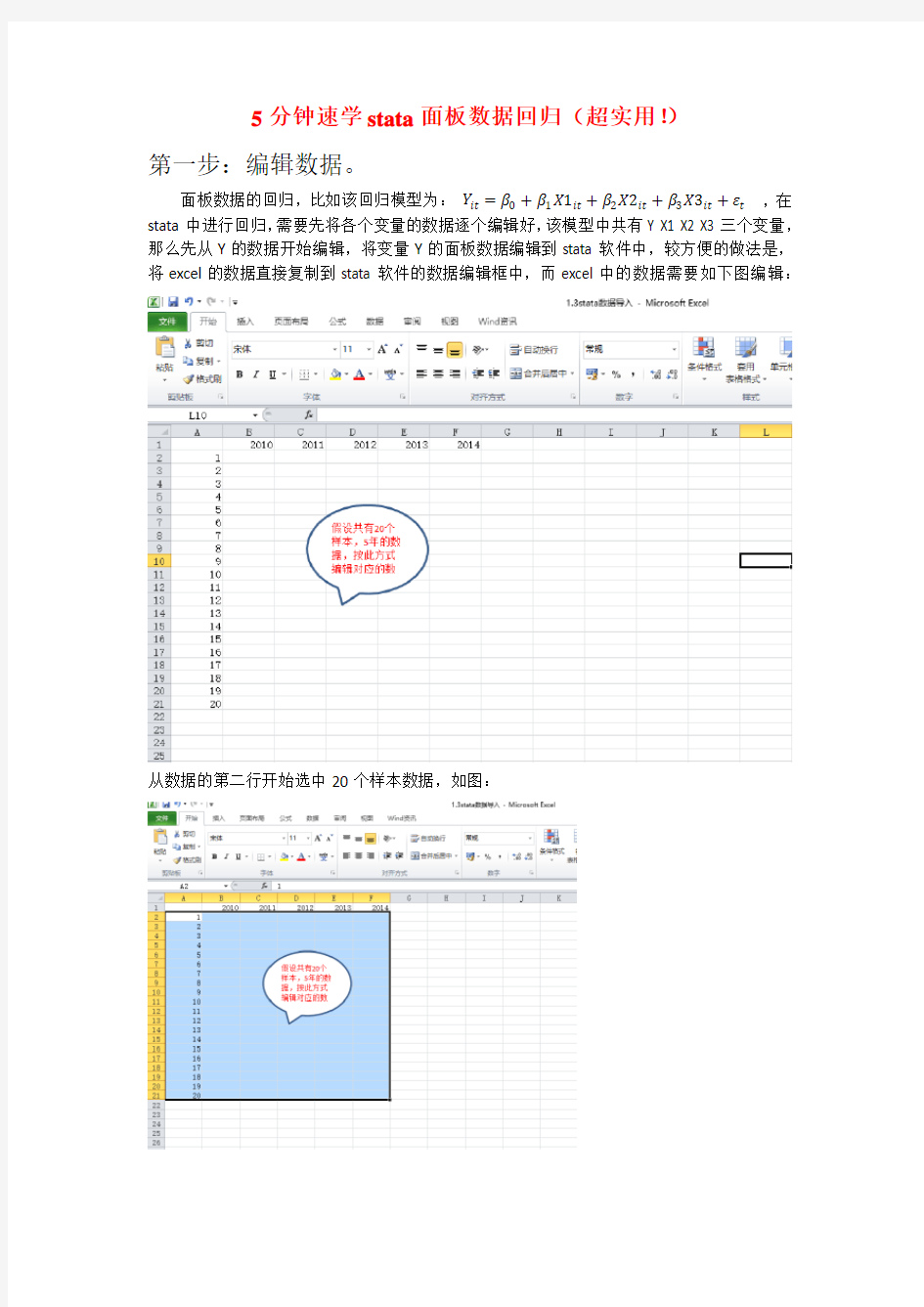
面板数据的回归,比如该回归模型为:Y it=β0+β1X1it+β2X2it+β3X3it+εt,在stata中进行回归,需要先将各个变量的数据逐个编辑好,该模型中共有Y X1 X2 X3三个变量,那么先从Y的数据开始编辑,将变量Y的面板数据编辑到stata软件中,较方便的做法是,将excel的数据直接复制到stata软件的数据编辑框中,而excel中的数据需要如下图编辑:
从数据的第二行开始选中20个样本数据,如图:
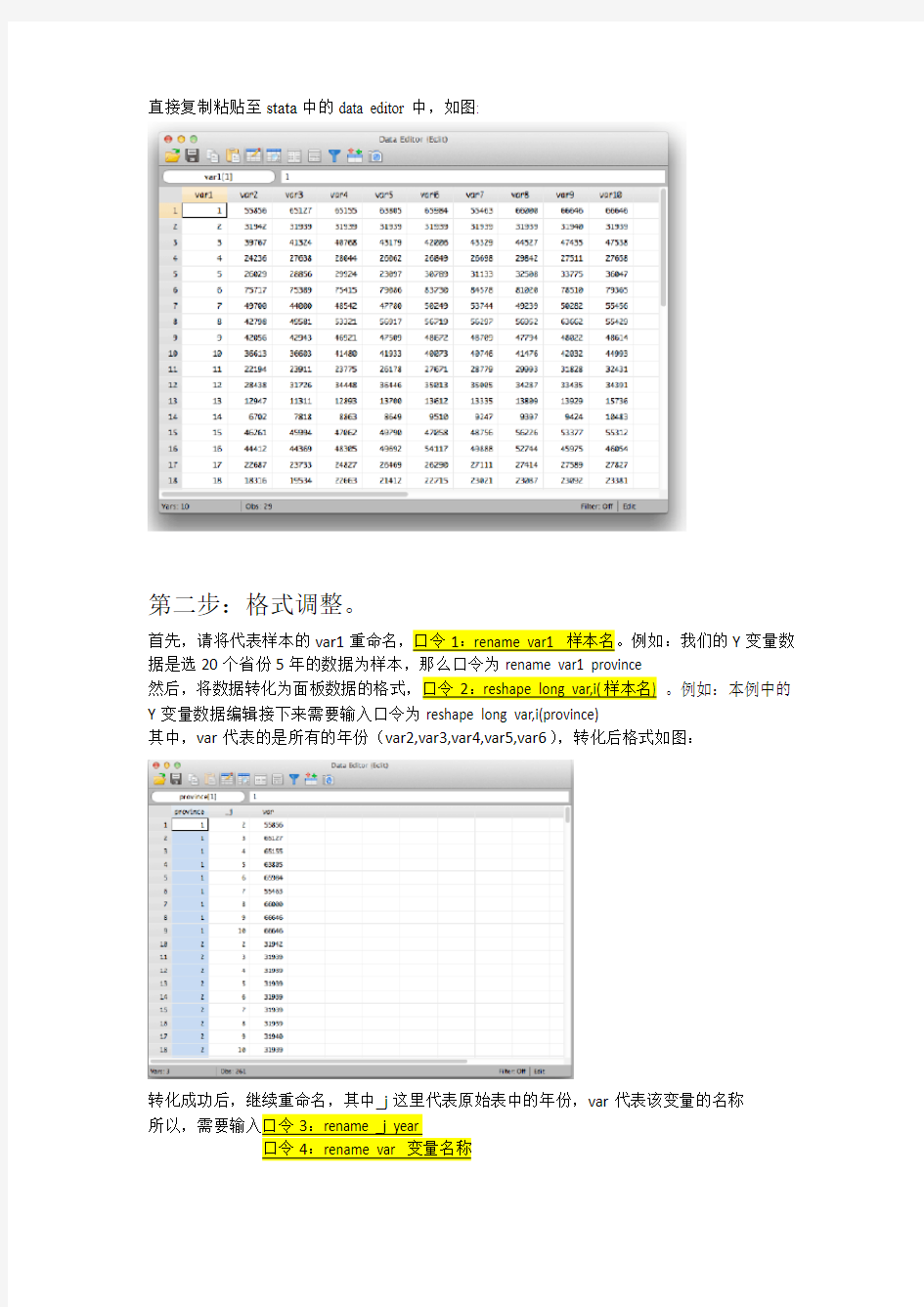
直接复制粘贴至stata中的data editor中,如图:
第二步:格式调整。
首先,请将代表样本的var1Y变量数据是选20个省份5年的数据为样本,那么口令为rename var1 province
。例如:本例中的Y变量数据编辑接下来需要输入口令为reshape long var,i(province)
其中,var代表的是所有的年份(var2,var3,var4,var5,var6),转化后格式如图:
转化成功后,继续重命名,其中_j这里代表原始表中的年份,var代表该变量的名称
例如,我们编辑的是Y变量的数据,所以口令3和口令4的输入如下:
口令3:rename _j year
口令4:rename var taxi (注:taxi就是Y变量,我们用taxi表示Y)
命名完,数据编辑框如下图所示。
第三步:排序。
例如,本例中的Y变量(taxi),是20个省份和5年的面板数据,
那么口令4为sort province year
(虽意思是将province按升序排列,然后再根据排好的province数列排year这一列升序排列。然很多时候在执行sort之前,数据已经符合排序要求了,但为以防万一,请务必执行此操作)
第三步:保存。
按下图中圈红的保存键,保存变量Y(即taxi)的数据。
第四步:重置。
至此,变量Y的数据导入完成。接下来将stata
此时,数据编辑框空白,接下来就可以输入X1的数据,方法与变量Y的数据输入完全一样。
第五步:合并数据。
把所有变量都导入之后,要进行回归,就需要先将所有变量合并起来。
首先确定stata重置了(即输入口令clear),然后在data editor中打开因变量Y的数据框,接下来要做的就是把X1,X2,X3等自变量逐个合并到Y中。
(文件路径可以往前面保存的找,前面所有的变量在导入数据最后一步保存时,会有该变量保存的文件路径,例如:E:\1.毕业论文\分省数据\stata文件\X1.dta)
合并数据也是一个变量一个变量逐个合并,首先合并X1变量的话,口令为merge 1:1 province year using E:\1.毕业论文\分省数据\stata文件\X1.dta
意思是将X1的数据添加到Y_merge
_merge
province year
这样就把X1合并入Y中,且已排序好,接着对X2,X3等变量如法炮制反复输入,直至自变量输入结束后保存。接下来就可以进行回归了。
第六步:回归。
,然后可以分别进行固定效应回归和随机效应回归。
例如本例的因变量为Y自变量为X1 X2 X3,则固定效应回归口令:xtreg Y X1 X2 X3,fe
例如本例的因变量为Y自变量为X1 X2 X3,则随机效应回归口令:xtreg Y X1 X2 X3,re
第七步:检验。
至此,stata面板数据回归全部结束。
STATA面板数据模型操作命令要点
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令 εαβit ++=x y it i it 固定效应模型 μβit +=x y it it ε αμit +=it it 随机效应模型 (一)数据处理 输入数据 ●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构 ●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析) ●gen lag_y=L.y /////// 产生一个滞后一期的新变量
gen F_y=F.y /////// 产生一个超前项的新变量 gen D_y=D.y /////// 产生一个一阶差分的新变量 gen D2_y=D2.y /////// 产生一个二阶差分的新变量 (二)模型的筛选和检验 ●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe 对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。 ●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量) (原假设:使用OLS混合模型) ●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0
可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。可见,随机效应模型也优于混合OLS模型。 ●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验) 原假设:使用随机效应模型(个体效应与解释变量无关) 通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下: Step1:估计固定效应模型,存储估计结果 Step2:估计随机效应模型,存储估计结果 Step3:进行Hausman检验 ●qui xtreg sq cpi unem g se5 ln,fe est store fe qui xtreg sq cpi unem g se5 ln,re est store re hausman fe (或者更优的是hausman fe,sigmamore/ sigmaless) 可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。此时,需要采用工具变量法和是使用固定效应模型。
5分钟速学stata面板数据回归(初学者超实用!)
5分钟速学stata面板数据回归(超实用!) 第一步:编辑数据。 面板数据的回归,比如该回归模型为:Y it=β0+β1X1it+β2X2it+β3X3it+εt,在stata中进行回归,需要先将各个变量的数据逐个编辑好,该模型中共有Y X1 X2 X3三个变量,那么先从Y的数据开始编辑,将变量Y的面板数据编辑到stata软件中,较方便的做法是,将excel的数据直接复制到stata软件的数据编辑框中,而excel中的数据需要如下图编辑: 从数据的第二行开始选中20个样本数据,如图:
直接复制粘贴至stata中的data editor中,如图: 第二步:格式调整。 首先,请将代表样本的var1Y变量数据是选20个省份5年的数据为样本,那么口令为rename var1 province 。例如:本例中的Y变量数据编辑接下来需要输入口令为reshape long var,i(province) 其中,var代表的是所有的年份(var2,var3,var4,var5,var6),转化后格式如图: 转化成功后,继续重命名,其中_j这里代表原始表中的年份,var代表该变量的名称
例如,我们编辑的是Y变量的数据,所以口令3和口令4的输入如下: 口令3:rename _j year 口令4:rename var taxi (注:taxi就是Y变量,我们用taxi表示Y) 命名完,数据编辑框如下图所示。 第三步:排序。 例如,本例中的Y变量(taxi),是20个省份和5年的面板数据, 那么口令4为sort province year (虽意思是将province按升序排列,然后再根据排好的province数列排year这一列升序排列。然很多时候在执行sort之前,数据已经符合排序要求了,但为以防万一,请务必执行此操作) 第三步:保存。
stata处理面板数据及修正命令集合
步骤一:导入数据 原始表如下, 数据请以时间(1998,1999,2000,2001??)为横轴,样本名(北京,天津,河北??)为纵轴 将中文地名替换为数字。 注意:表中不能有中文字符,否则会出现错误。面板数据中不能有空值。 去除年份的一行,将其余部分复制到stata的data editor中,或保存为csv格式。 打开stata,调用数据。 方法一:直接复制到data editor中。 方法二:使用口令:insheet using 文件路径 调用例如:insheet using C:\STUDY\paper\taxi.csv 其中csv格式可用excel的“另存为”导出 步骤二:调整格式 首先请将代表样本的var1重命名 口令:rename var1 样本名 例如:rename var1 province 也可直接在var1处双击,在弹出的窗口中修改: 接下来将数据转化为面板数据的格式 口令:reshape long var, i(样本名) 例如:reshape long var, i(province) 其中var代表的是所有的年份(var2,var3,var4??) 转化成功后继续重命名,其中_j 这里代表原始表中的年份,var代表该变量的名称 口令例如: rename _j year rename var taxi 也可直接在需要修改的名称处双击,在弹出的窗口中修改 步骤三:排序 口令:sort 变量名 例如:sort province year 意思为将province按升序排列,然后再根据排好的province数列排year这一列 最后,保存。 至此,一个变量的前期数据处理就完成了,请如法炮制的处理所有的变量,也就是说每个变量都做一个dta文件。在处理新变量前请使用 口令:clear 将stata重置 步骤四:合并数据 任意打开一个处理过的变量的dta文件作为基础表(推荐使用因变量的dta文件,这里使用
(完整版)Stata门限模型的操作和结果详细解读
一、门限面板模型概览 如果你不愿意看下面一堆堆的文字,更不想看计量模型的估计和检验原理,那就去《数量经济技术经济研究》上,找一篇标题带有“双门槛(或者双门限)”的文章,浏览一遍,看看文章计量部分列示的统计量和检验结果。这样,在软件操作时,你就知道每一步得到的结果有什么意义,怎么解释了,起码心里会有点印象。 一般情况下,一个研究生花费在研究上的时间越多,他的成果越丰富,也就是说,研究成果和研究时间存在某种正向关联。但是,这种关联是线性的吗?在最初阶段,他可能看了两三年的文献,也没有写出一篇优秀的文章,但是一旦过了这个基础期,他的能量和成果将如火山爆发一样喷涌出来,此时,他投入少量的时间,就能产出大量优质文章。再过几年,他可能会进入另外一种境界,虽然比以前有了极大提高,但是研究进入新的瓶颈期,文章发表的数量减少。由此可以看出,研究成果与研究年限存在一种阶段性的线性关系。这个基础期的结点、瓶颈期的起点就像“门槛”一样把研究阶段分成三个部分,在不同部分,成果和时间的线性关系都不同。这个效应被称为门槛效应或门限效应。 门限效应,是指当一个经济参数达到特定的数值后,引起另外一个经济参数发生突然转向其它发展形式的现象。作为原因现象的临界值称为门限值。在上面的例子中,成果和时间存在非线性关系,但是在每个阶段是线性关系。有些人将这样的模型称为门槛模型,或者门限模型。如果模型的研究对象包含多个个体多个年度,那么就是门限面板模型。 汉森(Bruce E. Hansen)在门限回归模型上做出了很多贡献。了解门限模型最好的办法,首先就要阅读他的文章。他的文章很有特点:条理很清晰,推导过程详细,语言简练,语法不复杂。有关他的论文、程序、数据可以参考Hansen的个人网站: https://www.sodocs.net/doc/4e2235130.html,/~bhansen/progs/progs_subject.htm。 Hansen于1996年在《Econometrica》上发表文章《Inference when a nuisance parameter is not identified under the null hypothesis》,提出了时间序列门限自回归模型(TAR)的估计和检验。之后,他在门限模型上连续追踪,发表了几篇经典文章,尤其是1999年的《Threshold effects in non-dynamic panels: Estimation, testing and inference》,2000年的《Sample splitting and threshold estimation》和2004年与他人合作的《Instrumental Variable Estimation of a Threshold Model》。 在这些文章中,Hansen介绍了包含个体固定效应的静态平衡面板数据门限回归模型,阐述了计量分析方法。方法方面,首先要通过减去时间均值方程,消除个体固定效应,然后再利用OLS(最小二乘法)进行系数估计。如果样本数量有限,那么可以使用自举法(Bootstrap)重复抽取样本,提高门限效应的显著性检验效率。 在Hansen(1999)的模型中,解释变量中不能包含内生解释变量,无法扩展应用领域。Caner和Hansen在2004年解决了这个问题。他们研究了带有内生变量和一个外生门限变量的面板门限模型。与静态面板数据门限回归模型有所不同,在含有内生解释变量的面板数据门限回归模型中,需要利用简化型对内生变量进行一定的处理,然后用2SLS(两阶段最小二乘法)或者GMM(广义矩估计)对参数进行估计。 当然,有关门限回归模型的最新研究,还可以参考《Inflation and Growth: New Evidence From a Dynamic Panel Threshold Analysis》(Stephanie Kremer,Alexander Bick,Dieter Nautz,2009)。 二、计量模型的假设、估计和检验 略
5分钟搞定Stata面板数据分析小教程
5分钟搞定Stata面板数据分析 简易教程 步骤一:导入数据 口令:insheet u sing 文件路径 例如:insheet u sing C:\STUDY\paper\taxi.csv 其中csv格式可用excel的“另存为”导出 数据请以时间(1999,2000,2001 )为横轴,样本名(1,2,3 )为纵轴 请注意:表中不能有中文字符,否则会出现错误。面板数据中不能有空值,没有数据的位置请以0代替。 如图: 也可直接将数据复制粘贴到stata的data e ditor中 如图:
步骤二:调整格式 首先请将代表样本的var1重命名 口令:rename v ar1 样本名 例如:rename v ar1 p rovince
也可直接在var1处双击,在弹出的窗口中修 改: 接下来将数据转化为面板数据的格式 口令:reshape l ong v ar, i(样本名) 例如:reshape l ong v ar, i(province) 其中var代表的是所有的年份(var2,var3,var4 ) 转化后的格式如图:
转化成功后继续重命名,其中_j 这里代表原始表中的年份,var代表该变量的名称 口令例如: rename _j y ear rename v ar t axi 也可直接在需要修改的名称处双击,在弹出的窗口中修改 如图:
步骤三:排序 口令:sort 变量名 例如:sort p rovince y ear 意思为将province按升序排列,然后再根据排好的province数列排year这一列 如图:
面板数据的常见处理
面板数据的常见处理 (2012-03-02 11:16:14) 标签: 在写论文时经常碰见一些即是时间序列又是截面的数据,比如分析1999-2010的公司盈余管 如上图所示的数据即为面板数据。显然面板数据是三维的,而时间序列数据和截面数据都是二维的,把面板数据当成时间序列数据或者截面数据来处理都是不合适的。 处理面板数据的软件较多,一般使用、Stata等。个人推荐使用Stata,因为Stata比较适合处理面板数据,且个性化强。以下以为例来讲解怎么样处理面板数据。 由于面板数据的存储结构与我们通常使用的存储结构不太一样,所在统计分析前,最好在excel中整理一下数据,形成如下图所示的数据
变量定义及输入数据 启动,Stata界面有4个组成部分,Review(在左上角)、Variables(左下角)、输出窗口(在右上角)、Command(右下角)。首先定义变量,可以输入命令,也可以通过点击Data----Create new Variable or change variable。 特别注意,这里要定义的变量除了因素1、因素2、……因素6、盈余管理影响程度等,还要定义年份和公司名称两个变量,这两个变量的数据类型(Type)最好设置为int(整型),公司名称不要使用中文名称或者字母等,用数字代替。定义好变量之后可以输入数据了。数据可以直接导入(File-Import),也可以手工录入或者复制粘贴(Data-Data Edit(Browse)),手工录入数据和在excel中的操作一样。 以上面说的为例,定义变量year、company、factor1、factor2、factor3、factor4、factor5、factor6、DA。 变量company 和year分别为截面变量和时间变量。显然,通过这两个变量我们可以非常清楚地确定panel data 的数据存储格式。因此,在使用STATA 估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset,命令为: tsset company year 输出窗口将输出相应结果。 由于面板数据本身兼具截面数据和时间序列二者的特性,所以对时间序列进行操作的运算同样可以应用到面板数据身上。这一点在处理某些数据时显得非常方便。如,对于上述数据,我们想产生一个新的变量Lag _factor1 ,也就是factor1 的一阶滞后,那么我们可以采用如下命令: gen Lag_factor1= 统计描述: 在正式进行模型的估计之前,我们必须对样本的基本分布特性有一个总体的了解。对于面板数据而言,我们至少要知道我们的数据中有多少个截面(个体) ,每个截面上有多少个观察期间,整个数据结构是平行的还是非平行的。进一步地,我们还要知道主要变量的样本均值、标准差、最大值、最小值等情况。这些都可以通过以下三个命令来完成:xtdes命令用于初步了解数据的大体分布状况,我们可以知道数据中含有多少个截面,最大和最小的时间跨度是多少。在某些要求使用平行面板数据的情况下,我们可以采用该命令来诊断处理后的数据是否为平行数据。Xtsum用来查询对组内、组间、整体计算各个变量的基本统计量(如均值、方差等)。为了方便,以下的举例都只用factor1,factor2两个自变量。 xtdes DA factor1 facto2
STATA面板数据模型操作命令
S T A T A面板数据模型 操作命令 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
S T A T A 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令 εαβit ++=x y it i it 固定效应模型 εαμit +=it it 随机效应模型 (一)数据处理 输入数据 ●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构 ●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析) ●gen lag_y= αi αi αi εit ~e it ~1-t e i ,8858.0~=θ5.0-~=θ验:是否存在门槛效应 混合面板: reg is lfr lfr2 hc open psra tp gr,vce(cluster sf) 固定效应、随机效应模型 xtreg is lfr lfr2 hc open psra tp gr,fe est store fe xtreg is lfr lfr2 hc open psra tp gr,re est store re hausman fe 两步系统GMM 模型 xtdpdsys rlt plf1 nai efd op ew ig ,lags(1) maxldep(2) twostep artests(2) 注:rlt 为被解释变量,“plf1 nai efd op ew ig ”为解释变量和控制变量;
maxldep(2)表示使用被解释变量的两个滞后值为工具变量;pre()表示以某一个变量为前定解释变量;endogenous()表示以某一个变量为内生解释变量。 自相关检验:estat abond 萨甘检验:estat sargan 差分GMM模型 Xtabond rlt plf1 nai efd op ew ig ,lags(1) twostep artests(2) 内生:该解释变量的取值是(一定程度上)由模型决定的。内生变量将违背解释变量与误差项不相关的经典假设,因而内生性问题是计量模型的大敌,可能造成系数估计值的非一致性和偏误; 外生:该解释变量的取值是(完全)由模型以外的因素决定的。外生解释变量与误差项完全无关,不论是当期,还是滞后期。 前定:该解释变量的取值与当期误差项无关,但可能与滞后期误差项相关。
Stata面板回归操作过程、基本指令及概要
Stata面板回归操作过程、基本指令及概要 在使用Stata过程中,录入面板数据后,一般需要对初始数据进行识别,因此需要首先进行面板数据的识别,其指令为: 1.面板数据识别指令: tsset region year 案例: ②部分初始数据 录入数据操作为:
②将上述初始数据录入stata后(注意:录入数据及首行只能是英文 字母或者数字,不能有汉字),显示如下: ③输入指令tsset region year,显示如下结果 . tsset region year panel variable: region (strongly balanced) time variable: year, 2005 to 2014 delta: 1 unit 2.面板数据固定效应回归指令: xtregy erseqs x1 x2 x3 x4 x5,fe 案例: 录入数据,并进行面板数据识别之后,输入以上指令: xtregy erseqs x1 x2 x3 x4 x5,fe 其中,xtreg为面板回归指令,y为选取的因变量,ers、eqs、x1、x2、x3、x4、x5为自变量,末尾加fe表示为固定效应,如果末尾加re则是随机效应。上述回归结果显示如下:
3.面板数据随机效应回归指令: xtregy erseqs x1 x2 x3 x4 x5,re 4.hausman 检验指令: Hausman检验是固定效应或者随机效应回归之后,需要加入的一个检验,具体指令如下: quixtregy erseqs x1 x2 x3 x4 x5,fe est store fe quixtregy erseqs x1 x2 x3 x4 x5,fe est store re hausmanfe re 5.门限回归指令
5分钟搞定Stata面板数据分析
【原创】5分钟搞定Stata面板数据分析简易教程ver2.0作者:张达 5分钟搞定Stata面板数据分析 简易教程 步骤一:导入数据 原始表如下, 数据请以时间(1998,1999,2000,2001??)为横轴,样本名(北京,天津,河北??)为纵轴 将中文地名替换为数字。
注意:表中不能有中文字符,否则会出现错误。面板数据中不能有空值。 去除年份的一行,将其余部分复制到stata的data editor中,或保存为csv格式。
打开stata,调用数据。 方法一:直接复制到data editor中。 方法二:使用口令:insheet using 文件路径 调用例如:insheet using C:\STUDY\paper\taxi.csv 其中csv格式可用excel的“另存为”导出 如图:
步骤二:调整格式 首先请将代表样本的var1重命名 口令:rename var1 样本名 例如:rename var1 province 也可直接在var1处双击,在弹出的窗口中修改:
接下来将数据转化为面板数据的格式 口令:reshape long var, i(样本名) 例如:reshape long var, i(province) 其中var代表的是所有的年份(var2,var3,var4??) 转化后的格式如图: 转化成功后继续重命名,其中_j 这里代表原始表中的年份,var代表该变量的名称口令例如: rename _j year rename var taxi 也可直接在需要修改的名称处双击,在弹出的窗口中修改 如图:
STATA面板数据模型操作命令
S T A T A 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令 εαβit ++=x y it i it 固定效应模型 εαμit +=it it 随机效应模型 (一)数据处理 输入数据 ●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构 ●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析) ●gen lag_y=L.y /////// 产生一个滞后一期的新变量 gen F_y=F.y /////// 产生一个超前项的新变量 gen D_y=D.y /////// 产生一个一阶差分的新变量 gen D2_y=D2.y /////// 产生一个二阶差分的新变量 (二)模型的筛选和检验 ●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS 混合模型) ●xtreg sq cpi unem g se5 ln,fe 对于固定效应模型而言,回归结果中最后一行汇报的F 统计量便在于检验所有的个体效应整体上显着。在我们这个例子中发现F 统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS 模型。 ●2、检验时间效应(混合效应还是随机效应)(检验方法:LM 统计量) (原假设:使用OLS 混合模型) ●qui xtreg sq cpi unem g se5 ln,re (加上“qui ”之后第一幅图将不会呈现) xttest0 可以看出,LM 检验得到的P 值为0.0000,表明随机效应非常显着。可见,随机效应
模型也优于混合OLS模型。 ●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验) 原假设:使用随机效应模型(个体效应与解释变量无关) 通过上面分析,可以发现当模型加入了个体效应的时候,将显着优于截距项为常数假设条件下的混合OLS模型。但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下: Step1:估计固定效应模型,存储估计结果 Step2:估计随机效应模型,存储估计结果 Step3:进行Hausman检验 ●qui xtreg sq cpi unem g se5 ln,fe est store fe qui xtreg sq cpi unem g se5 ln,re est store re hausman fe (或者更优的是hausman fe,sigmamore/ sigmaless) 可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。此时,需要采用工具变量法和是使用固定效应模型。 (三)静态面板数据模型估计 ●1、固定效应模型估计 ●xtreg sq cpi unem g se5 ln,fe (如下图所示) 其中选项fe表明我们采用的是固定效应模型,表头部分的前两行呈现了模型的估计方法、界面变量的名称(id)、以及估计中使用的样本数目和个体的数目。第3行到第5行列示了模型的拟合优度、分为组内、组间和样本总体三个层面,通常情况下,关注的是组内(within),第6行和第7行分别列示了针对模型中所有非常数变量执行联合检验得到的F统计量和相应的P值,可以看出,参数整体上相当显着。 需要注意的是,表中最后一行列示了检验固定效应是否显着的F统计量和相应的P值。显然,本例中固定效应非常显着。 ●2、随机效应模型估计
面板数据的常见处理
面板数据的常见处理(2012-03-02 11:16:14) 标签: 杂谈
数据了。数据可以直接导入(File-Import),也可以手工录入或者复制粘贴(Data-Data Edit(Browse)),手工录入数据和在excel中的操作一样。 以上面说的为例,定义变量 year、 company、 factor1、 factor2、 factor3、factor4、 factor5、 factor6、 DA。 变量company 和year分别为截面变量和时间变量。显然,通过这两个变量我们可以非常清楚地确定panel data 的数据存储格式。因此,在使用STATA 估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset,命令为:tsset company year 输出窗口将输出相应结果。 由于面板数据本身兼具截面数据和时间序列二者的特性,所以对时间序列进行操作的运算同样可以应用到面板数据身上。这一点在处理某些数据时显得非常方便。如,对于上述数据,我们想产生一个新的变量Lag _factor1 ,也就是factor1 的一阶滞后,那么我们可以采用如下命令: gen Lag_factor1= 统计描述: 在正式进行模型的估计之前,我们必须对样本的基本分布特性有一个总体的了解。对于面板数据而言,我们至少要知道我们的数据中有多少个截面(个体) ,每个截面上有多少个观察期间,整个数据结构是平行的还是非平行的。进一步地,我们还要知道主要变量的样本均值、标准差、最大值、最小值等情况。这些都可以通过以下三个命令来完成:xtdes命令用于初步了解数据的大体分布状况,我们可以知道数据中含有多少个截面,最大和最小的时间跨度是多少。在某些要求使用平行面板数据的情况下,我们可以采用该命令来诊断处理后的数据是否为平行数据。Xtsum用来查询对组内、组间、整体计算各个变量的基本统计量(如均值、方差等)。为了方便,以下的举例都只用factor1,factor2两个自变量。 xtdes DA factor1 facto2 xtsum DA factor1 facto2 模型回归。 常用的处理面板数据的模型有混合OLS模型、固定效应模型、随机效应模型。各个模型的区别请上网查查。下面说说各个模型的命令: 混合OLS模型输入命令: regress DA factor1 facto2 固定效应模型输入命令: xtreg DA factor1 factor , fe 随机效应模型输入命令: xtreg DA factor1 factor , re 模型的选择及检验 固定效应模型要检验个体效应的显著性,这可以通过固定效应模型回归结果的最后一行的F统计量看出,F越大越好,可以得出固定效应模型优于混合OLS模型的结论。随机效应模型要检验随机效应是否显著,要输入命令:
相关文档
- 5分钟速学stata面板数据回归(初学者超实用!)
- 5分钟搞定Stata面板数据分析小教程
- STATA面板数据模型操作命令
- 面板数据的常见处理
- STATA面板数据模型操作命令要点
- STATA面板数据模型操作命令
- 课件-用stata做面板数据回归 - 副本
- Stata面板数据分析
- 5分钟搞定Stata面板数据分析小教程实用
- STATA面板数据模型操作命令剖析
- STATA面板数据模型操作命令
- stata面板数据连玉君
- STATA与面板数据回归
- STATA面板数据模型操作命令讲解
- 面板数据stata处理步骤介绍
- 面板数据的常见处理
- Stata 之面板数据处理—长面板
- 5分钟搞定Stata面板数据分析
- STATA面板数据模型操作命令
- stata处理面板数据及修正命令集合